You have probably heard about the Raspberry Pi. It’s a nice little affordable single-board computer with a huge community using it for all sorts of projects.
I got my first Raspberry Pi, the Model B+, during my first year at university, which was around the winter of 2014/2015. The idea of a super tiny PC that could actually do useful things was just very fascinating to me, and I loved the way that green PCB looked.
Over the years, I’ve used that Pi and newer revisions of them in all sorts of use cases: a simple Kodi media box, a Minecraft server, a web server, retro game emulation box, and much more.
Because the goal of the Raspberry Pi was to be an affordable platform for experimentation and learning for everyone, they had to keep the costs down. This meant that the computing power that the Raspberry Pi 1 packed wasn’t much. With the Model B+, you get one ARM CPU core that you can overclock to 1 GHz, and 512MB of RAM. It wasn’t much even at the time of release, and it definitely isn’t great in 2022.
Due to the very limited performance, the use cases for a Raspberry Pi 1 are quite limited in 2022. Use cases that don’t require much computational power are often better solved by other platforms. Use cases that are actually useful to me and solve a problem I have are too much for the Pi 1. At the same time, I absolutely hate it when I have computing equipment sitting around on a shelf doing nothing. I can’t even sell this Pi, because it is not worth much any more and it has some sentimental value for me.
Taking all that into account, and looking at my parts box, I decided to give one idea a go: let’s build the slowest damn Syncthing backup endpoint imaginable.
The build
Here’s a quick rundown of the parts:
SBC: Raspberry Pi 1 Model B+
Storage (microSD): SanDisk 8GB that I had lying around
Storage (USB): Crucial BX500 1TB SATA 2.5" SSD, in an IcyBox USB-SATA enclosure
Power: official Raspberry Pi microUSB power adapter
Networking: TP-Link TL-WN722N USB WiFI adapter
OS: Raspberry Pi OS 32-bit (lite)
Acoustic foam: yes.
Alternate angle of the setup.
Use case: networked offsite backup of files that I cannot afford to lose, powered by Syncthing, btrfs as the filesystem, and btrbk as the snapshotting solution.
I set the OS up using the Raspberry Pi imager due to the useful options it offered, such as automatically setting my SSH public key authentication up. Once booted, I logged in and ran sudo apt update -y. I knew what to expect regarding performance, and was still surprised at how slow things have become. Updating the system and deploying the configuration using Ansible took hours.
The 1TB SSD is formatted as a btrfs file system and mounted to /storage. For the Syncthing service, I created a separate user syncthing with the home folder on /storage/home/syncthing. The synced data will live on /storage/syncthing. Keeping the home folder on the SSD is intentional: Syncthing keeps track of application state in a database and storing it on the microSD card will wear it out much faster. The database can also be quite big if you have a lot of files to sync.
I’m not going to go into the btrbk setup in much detail, but if you’re interested in that, then I do have a write-up about btrbk. Long story short: snapshots are cool, and they help prevent data loss in case of accidental deletions.
I set up Syncthing to allow access to the GUI from over the network by changing the ~/.config/syncthing/config.xml file while the service was stopped. Just change the GUI listen address to 0.0.0.0:8384, that will make the GUI accept connections not only from localhost, but from all machines on the same network. The next step was to set a password to the GUI and check the “Use HTTPS for GUI” box, because you probably don’t want any rando messing your machine up.
The choice to go with the WiFi for networking is related to the environment this system will eventually be deployed to. Ethernet isn’t an option there.
Once the system was all set up and files were syncing extremely slowly, I kept an eye on the Pi, especially the red power LED. I had set the CPU to run at 1 GHz using raspi-config, and with both the WiFi adapter and SSD connected, I had concerns that the Pi could not supply enough power. The power limitations of the Pi are a common source for issues and that has come up in the past as well, especially with external storage connected to the Pi. However, with this particular setup this has not been an issue so far. The fact that Pi is so underpowered that it cannot even make full use of the SSD is probably a contributing factor to the overall stability.
The file sync was very slow, but at least it was working. The typical transfer speeds hovered around 1.5 MB/s. Not great, but given the fact that this setup will operate in an environment where the download speeds are typically capped around 15-20 Mbit/s, this will be more than enough.
htop showing how much the Pi is struggling under operation.Typical transfer speed that I observed with the setup.
How well will this setup work over a longer time period? Only time will tell. Just like with other disastrous tests that I have done, I’ll try to update this post whenever anything noteworthy happens.
Does this setup make any sense if you need a performant Syncthing endpoint? Hell no. However, I’m very happy that this little Pi finally has a purpose.
Alternatives
This project was about finding a purpose for an SBC I already had lying around.
An Orange Pi Zero running Armbian was something I also considered, since I had one lying around, but it was a bit too competent for the job, and I might find a better use for it eventually.
If you wanted performance, then any x86-based PC will do just fine. My recommendation is to go for an used PC, be it a laptop or a very small and efficient PC. Just keep in mind that the power usage is typically higher on these setups compared to a small ARM-based single-board computer. If a machine runs 24/7, then the difference between 2-3 W and 10-20 W will start to matter, especially when energy prices are quite high in your region.
The war in Ukraine also affects the Internet administration. IP address managers report problems and fear that addresses will become spoils of war.
The war in Ukraine and Western sanctions against Russia are also issues at the 85th meeting of the Réseaux IP Européens Network (RIPE), for which the European IP address managers are currently convening in Belgrade. The cry for help from the Ukrainian members to freeze IP address assignments in the contested areas to prevent their confiscation is becoming more and more urgent.
The transfer of IP addresses from Ukrainian companies to Russian owners in the contested areas must be stopped immediately, demanded lawyer Andrii Pylypenko, who advises the Ukrainian Ministry of Justice. All transfers of Ukrainian IP addresses to new Russian sites are illegal.
“At Gun Point”
Representatives of Ukrainian IT companies and associations support the claim. She knows about forced transfers of IP addresses “at gunpoint,” Olena Kushnir from provider Web Pro told the RIPE meeting in Belgrade. One should not lose any more time, appealed Viktoriia Opanasiuk from the Telecom Ukraine Association.
The best possible protection is the immediate freezing of Ukrainian IP addresses and numbers for autonomous systems (AS), says Pylypenko. The lawyer offered that RIPE’s operational arm responsible for transfers and assignments, RIPE NCC, could cooperate with Ukrainian authorities. These tried to protect Ukrainian IT companies as well as possible. According to Pylypenko, such cooperation reduces any legal risks for the RIPE NCC and allows immediate action.
The immediate or temporary freezing of all address and prefix transfers prevents the risk of illegal and forced transfers, but also legitimate transfers warned RIPE NCC General Counsel Athina Fragkouli. In addition, the RIPE database might then no longer display the correct owner entries.
“We would be violating our own statutes and would therefore like to have a corresponding policy that is approved by the members,” said Fragkouli. Without such a change, lawsuits against the organization cannot be ruled out. The involvement of Ukrainian government agencies, brought into play by Pypylenko, is shifting the self-government model in the direction of greater government influence. This also requires a decision by the members.
The new policy takes “months”
The adoption of a new policy would take at least months, criticized numerous members. The almost unanimous opinion was that the colleagues in Ukraine needed a solution immediately. A temporary freeze mechanism, for example, is ultimately a contractual agreement and not a new policy, says Erik Bais, co-chair of the “Address Policy” working group.
Fragkouli emphasized that there is already no legal obstacle to a particularly critical examination of the requested transfers. In addition, a disclaimer can be added to the transfers, which refers to the special situation in the country and states that the transfer can be reversed in the event of later court proceedings. Such a disclaimer could also cause a further transfer to be blocked.
The executive board of IP address management now wants to decide on an interim solution against address theft. The newly appointed CEO Ondrej Sury assured the members that a resolution by the board would quickly be found, which could extend to changes in the RIPE statutes. A political solution for the treatment of transfers in “areas under distress” is to follow.
There are still many questions to be answered – for example, what happens if areas are claimed by several governments (“areas in dispute”). A network operator from Crimea asked how RIPE would view its IP address resources: “Some say we’re Ukrainian, others say we’re Russian.” As a Ukrainian company, a complete freeze on transfers of Ukrainian resources would even put you at a disadvantage, because other Crimea companies can happily sell and transfer.
More and more affected by sanctions
The war against Ukraine occupies address management in several respects. The number of RIPE members affected by the sanctions has doubled since the spring. The RIPE NCC receives hundreds of reports that need to be checked. For the time being, the addresses of the Russian members will simply be frozen. The RIPE NCC has refrained from withdrawing addresses, as Ukrainian members are demanding.
The membership fees are deferred for the time being, because a transfer to the commercial banks of the RIPE NCC is also blocked by sanctions. Meanwhile, the Amsterdam-based office of the RIPE NCC is negotiating with the Dutch authorities for a general exemption from sanctions for communication resources.
A shift in the regional address world had become apparent within the RIPE, among other things with the dissolution of the Eurasia Network Operators Group, which had been founded to improve the participation of the Eastern European members. Established in 2010, ENOG disbanded at the start of the war. The address administrators are now faced with the question of how to integrate the group, which has at least 20,000 members, in the future.
[This is a transcript of the video embedded below. Some of the explanations may not make sense without the animations in the video.]
Have you ever put away a bag of chips because they say it isn’t healthy? That makes sense. Have you ever put away a bag of chips because you want to increase your chances of having more children so we can populate the entire galaxy in a billion years? That makes… That makes you a longtermist. Longtermism is a currently popular philosophy among rich people like Elon Musk, Peter Thiel, and Jaan Tallinn. What do they believe and how crazy is it? That’s what we’ll talk about today.
The first time I heard of longtermism I thought it was about terms of agreement that get longer and longer. But no. Longtermism is the philosophical idea that the long-term future of humanity is way more important than the present and that those alive today, so you, presumably, should make sacrifices for the good of all the generations to come.
Longtermism has its roots in the effective altruism movement, whose followers try to be smart about donating money so that it has the biggest impact, for example by telling everyone how smart they are about donating money. Longtermists are concerned with how our future will look like in some billion years or longer. Their goal is to make sure that we don’t go extinct. So stop being selfish, put away that junk food and make babies.
The key argument of longtermists is that our planet will remain habitable for a few billion years, which means that most people who’ll ever be alive are yet to be born.
Here’s a visual illustration of this. Each grain of sand in this hourglass represents 10 million people. The red grains are those who lived in the past, about 110 billion. The green one are those alive today, that’s about 8 billion more. But that is just a tiny part of all the lives that are yet to come.
A conservative estimate is to assume that our planet will be populated by at least a billion people for at least a billion years, so that’s a billion billion human life years. With today’s typical life span of 100 years, that’d be about 10 to the 16 human lives. If we’ll go on to populate the galaxy or maybe even other galaxies, this number explodes into billions and billions and billions.
Unless. We go extinct. Therefore, the first and foremost priority of longtermists is to minimize “existential risks.” This includes events that could lead to human extinction, like an asteroid hitting our planet, a nuclear world war, or stuffing the trash so tightly into the bin that it collapses to a black hole. Unlike effective altruists, longtermists don’t really care about famines or floods because those won’t lead to extinction.
One person who has been pushing longtermism is the philosopher Nick Bostrom. Yes, that’s the same Bostrom who believes we live in a computer simulation because his maths told him so. The first time I heard him give a talk was in 2008 and he was discussing the existential risk that the programmer might pull the plug on that simulation we supposedly live in. In 2009 he wrote a paper arguing:
“A non-existential disaster causing the breakdown of global civilization is, from the perspective of humanity as a whole, a potentially recoverable setback: a giant massacre for man, a small misstep for mankind”
Yeah, breakdown of global civilization is exactly what I would call a small misstep. But Bostrom wasn’t done. By 2013 he was calculating the value of human lives: “We find that the expected value of reducing existential risk by a mere one billionth of one billionth of one percentage point is worth a hundred billion times as much as a billion human lives [in the present]. One might consequently argue that even the tiniest reduction of existential risk has an expected value greater than that of the definite provision of any ‘ordinary’ good, such as the direct benefit of saving 1 billion lives ”
Hey, maths doesn’t lie, so I guess that means okay to sacrifice a billion people or so. Unless possibly you’re one of them. Which Bostrom probably isn’t particularly worried about because he is now director of the Future of Humanity Institute in Oxford where he makes a living from multiplying powers of ten. But I don’t want to be unfair, Bostrom’s magnificent paper also has a figure to support his argument that I don’t want to withhold from you, here we go, I hope that explains it all.
By the way, this nice graphic we saw earlier comes from Our World in Data which is also located in Oxford. Certainly complete coincidence. Another person who has been promoting longtermism is William MacAskill. He is a professor for philosophy at, guess what, the University of Oxford. MacAskill recently published a book titled “What We Owe The Future”.
I didn’t read the book because if the future thinks I owe it, I’ll wait until it sends an invoice. But I did read a paper that MacAskill wrote in 2019 with colleague Hilary Greaves titled “The case for strong longtermism”. Hilary Greaves is a philosopher and director of the Global Priorities Institute which is located in, surprise, Oxford. In their paper they discuss a case of long-termism in which decision makers choose “the option whose effects on the very long-run future are best,” while ignoring the short-term. In their own words:
“The idea is then that for the purposes of evaluating actions, we can in the first instance often simply ignore all the effects contained in the first 100 (or even 1,000) years, focussing primarily on the further-future effects.”
So in the next 100 years, anything goes so long as we don’t go extinct. Interestingly enough, the above passage was later removed from their paper and can no longer be found in the 2021 version.
In case you think this is an exclusively Oxford endeavour, the Americans have a similar think tank in Cambridge, Massachusetts, called The Future of Life Institute. It’s supported among others by billionaires Peter Thiel, Elon Musk, and Jaan Tallinn who have expressed their sympathy for longtermist thinking. Musk for example recently commented that MacAskill’s book “is a close match for [his] philosophy”. So in a nutshell longtermists say that the current conditions of our living don’t play a big role and a few million deaths are acceptable, so long as we don’t go extinct.
Not everyone is a fan of longtermism. I can’t think of a reason why. I mean, the last time a self-declared intellectual elite said it’s okay to sacrifice some million people for the greater good, only thing that happened was a world war, just a “small misstep for mankind.”
But some people have criticized longtermists. For example, the Australian philosopher Peter Singer. He is one of the founders of the effective altruism movement, and he isn’t pleased that his followers are flocking over to longtermism. In a 2015 book, titled The Most Good You Can Do he writes:
“To refer to donating to help the global poor or reduce animal suffering as a “feel-good project” on which resources are “frittered away” is harsh language. It no doubt reflects Bostrom’s frustration that existential risk reduction is not receiving the attention it should have, on the basis of its expected utility. Using such language is nevertheless likely to be counterproductive. We need to encourage more people to be effective altruists, and causes like helping the global poor are more likely to draw people toward thinking and acting as effective altruists than the cause of reducing existential risk.”
Basically Singer wants Bostrom and his likes to shut up because he’s afraid people will just use longtermism as an excuse to stop donating to Africa without benefit to existential risk reduction. And that might well be true, but it’s not a particularly convincing argument if the people you’re dealing with have a net worth of several hundred billion dollars. Or if their “expected utility” of “existential risk reduction” is that their institute gets more money.
Singers second argument is that it’s kind of tragic if people die. He writes that longtermism “overlooks what is really so tragic about premature death: that it cuts short the lives of specific living persons whose plans and goals are thwarted.”
No shit. But then he goes on to make an important point: “just how bad the extinction of intelligent life on our planet would be depends crucially on how we value lives that have not yet begun and perhaps never will begin.” Yes, indeed, the entire argument for longtermism depends crucially on how much value you put on future lives. I’ll say more about this in a minute, but first let’s look at some other criticism.
The cognitive scientist Steven Pinker, after reading MacAskill’s What We Owe The Future, shared a similar reaction on twitter in which he complained about: “Certainty about matters on which we’re ignorant, since the future is a garden of exponentially forking paths; stipulating correct answers to unsolvable philosophical conundrums [and] blithe confidence in tech advances played out in the imagination that may never happen.”
The media also doesn’t take kindly to longtermism. Some, like Singer, complain that that longtermism draws followers away from the effective altruism movement. Others argue that the technocratic vision of longtermists is also anti-democratic. For example Time Magazine wrote that Elon Musk has “sold the fantasy that faith in the combined power of technology and the market could change the world without needing a role for the government”
Christine Emba, in an opinion piece for the Washington Post, argued that “the turn to longtermism appears to be a projection of a hubris common to those in tech and finance, based on an unwarranted confidence in its adherents’ ability to predict the future and shape it to their liking” and that “longtermism seems tailor-made to allow tech, finance and philosophy elites to indulge their anti-humanistic tendencies while patting themselves on the back for their intelligence and superior IQs. The future becomes a clean slate onto which longtermists can project their moral certitude and pursue their techno-utopian fantasies, while flattering themselves that they are still “doing good.””
Okay, so now that we have seen what either side says, what are we to make of this.
The logic of longtermists hinges on the question what the value of a life in the future is compared to ours while factoring in the uncertainty of this estimate. There are two elements which goes into this evaluation. One is an uncertainty estimate for the future projection. The second is a moral value, it’s how much future lives matter to you compared to ours. This moral value is not something you can calculate. That’s why longtermism is a philosophical stance, not a scientific one. Longtermist try to sweep this under the rug by blinding the reader with numbers that look kind of sciencey.
To see how difficult these arguments are, it’s useful to look at a thought experiment known as Pascal’s mugging. Imagine you’re in dark alley. A stranger steps in front of you and says “Excuse me, I’ve forgotten my knife but I’m a mugger, so please give me your wallet.” Do you give him your money? Probably not.
But then he offers to pay back double the money in your wallet next month. Do you give him your money? Hell no, he’s almost certainly lying. But what if he offers a hundred times more? Or a million times? Going by economic logic, eventually the risk of losing your money because he might be lying becomes worth it because you can’t be sure he’s lying. Say you consider the chances of him being honest 1 in 10,000. If he offered to return you 100 thousand times the amount of money in your wallet, the expected return would be larger than the expected loss.
But most people wouldn’t use that logic. They wouldn’t give the guy their money no matter what he promises. If you disagree, I have a friend who is a prince in Nigeria, if you send him 100 dollars, he’ll send back a billion, just leave your email in the comments and we’ll get in touch.
The point of this thought experiment is that there’s a second logical way to react to the mugger. Rather than to calculate the expected wins and losses, you note that if you agree to his terms on any value, then anyone can use the same strategy to take literally everything from you. Because so long as your risk assessment is finite, there’s always some promise that’ll make the deal worth the risk. But in this case you’d lose all your money and property and quite possibly also your life just because someone made a promise that’s high enough. This doesn’t make any sense, so it’s reasonable to refuse giving money to the mugger. I’m sure you’re glad to hear.
What’s the relation to longtermism? In both cases the problem is how to assign a probability to unlikely future events. For Pascal’s mugger that’s the unlikely event that the mugger will actually do what he promised. For longtermism the unlikely events are the existential threats. In both cases our intuitive reaction is to entirely disregard them because if we did, the logical conclusion seems to be that we’d have to spend as much as we can on these unlikely events about which we know the least. And this is basically why longtermists think people who are currently alive are expendable.
However, when you’re arguing about the value of human lives you are inevitably making a moral argument that can’t be derived from logic alone. There’s nothing irrational about saying you don’t care about starving children in Africa. There’s also nothing irrational about saying you don’t care about people who may or may not live on Mars in a billion years. It’s a question of what your moral values are.
Personally I think it’s good to have longterm strategies. Not just for the next 10 or 20 years. But also for the next 10 thousand or 10 billion years. So I really appreciate the longtermists’ focus on the prevention of existential risks. However, I also think they underestimate just how much technological progress depends on the reliability and sustainability of our current political, economic, and ecological systems. Progress needs ideas, and ideas come from brains which have to be fed both with food and with knowledge. So you know what, I would say, grab a bag of chips and watch a few more videos.
RISC-V has been around for some time now, and if you are here it’s because you have heard of it. But perhaps you still need to be convinced that it is the future? If you still wonder about its potential and benefits, here are 5 good things about RISC-V.
1. RISC-V IS AN OPEN STANDARD
Let’s start simple. This is nothing new, but let’s be clear on what open standard means.
Open standard does not necessarily mean open source. The RISC-V architecture is often described as “open-source”, which is inaccurate. As we explained it in this article on architecture licenses in the context of RISC-V, RISC-V is like C, Wi-Fi, or LTE with RISC-V International performing the role of (respectively) ANSI, IEEE 802.11 and 3GPP in defining and managing standards that people are free to implement as they choose. But that is a written standard – not an implementation or a microarchitecture. Just as is the case with those other open standards, RISC-V licenses can either be open-source or commercial.
Therefore, the RISC-V Instruction Set Architecture (ISA) is open, meaning that it is free and anyone can download the documentation to use it however they like, without asking for anyone’s permission. This is great because it allows smaller developers, companies, and groups such as academics to design and build hardware without paying an expensive proprietary ISA license and royalties. RISC-V is accessible to everyone.
2. RISC-V IS ATTRACTIVE TO UNIVERSITY RESEARCHERS
You may already know that RISC-V started as a university research project in California, at UC Berkeley, back in 2010. As we just mentioned the interesting financial aspect it brings, it is not really surprising to see more and more university researchers looking into it.
Now, researchers can do it two ways. Thanks to the work of various academic institutions such as UC Berkley, there are free open-source implementations of the RISC-V ISA available. These can be used in university projects to do work that would not be possible without an open standard.
To go one step further, universities can also partner with RISC-V companies that are developing university programs. What a great way to prepare today’s students to become the engineers of tomorrow! Codasip for example has a University Program. By cooperating with academia, we can accelerate the development of RISC-V IP and design automation. Having university researchers working on RISC-V is another key to its success in solving tomorrow’s technological challenges.
3. RISC-V ALLOWS FOR CUSTOMIZATION
That’s where the true potential of RISC-V is.
The RISC-V open standard allows people to customize. Most commercial companies do not support this, however. They sell a standard, fixed, product. Of course, if you design your own code, then the freedom is there – but for most people, that is not possible. Some companies, like Codasip, give the best of both worlds: customization and the rich ecosystem of RISC-V. With RISC-V being a layered and extensible ISA, these companies allow you to implement the baseline instruction set, optional extensions, and add custom extensions for a given application.
Let me just clarify one thing here. Don’t mix up customization and configuration. Being able to choose the size of a cache is great, but that’s not customization. Customization means being able to modify the instruction set architecture and the microarchitecture. That’s quite powerful as this is how you design an application-specific processor perfectly tailored to your unique needs.
4. RISC-V GIVES YOU FREEDOM AND OWNERSHIP
Let’s go one step further now. By allowing customization, RISC-V allows you to be independent. You work from an open standard that you can modify as you want. You can now do your own things, your own way, while still talking advantage of the standard RISC-V architecture and software interoperability. That’s something very powerful and that will be crucial in many industry sectors.
Let’s take the example of automotive. Owning the ability to differentiate is the key to success in such a rapidly evolving sector. Players in this industry will need best-in-class quality IP but also processor design automation technology with the potential to accelerate innovation through processor customization. Jamie Broome, our VP of Automotive, wrote an interesting article on the potential of RISC-V and customization for automotive.
5. THE RISC-V ECOSYSTEM IS GROWING RAPIDLY
The RISC-V standard is maintained by RISC-V International, with members such as Codasip, coming from across the industry: software, systems, semiconductor and IP. The focus is on building a rich hardware and software ecosystem, and this is happening. RISC-V International mentions more than 3,100 RISC-V members across 70 countries.
There have been new processors and new ISAs in the past. But what is different about RISC-V is the ecosystem. As both Intel and Arm have shown, this is the critical factor in a processor architecture’s success. More ecosystem players means more software, more tools: that means more developers selecting that ISA, more commercial traction, which in turn attracts more ecosystem partners in an accelerating virtuous spiral. It is that spiral that is driving the market success of RISC-V.
Did you hear about the Intel® Pathfinder for RISC-V program? Or the OpenHW Group? From creating development environments to starting your RISC-V journey to make verification a real strength, the ecosystem is growing and evolving rapidly to make RISC-V the preferred choice of the majority.
RISC-V is for all. That’s the great thing about it. And with more players, from tools and IP providers to adopters, there is only more choice which can only lead to greater innovation. We, at Codasip, are very excited to be part of the revolution.
If you want to stay informed, simply join our community! We regularly share the latest news and achievements in our newsletter.
Let’s talk about one of my favorite cryptography papers.
This is the paper that keeps showing up. It’s almost comical at this point. It’s shown up 5 times in my last semester at EPFL, across 3 different courses. It showed up as part of the paper my colleague and I reviewed for a seminar, it showed up for attribute-based credentials in a course about Privacy-Enhancing-Technologies, it showed up in an advanced Cryptography course on two homeworks, and on the final exam!
Everywhere I go, I see this paper, and no one even seems to be aware of the fact that they’re using it!
What is this wonderful gem, you might ask?
Well, it’s none other than “Unifying Zero-Knowledge Proofs of Knowledge”, by Ueli Maurer [Mau09]:
This paper is short, but contains a very interesting result. Maurer taks the humble Schnorr signature / proof, which lets you prove knowledge of a scalar $x$ such that $x \cdot G = X$, without revealing that scalar, and generalizes this scheme to work for any group homomorphism!
This captures a very wide swathe of functionality, from Schnorr signatures, to Pedersen commitments, to attribute-based credentials, to polynomial commitment schemes. We’ll be seeing how to construct all of these examples, and more, in the rest of this post, so let’s dive right into it!
Warmup: Schnorr Proofs
As a bit of a warmup, let’s go over how Schnorr proofs work. These are also a great example to introduce the relevant security notions we’ll be working with, like completeness, soundness, etc.
We’ll be working with a cryptographic group $\mathbb{G}$, generated by $G$, of prime order $q$, and with an associated field of scalars $\mathbb{F}_q$.
In a Schnorr proof, the prover has a secret $x \in \mathbb{F}_q$, and a public value $X \in \mathbb{G}$. The prover wants to demonstrate that $X = x \cdot G$, without revealing $x$.
For the prover to convince the verifier, the two of them run a protocol together:
$$ \boxed{ \begin{aligned} &\mathcal{P} \text{ knows } x \in \mathbb{F}_q&\quad&\mathcal{V} \text{ knows } X \in \mathbb{G} \cr \cr &k \xleftarrow{R} \mathbb{F}_q\cr &K \gets k \cdot G\cr &&\xrightarrow{K}\cr &&&c \xleftarrow{R} \mathbb{F}_q\cr &&\xleftarrow{c}\cr &s \gets k + c \cdot x\cr &&\xrightarrow{s}\cr &&&s \cdot G \stackrel{?}{=} K + c \cdot X\cr \end{aligned} } $$
The prover generates their random nonce $k$, and then sends $K := k \cdot G$, which is, in essence, a commitment to this nonce. The verifier responds in turn with a random challenge $c$, which the prover then uses to create their response $s$. Finally, the verifier checks that the response is consistent with the challenge and the public input $X$.
Completeness
The first property we want a protocol like this to satisfy is completeness. If $x$ is correct, i.e. $X = x \cdot G$, then we need verification to succeed at the end of the protocol, assuming that the prover behaves honestly.
To see why this is the case, we need to use the linearity of scalar multiplication: $$ (a + b) \cdot G = a \cdot G + b \cdot G $$
If we apply this to the response $s$, we get:
$$ s \cdot G = (k + c \cdot x) \cdot G = k \cdot G+ c \cdot (x \cdot G) = K + c \cdot X $$
And so, the verification check will pass.
It’s crucial here that $s$ is actually equal to $k + c \cdot x$, and that $X = x \cdot G$, which requires the prover to be honest. Completeness just says that if the prover is honest, and that the property they’re trying to prove holds, then the protocol will succeed. Completeness doesn’t say anything about the case where the prover misbehaves, or where the property doesn’t actually hold.
Honest Verifier Zero-Knowledge
One way to demonstrate knowledge of a value $x$ such that $x \cdot G = X$ would be to simply reveal the value $x$. The reason we do this complicated Schnorr protocol instead is because we want to prove that we know such an $x$ without revealing it. In fact, we don’t want to reveal any information about $x$ whatsoever.
This is where the honest verifier zero-knowledge property comes in. In essence, it says that if the verifier behaves honestly, then they don’t learn any information about the secret value $x$. At least, not any information that they couldn’t have gotten just by knowing the public value $X$.
Capturing the notion of “not learning any information” is tricky. To do this, we use a simulator $\mathcal{S}$. This simulator $\mathcal{S}$ takes as input the public input $X$, and the challenge $c$, and then creates values $K$ and $s$ which should have the same distribution of the actual messages sent by the prover in the real protocol.
The intuition here is that because the verifier can’t distinguish between the messages from a real protocol, and the messages created by the simulator, then they learn nothing that they didn’t know before, since they already had access to both $X$ and $c$. It’s important that the verifier behave honestly, and choose their challenge $c$ at random, and not change the way they choose $c$ based on $K$. Because this challenge $c$ is independent from $K$, you could generate it before even seeing $K$, which means that the messages that you see after that, including $K$, could be coming from a simulator instead, without the verifier realizing it. On the other hand, if the verifier misbehaves, and chooses $c$ differently depending on $K$, then our simulation strategy has to work a bit differently.
In this case, the simulator is pretty simple. We know that the commitment $K$ and response $s$ must satisfy: $$ s \cdot G = K + c \cdot X $$
Our simulator $\mathcal{S}$ needs to return $(K, s)$ as a function of $(X, c)$. One way to do this is to simply choose $s$ at random, and then set:
$$ K \gets s \cdot G - c \cdot X $$
Because $s$ is random, the value $K$ ends up also being a random group element, which is the same as for a real execution of the protocol. Ditto with $s$ itself.
This is enough to show that the Schnorr protocol is honest verifier zero-knowledge.
At this point, we know that if the prover is honest, then they convince the verifier. We also know that an honest verifier learns nothing by running the protocol. But what if the prover is dishonest?
We don’t want the prover to be able to convince the verifier unless they actually know an $x$ such that $x \cdot G = X$.
Our strategy to show this will be to use an extractor. The idea is that if we have two transcripts $(K, c, s)$ and $(K, c', s')$, with $c \neq c'$, which share the same first message, then our extractor $\mathcal{E}$ will be able to produce a value $\hat{x}$ satisfying ${\hat{x} \cdot G = X}$.
This means that the prover must have known such a value.
The intuition here is that you treat the prover as a machine with the value embedded inside of it, somehow. Then, you can get these two transcripts by rewinding this machine. After sending the first challenge $c$ and getting the response $s$, you rewind the machine back to the point where it sent $K$, and now you send it a new challenge $c'$, and get a new response $s'$.
Intuitively, if the value $x$ is embedded inside of the machine, then rewinding doesn’t change this fact. If we can successfully extract the value using these two forked transcripts, that means the value was always present inside of the machine.
Here’s another analogy. Let’s say we had access to a time machine. We could use this time machine to wind back time to when the prover sent $K$, and use that to get our two transcripts. Now, having a time machine doesn’t change whether or not a value was embedded inside of the prover, so this convinces us that they knew this value to begin with.
Note that this rewinding is really more of a theoretical point, which we use in proving the soundness of the protocol. We don’t actually need to be able to rewind the protocol. This rewinding might be problematic for concurrent security, but that’s a can of worms best left unopened for now.
With that aside, let’s actually create this extractor, shall we?
Given our two transcripts $(K, c, s)$ and $(K, c', s')$ we know that they must satisfy:
$$ \begin{aligned} &s \cdot G = K + c \cdot X\cr &s' \cdot G = K + c' \cdot X\cr \end{aligned} $$
If we subtract the two equations, we get:
$$ (s - s') \cdot G = (c - c') \cdot X $$
Finally, since $c \neq c'$, we can divide by $(c - c')$ to get:
$$ \frac{(s - s')}{(c - c')} \cdot G = X $$
We now see that if our extractor sets: $$ \hat{x} \gets (s - s') / (c - c') $$
then they’ve managed to find a value $\hat{x}$ such that $\hat{x} \cdot G = X$, as promised.
Aside: Sigma Protocols
This Schnorr protocol is a specific example of what we call a sigma protocol.
This is a three move protocol, wherein the prover sends a commitment, the verifier samples a random public challenge, the prover sends a response, and then a verification check based on the transcript and the public input is run.
The Maurer proofs we’ll see in the next section are also sigma protocols.
Because the verifier’s challenge is completely public, and the verification check doesn’t depend on any internal state in the verifier, we call this a public coin protocol.
What’s nice about public coin protocols is that they can be made non-interactive, via the Fiat-Shamir transform. The idea is that instead of having a verifier choose a challenge, we instead emulate this choice with a hash function $H$, whose output should function in the same way as the random challenge.
This allows the prover to create a proof without interacting with anybody else, and this proof can be independently verified by different people.
Schnorr signatures are really just the application of this transform to the protocol we saw earlier, with the inclusion of the message we want to sign, $m$, inside of the hash function, so that the proof is “bound” to this specific message.
Generalization: Maurer Proofs
Maurer proofs [Mau09] can be seen as a vast generalization of Schnorr proofs.
Given a group homomorphism $\varphi : \mathbb{A} \to \mathbb{B}$, they allow you to prove knowledge of $a \in \mathbb{A}$ such that $\varphi(a) = B$, without revealing the secret $a$. Specifically, you don’t learn anything more about $a$ than you could have learned from $B$.
Schnorr proofs are a specific case of these proofs, with the homomorphism: $$ \begin{aligned} \psi &: (\mathbb{F}_q, +) \to \mathbb{G}\cr \psi(x) &:= x \cdot G\cr \end{aligned} $$
The protocol for the general case of $\varphi : \mathbb{A} \to \mathbb{B}$ is very similar to Schnorr proofs as well:
$$ \boxed{ \begin{aligned} &\mathcal{P} \text{ knows } a \in \mathbb{A}&\quad&\mathcal{V} \text{ knows } B \in \mathbb{B} \cr \cr &k \xleftarrow{R} \mathbb{A}\cr &K \gets \varphi(k)\cr &&\xrightarrow{K}\cr &&&c \xleftarrow{R} \mathcal{C}\cr &&\xleftarrow{c}\cr &s \gets k + c \cdot a\cr &&\xrightarrow{s}\cr &&&\varphi(s) \stackrel{?}{=} K + c \cdot B\cr \end{aligned} } $$
The protocol proceeds in a familar way. The prover generates a random nonce $k$, sends their commitment $\varphi(k)$, the verifier responds with a challenge $c$, and the prover concludes with their response $s$.
The set $\mathcal{C}$ denotes the challenge space. The way we define this set depends on the homomorphism $\varphi$, and the public value $B$. We’ll see what conditions we need this set to satisfy when we prove extraction for this protocol.
Completeness
Completeness holds because $\varphi$ is a homomorphism:
$$ \varphi(s) = \varphi(k + c \cdot a) = \varphi(k) + c \cdot \varphi(a) = K + c \cdot B $$
Honest Verifier Zero-Knowledge
The simulator is also pretty simple to define.
Given a challenge $c$, we know that $K$ and $s$ must satisfy:
$$ \varphi(s) = K + c \cdot B $$
The idea behind our simulator, like with Schnorr proofs, is to generate a random $s$, and then define $K$ as a function of $s$, $B$, and $c$:
$$ K \gets \varphi(s) - c \cdot B $$
Since $s$ is random, this makes $K$ as random as in the real protocol, and so our simulator works.
Extraction is a bit trickier, because we need to choose our challenge space $\mathcal{C}$. This is simple when we know the order of the group $\mathbb{B}$, but we can also find challenge spaces which work even if the order of the group is unknown.
Our extractor has access to two transcripts $(K, c, s)$ and $(K, c', s')$, with $c \neq c'$. These transcripts are valid, and so satisfy:
$$ \begin{aligned} \varphi(s) &= K + c \cdot B\cr \varphi(s') &= K + c' \cdot B\cr \end{aligned} $$
If we subtract the equations, we get:
$$ \varphi(s) - \varphi(s') = (c - c') \cdot B $$
Since $\varphi(s)$ is a homomorphism, we can write:
$$ \varphi(s - s') = (c - c') \cdot B $$
Now, if we knew the order of $\mathbb{B}$, say $q$, then we could invert $c - c'$ mod $q$, giving us:
and then use the fact that $\varphi(s - s')$ is a homomorphism, giving us:
$$ \varphi \left(\frac{s - s'}{c - c'}\right) = B $$
And we could then use this value as our extractor.
But it turns out that you can make the extraction work even if you don’t know the order.
To do this, we need to assume the existence of an “anchor value” $u \in \mathbb{A}$, such that there exists $l$ with:
$$ \varphi(u) = l \cdot B $$
We also require that $\gcd(l, (c - c')) = 1$ for all $c \neq c' \in \mathcal{C}$. This means that there exists coefficients $\alpha, \beta \in \mathbb{Z}$ such that:
$$ \alpha \cdot l + \beta (c - c') = 1 $$
We can then use this to define our extracted value $\hat{x}$:
$$ \hat{x} := \alpha \cdot u + \beta \cdot (s - s') $$
To see why this works, remember that $\varphi(s - s') = (c - c') \cdot B$, which means that:
$$ \begin{aligned} \varphi(\hat{x}) &=\cr \varphi(\alpha \cdot u + \beta \cdot (s - s')) &=\cr \alpha \cdot \varphi(u) + \beta \cdot \varphi(s - s') &=\cr \alpha \cdot l \cdot B + \beta \cdot (c - c') \cdot B &=\cr (\alpha \cdot l + \beta \cdot (c - c')) \cdot B &=\cr 1 \cdot B &= B\cr \end{aligned} $$
We also need the set $\mathcal{C}$ to be large enough, e.g. $|\mathcal{C}| \geq 2^\lambda$, with $\lambda$ our security parameter. Or, we could use a smaller set, and do multiple repetitions of the protocol.
In summary, we need a large set $\mathcal{C}$ such that for any $c \neq c' \in \mathcal{C}$, there exists an anchor value $u$ and exponent $l$ such that:
$$ \varphi(u) = l \cdot B $$
and $\gcd(l, c - c') = 1$.
Let’s see a few examples of how this works.
If you know the order of a group $\mathbb{B}$, and this group has prime order $q$, then you can easily create this set.
The element $0 \in \mathbb{A}$ can act as our anchor value, since $q \cdot B = 0 = \varphi(0)$, no matter what value $B$ has.
Furthermore, if we take $\mathcal{C} = \mathbb{F}_q$, then the difference between any two elements in $\mathbb{F}_q$ will be coprime with $q$, since $q$ is a prime number, and the difference will be ${< q}$.
In fact, instead of using the order of the group, it suffices to use the exponent. This is a value $e$ such that $e \cdot B = 0$ for any value $B \in \mathbb{B}$. When taking the product of several groups, this will be smaller than the order, which is nice.
Let’s say that you want to do this for an RSA group $(\mathbb{Z}/(N), \cdot)$. The issue is that you don’t know the order of this group.
The homomorphism in this case is:
$$ \varphi(x) := x^e $$
(done modulo $N$)
You also know a public value $y$, claimed to equal $x^e$ for some secret $x$.
This homomorphism naturally guides our choice of anchor. We need to find a $u$ such that $\varphi(u) = y^l$. Unraveling $\varphi$, we need $u^e = y^l$.
Well, one simple way to satisfy this is to take $l = e$ and $u = y$, giving us the equation:
$$ y^e = y^e $$
Now, we need to find a set $\mathcal{C}$ where the difference with any two elements is coprime with $e$. This is quite simple if $e$ is a prime number, which is usually the case: we can simply take $\mathcal{C} = \mathbb{Z}/(e)$. All (non-negative) numbers $< e$ will have difference which is coprime with $e$, since $e$ is prime.
Now, if $e$ is a small prime number, then we’ll need to repeat our protocol several times for soundness. For example, if $e$ is $3$, then we’d need to repeat our protocol $128 / (\text{lg } 3)$ times, for $128$ bit security.
Summary
In summary, given a group homomorphism $\varphi : \mathbb{A} \to \mathbb{B}$, Maurer proofs are a sigma protocol for proving knowledge of a secret $a \in \mathbb{A}$ such that $\varphi(a) = B$, for a public $B$.
The only assumption we need to make about the groups is that we can construct a set $\mathcal{C}$ such that there exists an exponent $l \in \mathbb{Z}$, with $\gcd(l, (c - c')) = 1$ for all $c \neq c' \in \mathcal{C}$, and an anchor $u \in \mathbb{A}$ satisfying:
$$ \varphi(u) = l \cdot B $$
Some Applications
We’ve now seen what Maurer proofs are, and how general they are. While they sure are neat, presented like this they may still be a bit uninteresting. When I first read the paper, I thought it was cool, but nothing to write home about. What really made it one of my favorite papers was accidentally stumbling into a bunch of applications that people weren’t even aware were specific instances of Maurer proofs.
In this section, we’ll be going over quite a few of these applications.
Schnorr Proofs
I’ve mentioned this one a few times already, but it’s worth seeing again.
With a Schnorr proof, you want to show that you know a secret $x$ such that ${x \cdot G = X}$, with $X$ public.
We can capture this with a convenient notation for relations:
$$ \{(G, X ; x)\ |\ x \cdot G = X\} $$
The elements to the left of the $;$ are public, those to the right are private, and the statement after the $|$ is the relation which needs to hold.
We can write this as a Maurer relation:
$$ \{(\varphi, X ; x)\ |\ \varphi(x) = X\} $$
With $\varphi(x) := x \cdot G$, which is homomorphic.
The challenge set $\mathcal{C}$ can be chosen to be $\mathbb{F}_q$, as explained earlier.
Guillou-Quisquater Proofs
The Guillou-Quisquater protocol [GQ88] is similar to Schnorr proofs, but instead works over an RSA group.
Given an RSA modulus $N$, and public exponent $e$ (which we assume to be prime), you can define the following relation:
$$ \{(N, e, y ; x) \ |\ x^e \equiv y \mod N \} $$
But, this is really just an instance of a Maurer relation, with the homomorphism:
We also need to pick our challenge set $\mathcal{C}$. If $e$ is a prime number, then we can simply take $\mathbb{Z}/(e)$, as we saw earlier.
We might need several parallel repetitions of the protocol if $e$ is small though.
Parallel Schnorr
One useful extension of Schnorr proofs is when you want to prove multiple instances in parallel:
$$ \{(G, A, B; a, b)\ |\ a \cdot G = A \land b \cdot G = B \} $$
Interestingly enough, this is also an instance of a Maurer relation, with the homomorphism:
$$ \begin{aligned} &\varphi : \mathbb{F}^2_q \to \mathbb{G}^2\cr &\varphi(a, b) := (a \cdot G, b \cdot G) \end{aligned} $$
For our challenge set, we can simply use $\mathbb{F}_q$, since $\text{lcm}(q, q) = q$.
In general, taking products of group homomorphisms is an extremely useful way to create Maurer relations.
Pedersen Commitment Proofs
A Pedersen commitment requires two independent generators $G, H \in \mathbb{G}$, and forms the commitment to $x$ as:
$$ x \cdot G + r \cdot H $$
for some blinding factor $r \in \mathbb{F}_q$.
One useful relation is proving that a value $X = x \cdot G$, with $x$ hidden by a commitment $C$:
$$ \{(G, H, X, C; x, r)\ |\ x \cdot G = X \land x \cdot G + r \cdot H = C \} $$
As you might guess, this is in fact a Maurer relation, for the homomorphism:
$$ \begin{aligned} &\varphi : \mathbb{F}_q^2 \to \mathbb{G}^2 \cr &\varphi(x, r) := (x \cdot G, x \cdot G + r \cdot H) \end{aligned} $$
Our challenge set can be $\mathbb{F}_q$ once again.
We can also have an arbitrary homomorphism, and not just $x \cdot G$, which is thanks to the flexibility of Maurer proofs.
Oblivious PRFs
Another interesting example comes from the Privacy Pass paper [DGSTV18].
In essence, a server knows a secret key $k$ that allows them to calculate a prf via:
$$ P \mapsto k \cdot P $$
If you present $(P, Q)$ such that $Q = k \cdot P$, then the server is convinced that it calculated that pair for you, since only it knows $k$, and inverting the discrete logarithm is hard. In this paper, they use this to create redeemable tokens as an alternative to completing captchas.
They also want these tokens to be unlinkable, so they describe a protocol which allows getting such a pair $(P, Q)$ without revealing it to the server.
The idea is to send $P' := r \cdot P$, have the server reply with $k \cdot P'$, which you can then unblind to get $Q := r^{-1} \cdot k \cdot P' = k \cdot P$.
One subtlety is that you need to make sure that the server actually used the same $k$ here that they’ve been using for other people.
One way to do this is for the server to publish $K := k \cdot G$ in advance, and then provide a proof for the relation:
$$ \{(G, P', Q' ; k )\ |\ k \cdot G = K \land k \cdot P' = Q' \} $$
And, if you can believe it, this is an instance of a Maurer relation, with the homomorphism:
$$ \varphi(k) := (k \cdot G, k \cdot P') $$
Attribute-Based Credentials
Attribute-based credentials are an amazing piece of technology which I won’t have time to explain here. I will only use a little bit of the Pointcheval-Sanders scheme [PS15] here anyways.
Their scheme uses two proofs.
The first is for the relation:
$$ \{(G, C, Y_1, \ldots, Y_n; t, a_1, \ldots, a_n) \ |\ C = t \cdot G + \sum_i a_i \cdot Y_i \} $$
This is, as you might have come to expect by now, an instance of a Maurer relation, with the homomorphism:
$$ \varphi(t, a_1, \ldots, a_n) := t \cdot G + \sum_i a_i \cdot Y_i $$
The second proof they use is for the substantially more complicated relation:
The output of this group is an element in $\mathbb{G}_T$, so it suffices to take integers less than the smallest prime factor in the order of $\mathbb{G}_T$ as our challenge set.
TWW Polynomial Commitment Scheme
Finally, let’s conclude our examples with a polynomial commitment scheme, which doesn’t require any fancing pairings or trusted setups.
A polynomial $p$ of degree $d$ consists of $d + 1$ coefficients:
And we can use $\mathbb{F}_q$ as our challenge set, once again.
The disadvantage of this scheme is that opening proofs are quite large.
The communication complexity is $|\mathbb{G}| + (d + 2) \cdot |\mathbb{F}_q|$, because we need to send a group element and a scalar element as our first message (for the output of $\varphi$), and then we need to send our response, which consists of one scalar for each coefficient in our polynomial.
These disadvantages are why I call this the world’s worst polynomial commitment scheme.
Conclusion
Hopefully I could impart to you some of the awe I’ve come to have for Maurer’s paper. It’s really a very neat gem with a surprising number of use cases. It’s quite the shame that more people aren’t aware of it!
We’ve seen how to use it for oblivious PRF proofs, for attribute-based credentials, for polynomial commitments, and of course, for the humble Schnorr signature.
I think you’ll be able to find many more use-cases which I haven’t mentioned in this post, such as final exams in cryptography courses :).
The paper itself is a pretty easy read, so you might want to check that out as well, along with the other references.
In Work on what matters, I wrote about Hunter Walk’s idea of snacking: doing work that is easy to complete but low impact. The best story of my own snacking behaviors comes from my time at Stripe. I was focused on revamping the engineering organization’s approach to operating reliable software, and decided that it might also make sense to start an internal book club. It was, dear reader, not the right time to start a book club. Once you start looking for this behavior, it is everywhere, including on your weekly calendar. Snacking isn’t necessarily bad, a certain amount gives you energy to redeploy against more impactful tasks, but you do have to be careful to avoid overindulging.
Beyond snacking, which can be valuable when it helps you manage your energy levels, there is a similar pattern that happens when a business or individual goes through a difficult moment: under pressure, most people retreat to their area of highest perceived historical impact, even if it isn’t very relevant to today’s problems. Let’s call this reminiscing. When you see your very capable CEO start to micromanage words in a launch email, or your talented CTO start to give style feedback in code reviews, take it for what it’s worth: they’re reminiscing. If you spend the time to dig deeper, they’re almost certainly panicking about something entirely unrelated.
Some real examples from my experience (don’t try too hard to connect them to individuals, I can quickly think of multiple examples for each of these):
“The systems I architected never had significant reliability issues.” Senior-most engineering leader drives top-down rearchitecture of the company’s software, often anchored in the design problems from their last in-the-details technical role rather than current needs (e.g. a Grand Migration). They’d be better served by addressing the cultural or skill-gaps culminating in the reliability problems instead of trying to solve it themselves
“We need to take more risks in our work.” Founders feel trapped by slog of meeting financial projections, and want to reorganize company efforts towards increased innovation without connecting dots to how it will meet the financial projections. Typically this is a throwback to an earlier company phase that is a poor fit for the current phase
“The team I hired was much stronger than this team.” After years of absence, a founder starts revamping the performance or hiring process to address a perceived gap in hiring but without the context of why the process has evolved the way that he has. They’d be better served by holding their managers accountable or empowering their People team
Each of these examples is tightly ingrained into the person’s identity about why they’re someone successful. You can help them recognize the misalignment with today’s needs, but real progress on this issue depends on their own self-awareness. It usually won’t go quickly, but it always gets resolved faster than you might expect, typically through growing self-awareness but rarely by abrupt departures.
Over the past few years, I’ve gotten much better at being mindful of my own snacking inclination. That urge to reorganize our engineering wiki when work gets difficult? Even without knowing the other work I could be doing, it’s easy to identify: that’s snacking, for sure. Reminiscing is much harder for me to identify in a vacuum, it is valuable work, and it’s sometimes very impactful, difficult work, it simply isn’t particularly valuable for you personally to be doing right now.
To catch my own reminiscing, I find I really need to write out my weekly priorities, and look at the ones that keep slipping. Why am I avoiding that work, and is it more important than what I’m doing instead? If a given task slips more than two weeks, then usually I’m avoiding it, and it’s time to figure out where I’m spending time reminiscing.
By his last year at Harvard Medical School, Michael Crichton, 26-years old at the time, knew he didn’t want to pursue a medical career, so he went to the dean with a proposition. He planned to write a nonfiction book about patient care, he explained, and wanted to know if he could use his final semester to hang around the hospital gathering research for his project. “Why should I spend the last half of my last year at medical school learning to read electrocardiograms when I never intended to practice?”, Crichton remembers asking.
The dean replied paternalistically with a warning that writing a book might be more difficult than Crichton expected. It was at this point that the young medical student revealed that he had already published four books while at Harvard (under a pen name), and had multiple other writing projects in progress, including his first medical thriller, A Case of Need, that would soon win him an Edgar Award for best mystery novel of the year, and his first fully-developed techno-thriller, The Andromeda Strain, which would become a breakout bestseller.
I came across this story in a New York Times profile of Crichton written in 1970, a year after he finished medical school. What struck me about this profile was less its origin story heroics, and more its revelation of the sheer busyness of Crichton at this early point in his ascent. While nominally still a postdoc at the Salk Institute in La Jolla, California, when the profile was published, Crichton’s energy was clearly radiating in many different directions. He had just published Five Patients, the non-fiction book he had proposed to his med school dean (who had, as it turned out, ultimately agreed to Crichton’s plan), was about to release an experimental novel about drug dealing that he had co-authored with his brother, and had, since that fateful meeting a year earlier, finished two other pseudonymous potboiler thrillers.
Perhaps most notably, he was also finishing the manuscript for The Terminal Man, his follow-up to The Andromeda Strain. As the Times reports, Crichton had become a “one-man operation” dedicated to this project: in addition to the book, he was simultaneously writing a screenplay adaptation and was determined to direct any resulting movie. To support this latter goal he began spending a couple days every week in Hollywood as part of what he called “a skills-building gambit.” The Times described the 27-year-old’s career as “hyperactive.” This might be an understatement.
It’s interesting to compare Crichton’s rise to that of John Grisham, one of the few novelists of the late 20th century to rival Crichton’s publishing success. Grisham’s ascent began with his second novel, The Firm, which attracted significant interest from publishers after Paramount, based on a bootleg copy of the manuscript, snapped up the film rights for $600,000. The book went on to eventually sell 7,000,000 copies.
It’s here, however, that Grisham’s path diverges from Crichton. As I’ve written about before, instead of embracing a haphazard collection of overlapping projects, Grisham instead built a simplified routine centered on the singular goal of producing one book per year. He typically starts writing on January 1st, working three hours a day, five days a week, in an outbuilding on his farm near Charlottesville, Virginia. He aims to finish the first draft of that year’s book by March and have the manuscript completely done by July. Grisham will conduct a limited publicity tour surrounding the book’s fall release, but otherwise devotes all of his remaining time and energy to non-professional activities, like the youth baseball league he started in 1996. When his longtime assistant retired, Grisham didn’t bother hiring a replacement as there wouldn’t be enough for them to do. The only professional acquaintances who might call were his editor and agent, but they we familiar with his routine, and rarely bothered him.
In Crichton and Grisham we see two different models of ambition. The first model, exemplified by Crichton, is what I call Type 1. It craves activity and feasts at the buffet of appealing opportunities that success creates. The other model, exemplified by Grisham, is what I call Type 2. It craves simplicity and autonomy, and sees success as a source of leverage to reduce stressful obligations. Medical school wasn’t sufficiently stimulating for Crichton. Life as a lawyer was too hectic for Grisham. They therefore reacted to their success in much different ways when it respectively arrived.
As best I can tell, different people are wired for different ambition types. The key seems to be to recognize what type best matches you before success begins to exert significant force on your career. A Type 1 personality stuck in a outbuilding on a farm, quietly writing day after day, will quickly become bored. A Type 2 personality working on a screenplay at the same time as two books while filling weeks with Hollywood meetings will be crushed with anxious unease.
Ambition type mismatch, of course, is a lucky problem to have, as it means that you must be doing something right. But this doesn’t diminish its importance for those that it does impact. It didn’t take me long, for example, to realize I’m more Grisham than Crichton (in terms of personality, not, alas, cumulative book sales). This has likely saved me from untold volumes of unhappy anxiety. If you haven’t yet, now might be a good time to figure out what type you are.
When it comes to the events, the big debate is about the contents of its body. Martin Fowler has written a great post on this topic.
Some devs argue that events should carry the complete load with it, I am calling them Fat Events (Event Carried State Transfer) in this blog.And then we have others who believe that events should be lightweight and containing minimum details, hence I call them Thin Events (Event Notification). In Thin Events, subscriber of the event is expected to request the required data after receiving the event.
Like every other dilemma in choosing suitable design patterns, this is a hard question to answer and it depends on various things. Lets compare them:
Thin Events add coupling which is one of concerns we wanted to address by using events. It forces the event subscriber to call the publisher APIs to get more details. This means a subscriber cannot do its job if the publisher is down. In case of a bulk execution, it can adversely impact the APIs it will be calling. In contrast, Fat Events remove that dependency and lead to a better decoupling of the systems.
The data in any event could be outdated by the time it is processed. This impacts both sides in quite opposite ways. Thin Events shine when the real-time information is crucial at the time of processing while Fat Events work better where sequential or point-in-time processing is required.
Deciding the contents for an event is the part where Thin Events win, simply because it will only contain the bare minimum details for the subscriber to call back if required. But for Fat Events, we will have to think about the event body. We want to carry enough for all the subscribers but it comes at an expense: the publisher model would be coupled to the contract. It also adds an unnecessary dependency to consider in case you want to remove some data from the domain.
Thin Events do not cut it for me
From my experience so far, I think Thin Events does not offer anything that Fat Events cannot. As with Fat Events, the subscriber can also choose to call back the API if needed. In fact, I tried to think of an example where calling back the publisher is the only way to get the real time information but in those cases it felt like the bounded contexts are not cut right. However, in certain circumstances the use case may not allow putting the payload on the events if the published on uncontrolled/unprotected or low bandwidth infrastructure. In those cases event can carry a reference (URI) back to the change (e.g. resource, entity, event etc.).
So are Fat Events the answer?
It depends, though carrying the complete object graph with every event is not a good idea. Loosely coupled bounded contexts are meant to be highly cohesive to act as a whole, so when you create event of a domain model, the question is how far you go in the object graph i.e. to an aggregate, or a bounded contexts or includes entities outside bounded context as well. We have to be very careful, as noticed above, it tightly couple the event contents to your domain model. So we don’t want thin events then how fat our event should be?
There are two further options, event body based on the event purpose (Delta Event) or the aggregate it represents (Aggregate Event).
Delta Events
I am not sure if ‘Delta Events’ is a known term for this, but it is the best name I could think to describe the event contents. The basic concept is to make events carry ‘just enough details’ to describe the change in addition to the identity (Id) of the entities changed. Delta events work even better with the Event Sourcing because they are like a log of what has happened, which is the basic foundation of the Event Sourcing.
So in Delta Events, the contents can consist of:
Public Id of the primary entity, that event is broadcast for.
Fields that have changed in the event.
e.g. AccountDebited
{
AccountHolderUserId: <Account holder Id>
FromAccountNumber: "<Account Number that is debited from>"
ToAccountNumber: "<Account Number that money is credited to>"
Description: "Description of transaction"
AmountDebited: "<Amount that is debited from the account>"
Balance: "<Balance remaining after this transaction>"
TransactionId: "<To correlate with the parent transaction>"
}
The event above carries the complete details to explain what has happened along with the public Id of the entities involved.
Aggregate Event
We can make it a Fat Event and carry the additional content such as the Account holder name for the systems which may need that information e.g. notification, reporting, etc. But unfortunately, that will couple publisher domain unnecessarily to that data it does not need. So to work out the right content for the event, we will apply two key principles:
Domain-Driven Design: Scope the event body to the aggregate level. As Martin Fowlers explains in his post, aggregate is the smallest unit of consistency in Domain-Driven Design.
A DDD aggregate is a cluster of domain objects that can be treated as a single unit.
Data On The Outside: Events are an external interface of our system. So they fall into the “Data On the Outside” category explained in an excellent paper “Data on the Outside versus Data on the Inside” by Pet Helland. Applying the constraints of sharing data outside the bounded context, we will send a complete snapshot of the aggregate, including the fields that didn’t change as part of the event. This allows the consumer to keep the point-in-time reference of the state. I have unpacked this concept in my other post: https://codesimple.blog/2021/03/14/events-on-the-outside-vs-events-on-the-inside/
By following these principles, the body of the event contains the model for the aggregate (i.e. transaction) and a sequence number to highlight the point in time reference to the state of the aggregate.
e.g. AccountDebited
{
Sequence: Timestamp / Sequence Number,
Transaction: {
TransactionId: "<To correlate with the parent transaction>",
FromAccountNumber: "<Account Number that is debited from>",
ToAccountNumber: "<Account Number that money is credited to>",
Description: "Description of transaction",
Amount: "<Amount that is debited from the account>",
Balance: "<Balance remaining after this transaction>"
}
}
How does the subscriber get the missing pieces?
In both above event types, there can be some related information that is not present in the event body e.g. references to entities of other bounded context such as account holder name. It depends on the situation, for a new subscriber you may want to listen to the other events in the system and build a database of the subscriber’s domain.
Let’s assume we have a Notification domain that will send an SMS to the account holder whose account will be debited if the amount to debit is above $100.00. SMS body would be like:
Hi <First Name> <Last Name>,
Your account number <account number> is debited. Transaction details:
Amount: $<amount>
Remaining Balance: $<remaining balance>
Description: $:<Transaction description>
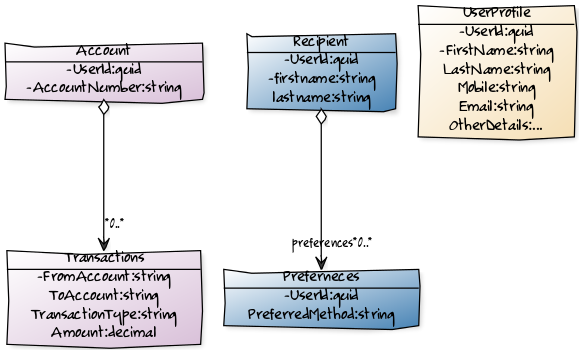
For the sake of an example, lets assume our system is cut into the following sub domains:
User Profile: Maintains account holder details such as Name, Address, Mobile Number and Email etc.
Notification: Maintain user preferences about receiving notifications and sending notifications.
Accounts: Maintain ledger of debits and credits of accounts
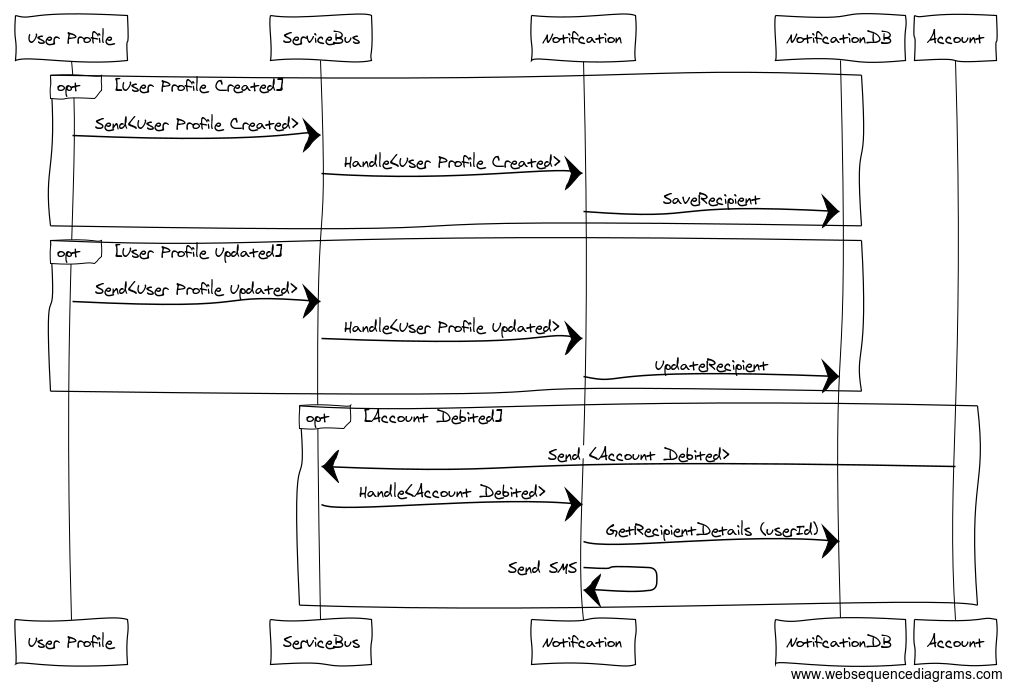
To send the SMS, we have almost all the details in the event body except the account holder name and mobile number of the recipient. In our imaginary system, it is the user profile domain that has those details instead of the accounting domain, that is broadcasting the event. There are two things that can happen here:
Notification domain can call the User Profile to get more details before sending the SMS. So now we always get the up to date contact details of the user but at the cost of run time dependency. If User Profile system is down for any reason, it would break the notification system as well.
OR
We can make the notification system listen to the events from the User Profile system as well to maintain a local database of its recipients (translated from account holders) along with their notification preferences. e.g.
UserProfileAdded
UserProfileUpdated
I prefer the later option to keep the system decoupled and avoid run time dependency. The workflow will be like this:
The subscriber will build the store as they go, but still there can be scenarios where they don’t have this data:
New Subscriber
An event lost for some reason – not sent, not delivered, delivered but failed etc.
For the first scenario you can start with some data migration to give it a seed data, but for the second case data migration may not work. I have dealt with this situation by introducing a snapshot builder.
Snapshot Builder:
If subscriber does not know about the entity it has received in the event, it would call the relevant systems and build a snapshot. This can be quite handy in scenarios where occasionally the subscriber needs to sync its data (translated from other domains) with the original owner of the data.
I hope you find this post useful, if not the complete approach, it may give you some options to consider when thinking about the event contents.
I was recently probing into the Visual Basic 6 format trying to see how the IDispatch implementation resolved vtable offsets for functions.
While digging through the code, I came across several structures that I had not yet explored. These structures revealed a trove of information valuable to reverse engineers.
As we will show in this post, type information from internal structures will allow us to recover function prototypes for public object methods in standard VB6 executables.
This information is related to IDispatch internals and does not require a type library like those found with ActiveX components.
For our task of malware analysis, a static parsing approach will be of primary interest.
Background
Most VB6 code units are COM objects which support the IDispatch interface. This allows them to be easily passed around as generic types and used with scripting clients.
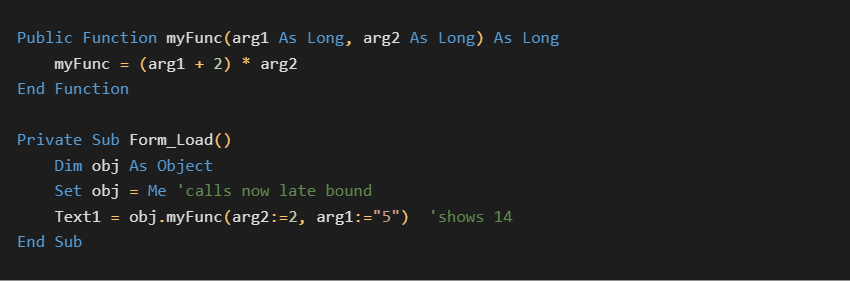
IDispatch allows functions to be called dynamically by name. The following VB6 code will operate through IDispatch methods:
This simple code demonstrates several things:
VB6 can call the proper method from a generic object type
named arguments in the improper order are correctly handled
values are automatically coerced to the correct type if possible (here the string “5” is converted to long)
If we add a DebugBreak statement, we can also see that the string “myFunc” is passed in as an argument to the underlying __vbaLateMemNamedCallLd function. This allows IDispatch::Invoke to call the proper function by string name.
From this we can intuit that the IDispatch implementation must know the complete function prototype along with argument names and types for correct invocation to occur.
We can further test this by changing an argument name, adding unexpected arguments, or setting an argument type to something that can not be coerced too long.
Each of these conditions raises an error before the function is called.
Note that there is no formal type library when this code is compiled as a standard executable. This type information is instead embedded somewhere within the binary itself.
So where is this type information stored, and how can we retrieve it?
The Hunt
If we start probing the runtime at BASIC_CLASS_Invoke we will encounter internal functions such as FuncSigOfMember, EpiGetInvokeArgs, CoerceArg, and so on. As we debug the code, we can catch access to known VB6 structures and watch where the code goes from there.
Before we get deeper, I will give a quick high-level overview of the Visual Basic 6 file format.
VB6 binaries have a series of nested structures that layout all code units, external references, forms etc. They start with the VBHeader and then branch out, covering the various aspects of the file.
In the same way that the Windows loader reads the PE file to set up proper memory layout, the VB runtime (msvbvm60.dll) reads in the VB6 file structures to ready it for execution within its environment.
Good references for the VB6 file format include:
The structure and fields names I use in this document primarily come from the Semi-VBDecompiler source. A useful structure browser is the free vbdec disassembler: http://sandsprite.com/vbdec/
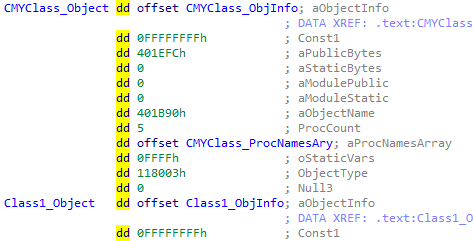
For our work, we will start with the ObjectTable found through the VBHeader->ProjectInfo->ObjectTable.
The ObjectTable->ObjectArray holds the number of Object structures as defined by its ObjectCount field. An example is shown below:
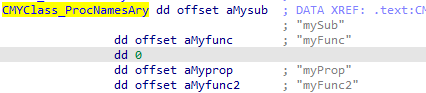
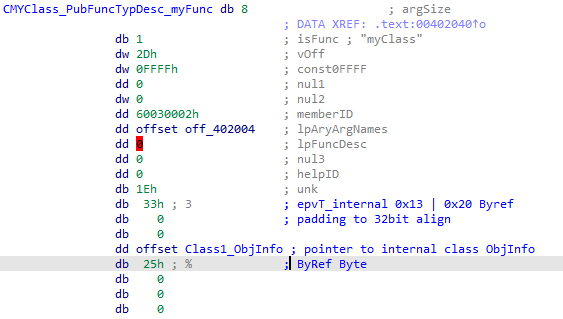
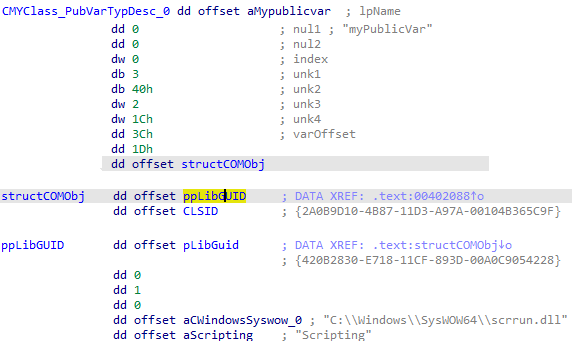
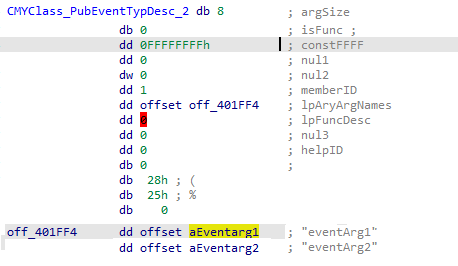
This is the top-level structure for each individual code object. Here we will find the ProcNamesArray containing ProcCount entries. This array reveals the public method names defined for the object.
The Meat
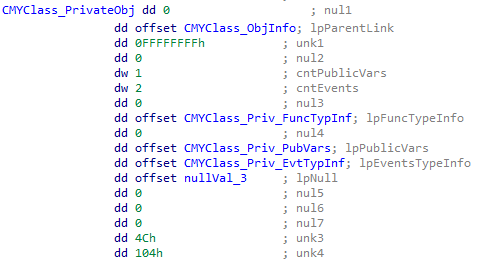
The Object->ObjInfo structure will also lead us to further information of interest. ObjInfo->PrivateObject will lead us to the main structure we are interested in for this blog post.
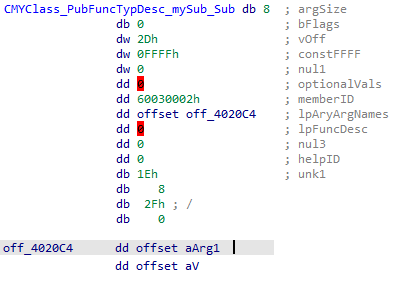
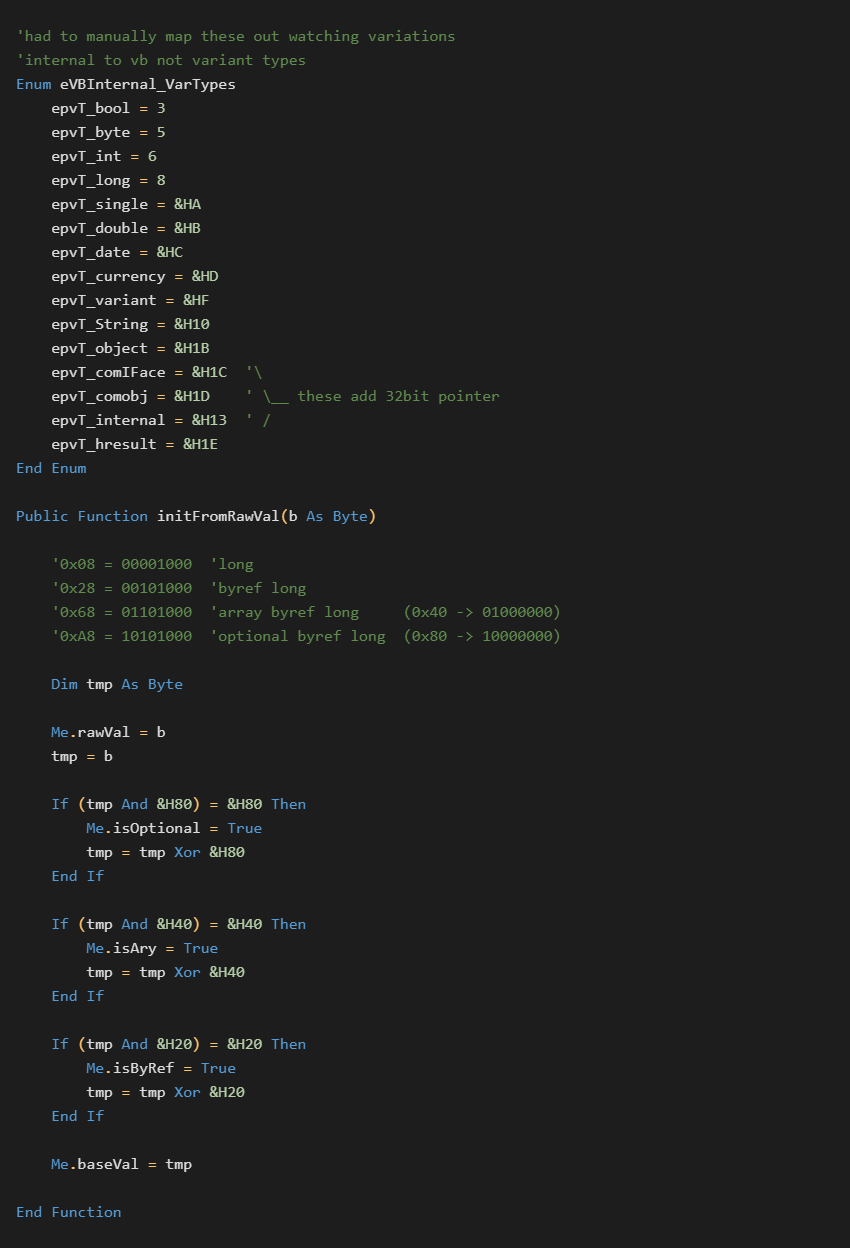
I could not find public documentation on this structure or those below it. What follows is what I have put together through analysis.
Development of this information had me working across four different windows simultaneously.
disassembly of the vb runtime
disassembly of the target executable
debugger stepping through the code and syncing the disasm views
specialized tool to view and search vb6 structures
The following is my current definition of the PrivateObj structure:
In the debugger, I saw vb runtime code accessing members within this structure to get to the vtable offsets for an Invoke call. I then compiled a number of source code variations while observing the effects on the structure. Some members are still unknown, but the primary fields of interest have been identified.
The PrivateObj structure leads us to arrays describing each code object’s public function, variable, and event type information.
Counts for the event and variable arrays are held directly within the PrivateObj itself. To get the count for the public functions, we have to reference the top-level Object->ProcCount field.
Note that there is a null pointer in the FuncType array above. This corresponds to a private function in the source code. If you look back, you will also see that same null entry was found in the ProcNames array listed earlier.
Each one of these type information structures is slightly different. First, we will look at what I am calling the FuncTypDesc structure.
I currently have it defined as follows:
The structure displayed above is for the following prototype:
This structure is where we start to get into the real meat of this article. The number of types defined for the method is held within the argSize field. The first three bits are only set for property types.
111 is a property Set
010 is a property Let
001 is a property Get (bFlags bit one will additionally be set)
The type count will be the remaining bits divided by four.
If the bFlags bit one is set, the last entry represents the method’s return value. In all other scenarios, the types represent the arguments from one to arg count. VB6 supports a maximum of 59 user arguments to a method.
An argSize of 0 is possible for a sub routine that takes no arguments and has no return value.
The vOff field is the vtable offset for the member. The lowest bit is used as a flag in the runtime and cleared before use. Final adjusted values will all be 32-bit aligned.
The optionalVals field will be set if the method has optional parameters which include default values.
LpAryArgNames is a pointer to a string array. It is not null- terminated, so you should calculate the argument count before walking it.
After the structure, we see several extra bytes. These represent the type information for the prototype. This buffer size is dynamic.
A mapping of these values was determined by compiling variations and comparing output for changes. The following values have been identified.
The above code, shows that 0x20, 0x40, and 0x80 bits have been set to represent ByRef, Array, and Optional specifiers. These are combined with the base types identified in the enumeration. These do not align with the standard VARIANT VARENUM type values.
The comobj and internal flags are special cases that embed an additional 32-bit value after the type specifier byte.
This will link to the targets ObjInfo structure for internal objects.
If the comobj type is encountered, an offset to another structure will be found that specifies the objects library guid, clsid, library name, and dll path. We will show this structure later when we cover public variables.
It is important to note that these offsets appear to always be 32-bit aligned. This can introduce null padding between the type byte and the data offset. Null padding has also been observed between individual type bytes as well. Parsers will have to be tolerant of these variations.
Below is the type definition for the following prototype:
Next up comes a quick look at the PubVarDesc structure. Here is a structure for the following prototype:
This example shows flag 0x1D to declare an external COM object type. An offset then follows this to a structure which defines the details of the COM object itself.
The value 0x3c in the varOffset field is where the data for this variable is stored. For VB6 COM objects the ObjPtr() returns a structure where the first member is a pointer to the objects Vtable. The areas below that contain class instance data. Here myPublicVar would be found at ObjPtr()+0x3c.
Finally, we will look at an EventDesc structure for the following prototype:
This structure closely follows the layout of the PubFuncDesc type. One thing to note, however, is that I have not currently been able to locate a link to the Event name strings embedded within the compiled binaries.
In practice, they are embedded after the strings of the ProcNamesArray.
Note that the class can raise these events to call back to the consumer. There is no implementation of an event routine within the code object that defines it.
Conclusion
In this post, we have detailed several structures which will allow analysts to parse the VB object structures and extract function prototypes for public object members.
This type information is included as part of the standard IDispatch plumbing for every user-generated VB6 form, class, user control, etc. This does not apply to functions in BAS code modules as they are not COM objects internally.
It is also interesting to note that VB6 embeds this type data right along with the other internal structures in the .text section of the PE file. No type library is required, and this feature can not be disabled.
While the structures portion of the .text section can contain various compiler-generated native code stubs, all user code falls into the memory range as defined by the VBHeader.ProjectInfo.StartOfCode and EndOfCode offsets.
The framework required to analyze a VB6 binary and resolve the information laid out in this posting can be fairly complex. Luckily open-source implementations already exist to help ease the burden.
Structure and prototype extraction routines have already been included in the free vbdec disassembler. This tool can also generate IDC scripts to apply the appropriate structure definitions to a disassembly.
VB6 binaries are typically considered hard to analyze. Extracting internal function prototypes will be a very welcome addition for reverse engineers.