Do not recommend: User Provided Primary Keys - 2022-02-18
If you have a primary key or unique index that is stored and exchanged as just a bunch of characters, but your code interprets it in a structured way, you may soon find out you have a problem.
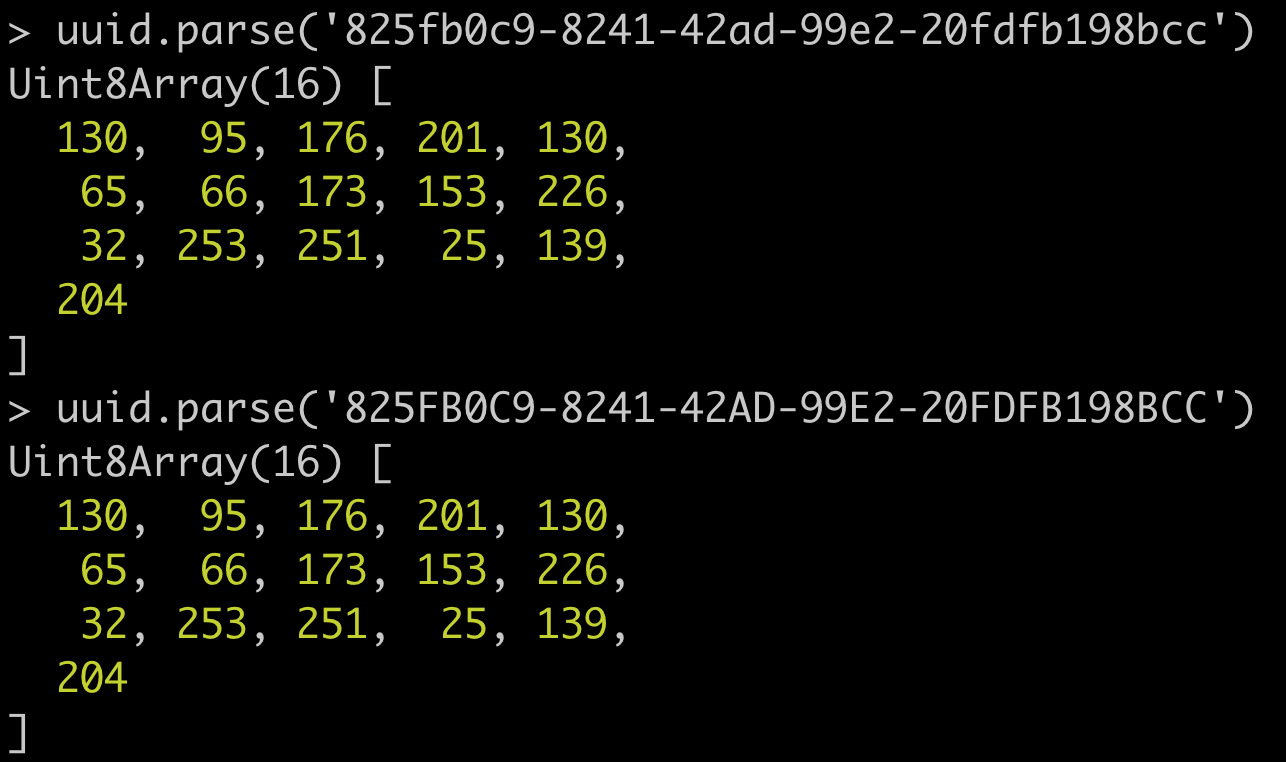
Do you use a UUID as a primary key for your entities? Did you use a regex to verify the data looks like a uuid before putting it into the database? Is your database (like sqlite) using a case sensitive collation for the column? Then you have a problem. And it can stem from something as simple as casing! It begins with trusting non-canonical data to be equatable, where multiple inputs have a single interpretation (which can be equated).
Canonical Forms
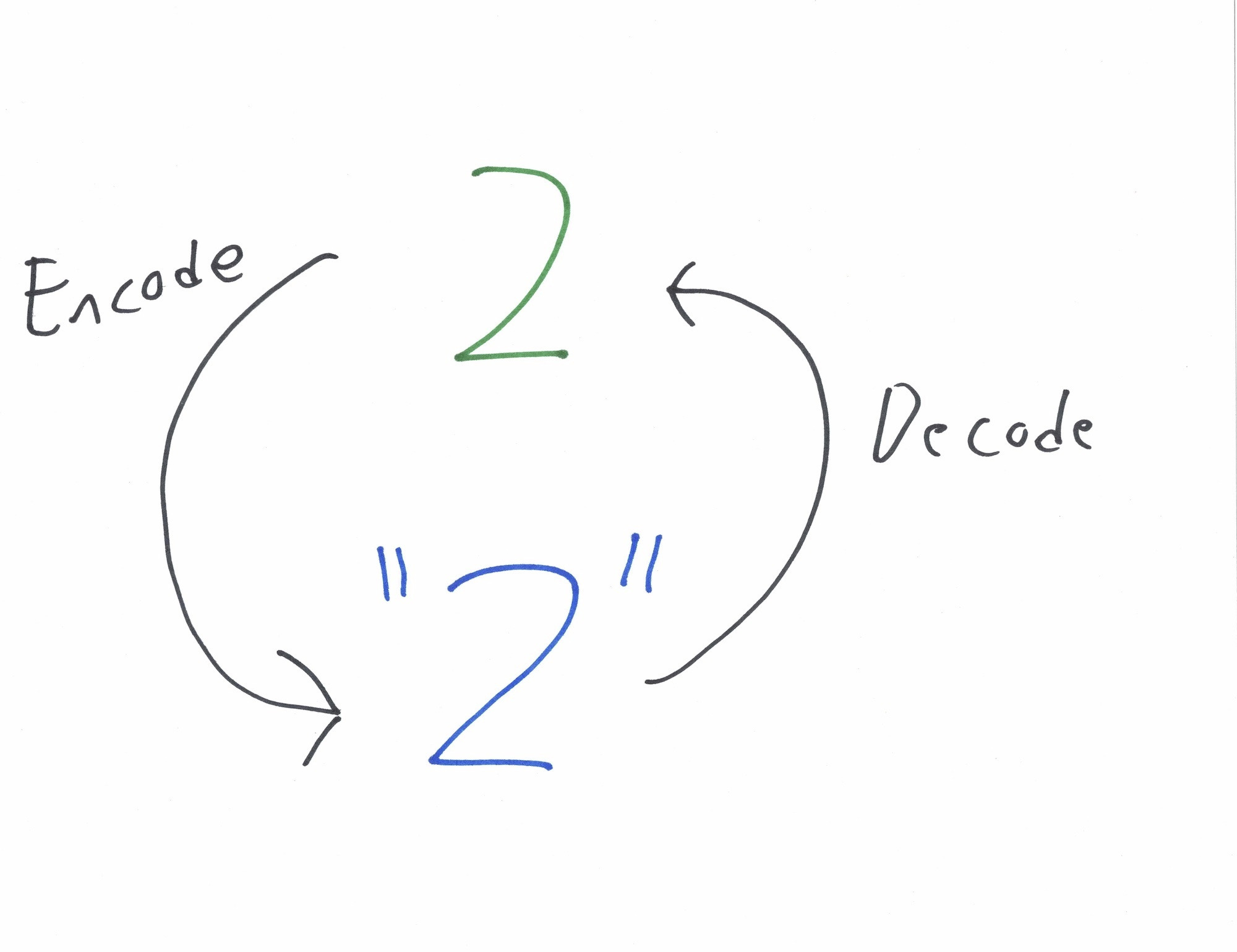
The process of conforming your data to a canonical form is Canonicalization, that is input data is forced to be output in the form that can be considered unique and any copies can be safely equated.

Consider the above diagram, the number 2 could be parsed from several numbers, such as "002", "02", and "2". Note that the numeric encoding of 2 is "2", and decoding "2" is 2.
When the means of communicating, interpreting, and communicating the interpreted value results in the same literal value (what is being communicated), then you have your de-facto canonical form in the eyes of your application.
This problem or feature is tied to parsing and that is not just limited to when strings are passed between functions, processes, servers, and so on. It is a part of the very languages you use to deliver something useful.
You might eye roll and say what's the harm? Multiple encodings are actually helpful in many circumstances. Suppose you're at a restaurant and someone in the middle of the table says they need to get up and use the "bathroom". You know they mean the facilities labeled "restroom", a place with toilets. This individual is not going to bathe despite using the word "bathroom", because the facilities do not afford that option. Those facilities do afford the option to use toilets and wash hands.
In a way, authorization is linked to affordances. An attestation of authorization affords the bearer of the attestation to do something (usually). When you say you're going to do something you are conveying intent or a command. Often untrusted inputs should be treated as intents rather than commands, while trusted inputs are then evaluated as commands.
One time while driving in Kansas, I stopped at a gas station and filled up. But in order to afford access to the rest room, I had to ask for a key at the cashier. I received a PVC pipe with a key strung on the end. Is this normal in Kansas?
When we talk as humans we can distinguish meanings and decide equivalences with confidence. But machines do not have this skill. Machines cannot easily differentiate and equate things that require interpretation.
Instead machines can compare bytes quite easily. But the moment something inside those bytes need to be understood or interpreted, a parser is needed to transform those bytes into something structured and useful. Those structures can be compared or equated too, usually. But the danger here is when the same structures can be parsed from different data. In sensitive security contexts the bytes themselves are compared as-is. There are cases where bytes are dynamically fed into a digest algorithm, but we will get to that later.
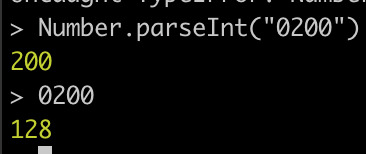
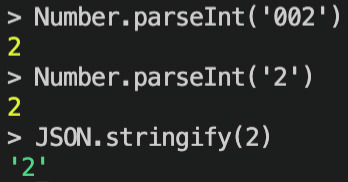
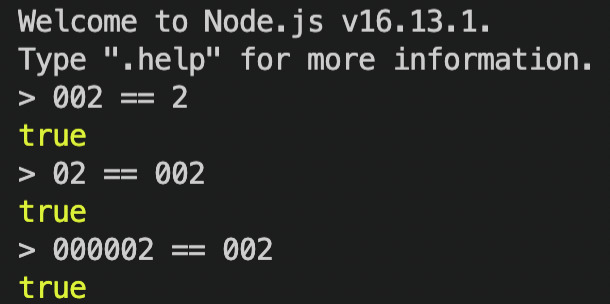
For multiple contexts an input can be a string of digits and the result for each context can be an integer in memory. Yet those integers in memory can be wildly different within the same language.
Number.parseInt("0200") may be meant to parse human input while 0200 in source code is traditionally an octal representation due to the leading 0. It turns out different parsers are used in node.js and this creates ambiguity for the very developer making something with it. Did they think their numbers would be parsed as decimal or as octal?
To resolve ambiguity we create specifications and when the bytes that are being compared need to have only one possible encoding for equivalence then it is a canonicalization specification.
Why only one possible encoding is important for security contexts will come later.De-facto vs Specified Canonicalization
As described above, de-facto is how the existing application is working at this moment. While you can retroactively specify its behavior for compatibility later, until you ensure that inputs can only map to one interpretation, you may continue to face issues that come from non-canonical encodings in sensitive contexts.
When creating and specifying a canonical encoding there's a few traps to be wary of.
- When concatenating multiple values together which come from an untrusted source, include delimiters that encode the length of what is concatenated. More on this type of attack can be seen on Canonicalization Attacks Against MACs and Signatures by Sparkling, blue, wolf-like creature: Soatok, Dhole.
- When concatenating entries of a map, set, or any unordered structure, ensure that elements are deterministically added to the canonical output.
- Be cautious around parsing maps or dictionaries, entries can be added multiple times and be syntactically valid (in JSON or XML) but parsers may take the first or last value. Consider using parsers that reject input with duplicate keys.
- I recommend using vectors of elements, if an element is optional put a placeholder value when it is absent.
- All instances of a type of thing should use the same encoding. For example, do not mix base64 standard padded and base64 standard unpadded or just plain binary.
When encodings for the same thing get mixed up, you enter a new class of problems which comes next!
Specifying Primary Keys
Let's say you are working with UUID keys, UUIDs in upper case and lower case are both accepted by UUID parsers. Also that your data store where these are primary keys is case sensitive and not using an embedded structured type. If you use an embedded type like PostgreSQL UUID everywhere, then this is not an issue for you.
But if that's not possible or not feasible... What if you only accept UUIDs with lower case, no mixed or upper case?
// re is a regex object that matches UUID looking things in lower case.
let re = /[a-f0-9]{8}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{12}/;
--------------------------v--------------
> !!'825fb0c9-8241-42ad-99E2-20fdfb198bcc'.match(re)
--------------------------^--------------
false
--------vv-v---------vv---v----vvvv---vvv
> !!'825FB0C9-8241-42AD-99E2-20FDFB198BCC'.match(re)
--------^^-^---------^^---^----^^^^---^^^
false
-----------------------------------------
> !!'825fb0c9-8241-42ad-99e2-20fdfb198bcc'.match(re)
-----------------------------------------
trueRegex is often the first line of defense to things like this. But not everything will fit or be expressable as a regex.
What if you transform the input into a canonical form (all lower case)? Be careful! Spotify documented their difficulty on transforming usernames! (Archive link) If your transform function is not idempotent then it is not safe to use where equivalence is important.
Idempotency is that the operation can be run multiple times without a net change. Here the transformation is on an input string to an output string. It should be safe to run this type of transformation on an indexed key. For example if you run toLowerCase() on a valid UUID then running it again will have no change in representation, as the alphabet used [a-f0-9] has no further lower case forms like Spotify's experience.
Here's Spotify's example:
>>> canonical_username(u'\u1d2e\u1d35\u1d33\u1d2e\u1d35\u1d3f\u1d30')
u'BIGBIRD'
>>> canonical_username(canonical_username(u'\u1d2e\u1d35\u1d33\u1d2e\u1d35\u1d3f\u1d30'))
u'bigbird'Their canonical function failed their use case because it was not idempotent. The input and output could be transformed again into another unique output which demonstrated multiple interpretations for the 'bigbird' text.
While toLowerCase() works for this trivial example, your application may not be as trivial.
> !!'825fb0c9-8241-42ad-99e2-20fdfb198bcc'.match(re)
true
> !!'825FB0C9-8241-42AD-99E2-20FDFB198BCC'.toLowerCase().match(re)
trueRejecting input that does not meet expectations on canonical value is often the safer choice with regards to security. But like Spotify's case, a balance has to be made for human user experience. In the end Spotify chose to do both: transform the input so the human experienced case insensitive usernames and reject names which could not be properly canonicalized without looping.
Base64 Primary Keys
Here's an example by @CiPHPerCoder but in node js for consistency of this post.
> Buffer.from('PHP', 'base64').toString('base64')
'PHM='
> Buffer.from('PHM=', 'base64')
<Buffer 3c 73>
> Buffer.from([0x3c, 0x73]).toString('base64url')
'PHM'The canonical encoding for the bytes [0x3c, 0x73] is 'PHM=' in base64 standard with padding. While the canonical encoding in base64 url without padding is 'PHM'.
Standard and URL encoding both have padded and unpadded variants, totalling 4 options. Most users of node.js use either standard padded or url safe unpadded encoding. URL encoding swaps two characters so the encoded contents can be embedded in urls and headers.
Many libraries, languages, environments will give you a non-strict base64 implementation. Below is an example of how the same bytes can look so wildly different encoded in different variants, but be decoded in the other variant without rejection.
> Buffer.from([0xff, 0xef]).toString('base64')
'/+8='
> Buffer.from([0xff, 0xef]).toString('base64url')
'_-8'
> Buffer.from('/+8=', 'base64url')
<Buffer ff ef>
> Buffer.from('_-8', 'base64')
<Buffer ff ef>
> Buffer.from('/+8', 'base64url')
<Buffer ff ef>
> Buffer.from('_-8=', 'base64')
<Buffer ff ef>Most developers would see this as a feature, and I agree it's nice to know it's base64 and not mind which variant it is with or without padding and move on in making something useful.
I wrote a base64 implementation in C for a lisp language. It was intentionally designed to be fast with lookup tables while supporting both web and standard encoding with or without padding with ease. This might not be the best thing to have due to padding and variant malleability.
But the issue here is... like UUID's what if you stored these as primary keys in the database as strings? What if you used them where uniqueness or identity matters?
What if a developer thought: for performance reasons there's no need to re-encode some base64, I already have the base64 value as a string and have a proof of equivalence when decoded, so I can safely store the user supplied base64 value in this table?
This sounds a lot like Cross Site Scripting doesn't it? Here untrusted input is persisted into the system and later used in a trusted context. While it does not affect the browser with scripting, the context is sensitive and this provides an attack vector to accessing another user.
Here's an example where it can go wrong, let us assume the target and the adversary do not have control over how IDs are assigned. The ID might be random or it could be deterministically created.
For example, UUIDv3 contains an MD5 hash (which is broken) of some input with a namespace. That namespace could be secret to the application so users could not reasonably create their own. But if case sensitivity were present and it was loaded into a UUID object, then what is described below still applies. UUIDv5 isn't much better, it uses SHA-1, which is also cryptographically broken.
Here it will be a base64 string based on some deterministic process.
> crypto = require('crypto')
> crypto.createHash('md5').update('[email protected]').digest('base64')
'+pgA3ruPzUGkJjBltX/Lkw=='Don't use md5 for cryptographic purposes anymore, this is merely for a deterministic demonstration which you can run yourself.
Suppose the user table uses bytes to store the user id, but someone else made the password reset table and it uses a string for the user id instead. This difference of encodings enables the example below to be attacked.
Further, assume the encoded user id can be used elsewhere (e.g. email) to continue the attack.
Consider logic like this:
void forgotPassword(){
userId = param["id"];
user = Users.get(Buffer.from(userId, "base64"));
if (user != null) {
token = ForgetPassword.requestNewPassword(userId);
Email.send(userId + "@example.org",
"here you go " + token);
}
}
void resetPassword() {
token = param["token"];
forgot = ForgotPassword.find(token);
if (forgot != null) {
userId = forgot.userId;
user = Users.get(Buffer.from(userId, "base64"));
user.setPassword(param["new_password"]);
}
}Given that we can successfully equate the same user id with different encodings, and the encoded value is stored as is without validation:
> Buffer.from('+pgA3ruPzUGkJjBltX/Lkw==', 'base64').equals(Buffer.from('+pgA3ruPzUGkJjBltX/Lkz', 'base64'))
trueThe workflow above is vulnerable to an attack by someone if they can somehow get access to another email address with the non-canonical base64 user id. In fact, this example can be minimized. Just the padding (==) can be removed, I did not even need to change the 'w' on the end to a 'z'.
Is this a canonicalization attack? What name really describes this best? In short the attack relies upon breaking uniqueness expectations where values are equal when interpreted or transformed.
Some mitigations:
- Use strict decoders everywhere.
- Encode again and reject input where it differs.
- Update this code to use the user id on the user record instead of the user input once loaded when emailing.
- Migrate the forgot password table and code to use the same binary encoding as the user table.
- Don't assume properties of the system that involve concatenating untrusted user input with system constants. Instead have a field for email addresses on the user and refer to that when emailing.
- Use value objects to represent trusted validated structured information in context.
Canonicalization attacks
If you search this you may find stuff about file system traversal. How is it related? It is actually quite close in concept to the example above with emailing: do not concatenate user input with system constants and hope all will be well.
See, multiple input paths turn out to be the same output path in the file system:
cd /usr/share/gcc/python/libstdcxx/v6/../../../../misc
pwd
> /usr/share/misc
cd /usr/share/misc
pwd
> /usr/share/miscDo you see how multiple inputs have the same output? The same interpretation (the final present working directory) came from multiple paths. Canonicalization is part of this attack because the encoding and intent and context are not aligned. What if the application expected that all file system access ocurred within a given path? For example suppose uploading images could only be done in /usr/share/gcc/python/libstdcxx/v6/ but the application accidentally allowed for overwriting /usr/bin/sudo because the file name was ../../../../../bin/sudo in the upload form? That's quite dangerous.
Canonicalization for Cryptographic contexts
In cryptographic contexts, hash functions are used where if any bit of the input were different, the output would be unrecognizably different. A signature on a hash function's output or a keyed hash provides data integrity of the contents signed. Any modification to the content would therefore invalidate the signature.
Typically content of just bytes is encrypted or signed where integrity (modification is detected and rejected) is desired and required. Protocols that involve the following are typically sound in construction:
- Structured content is canonicalized at encoding time.
- Encoded content has cryptographic integrity protection.
- The package of encoded content with integrity protection is never disassembled and reassembled later.
Dynamic Canonicalization
But alas, we have protocols like SAML which is insecure by design. The key part that makes it insecure goes back to that problem where Number.parseInt("0200") can differ from 200. There will be different parsers for different contexts and by authors who do not collaborate with quirks and unique behaviors on anything as complex as Canonical XML. Canonical XML is a dynamic canonicalization solution with many faults, which will be cited later.
What makes those protocols fragile is how secured content is disassembled and reassembled later, even multiple times. The encoded data which is used by the application is not protected for the application because it is mutable between the signer and the audience or intended recipient. Instead it is left to the application to be diligent about handling mutable data with dynamic canonicalization. This isn't just about attacks on XML though, equating structures is just inherently a hard problem: solutions have been proposed for JSON, CBOR, and even HTTP!
Now I get it, HTTP requests are literally received, modified, rewritten, reorganized, etc. between load balancers and applications. There is no concept of nesting an HTTP request and its properties, it is all flat. So what do you do when somewhere in the middle an insensitive header will be added or removed, that sensitive headers are reorganized but the reorganization has no change or net effect to application behavior?
Unfortunately the solution is usually constraining or inventing a new specification which can then be used to deterministically encode a request to a canonical byte form, which is then signed or encrypted. But... this canonical form is often not used by the application. Instead it is used to filter requests without modifying the request with respect to how the application receives it.
This is effectively what AWS SigV4 did. Unfortunately, even SigV4 differs between services within AWS. Specifically S3 has its own special variant. In case it interests you, others like google have their own version too!
Outside of Amazon's specific needs, the vibes for HTTP Canonicalization with a holistic approach are not all that great. You can explain it, and it makes sense, but it does not feel clean.
Dynamic canonicalization often does not feed the canonical result into the application. Instead it is calculated, used, and discarded. It may not even be fully allocated either because outputs can be incrementally fed into a digest algorithm, and then finally verified against a signature.
This is a bit of a trick too, how can you sign something that is dynamic so that it has only one possible encoding? A requirement for digital signatures is deterministic verification. Canonicalization is used to create a deterministic output as an input to the signature process by reorganizing all the information in a deterministic way. But as mentioned before, if the application treats the input differently and there are things that can be tweaked to appear the same to the canonicalization process, then your implementation is vulnerable.
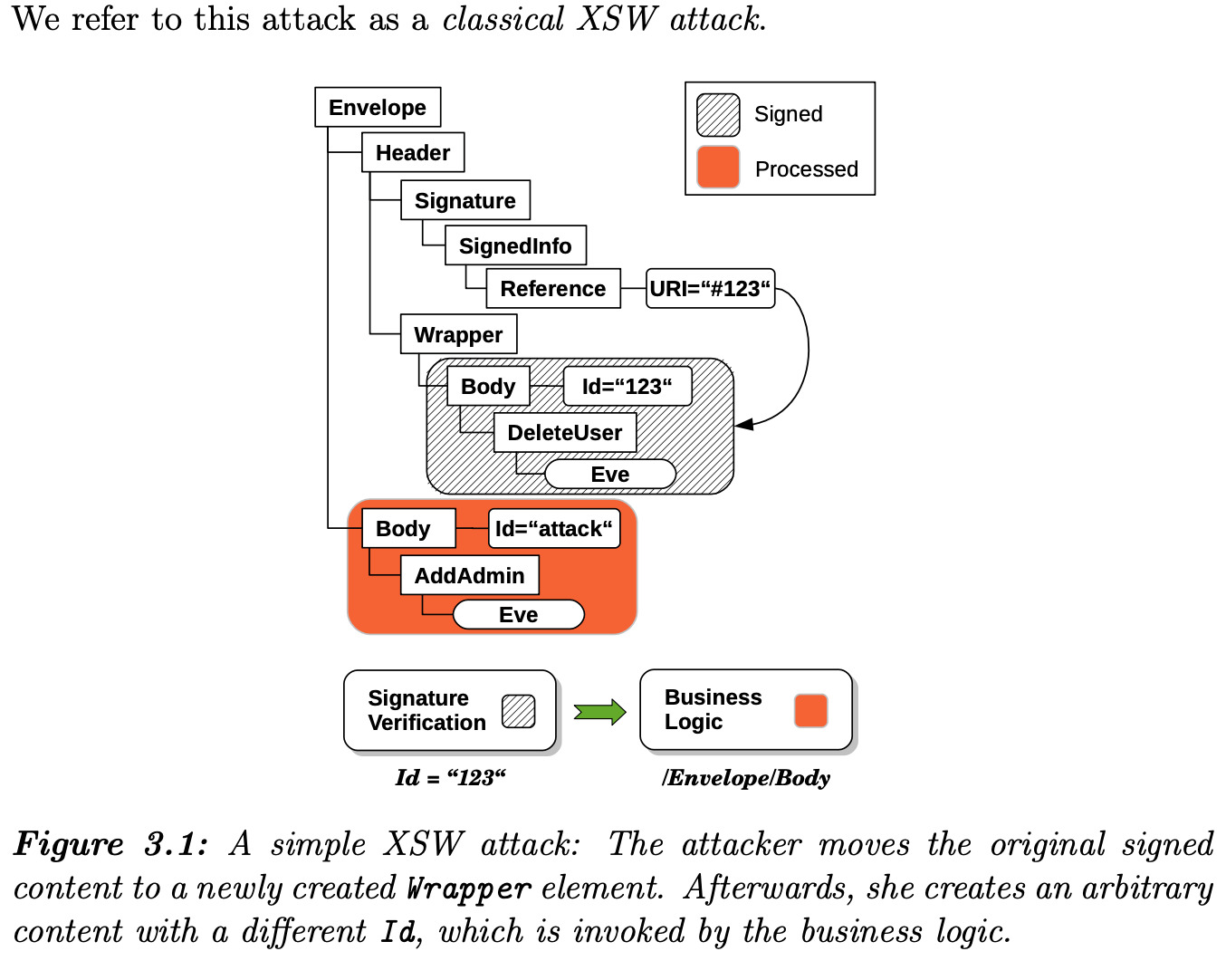
Protocols that use dynamic canonicalization have decreased confidence among cryptographers. This is one of many reasons SAML has a bad reputation.
If you would like to read about this subject see: Somorovsky, Juraj. "On the insecurity of XML Security" it - Information Technology, vol. 56, no. 6, 2014, pp. 313-317.
https://doi.org/10.1515/itit-2014-1045There is a PDF out there that you can download if you search hard enough.
Mismatch between Application and Security
Here's the rub. You can create a canonical form, you can sign it, and it is valid, but what if your application never uses the canonical form? Such as the dynamic canonicalization case.
Consider this input
{
"username": "Alice",
"username": "Bob",
"scope": "prod"
}What if your signing process treated it as this when it signed it
{
"scope": "prod",
"username": "Alice"
}But your application treats it as this?
{
"scope": "prod",
"username": "Bob"
}Some say to just give the canonical form to the application instead, that is what is secured.
But when it comes to XML, JSON, or whatever--guess what?
The application and the security library may be using different incompatible structured interfaces! Maybe the security library uses GSON and the application uses Jackson. Or even different versions of the same library! This is a real problem.
Try importing a few SOAP SDKs some time and find out how many XML parsers are brought into your project and figure out how to keep them from colliding.
What can you do about Canonicalization?
Move to using typed values over strings from users. Particularly if the value has some sensitive meaning like username. It may be a string inside but the context has additional rules (like case insensitivity) that make is safer to use. By scoping and conforming the input to the domain and context with a value object will ensure that input meets expectations and storing will only have one representation for that context.
Your typed values should reject input during deserialization / parsing when input appears non canonical, or at least transform (i.e. lowercase uuid) and then reject if the transform is not idempotent. (Recall Spotify's difficulty.)
Consider rejecting inputs that may force canonicalization like directory traversal.
My recommendation: never allow user input to touch the file system. Use generated names on the file system, use encoded hashes, just never user input. Do you want your urls to contain user input for nice names and for some reason you want emoji and unicode support? Consider some sort of origin request rewriting to a hash of the user input or use a service like S3 where it is not a path but a logical key.
Once user input is parsed and structured, throw it away. Only use the internal value or value object from then on. In fact, isolate parsing into value types from the business logic that acts on the values supplied from the user.
Avoid and migrate away from protocols that intermingle, nest, and mix sensitive data with insensitive data. When anything is sensitive, signed, encrypted, leave it alone as is and only let the audience or intended recipient deal with it (see "aud" on Active Directory id tokens).
If you're inventing your own protocol with bytes then encode with lists of fixed element length, if an element is optional use a placeholder for no value / null. You will be better off if you can also encode the length of the element before the element in your canonicalized output.
Also practice this stuff before you put it into production.
Inspiration for this article
A twitter user who wishes to remain unnamed reached out to me hinting at another possible way to misuse encoded base64. Further he hinted that an author with many cited papers will be publishing a study on how many libraries react to non-canonical base64 data.
Several of the concerns and ideas mentioned had already been covered in A base64 surprise. But one scenario stook out to me!
That is: abuse of an application through base64 primary keys, including padding removal or addition. This extends also to base64 malleability where padding bits are altered so the encoded form appears unique and different but the binary form is equivalent.
I have since gotten in contact with that author and eagerly await to see the paper's contents.
Update 2022-02-19
I got in contact with that author and reviewed the paper with some feedback.
Oh cool! I haven't done anything like this in 9 years! The last time I got to be listed as a technical editor on a C++ book.
from Hacker News https://ift.tt/tHqf4sY
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.