Here’s a keynote I gave at RubyConf Mini last year: Learning DNS in 10 years. It’s about strategies I use to learn hard things. I just noticed that they’d released the video the other day, so I’m just posting it now even though I gave the talk 6 months ago.
Here’s the video, as well as the slides and a transcript of (roughly) what I said in the talk.
the video
the transcript
You all got this zine (How DNS Works) in your swag bags -- thanks to RubyConf for printing it!
But this talk is not really about DNS. I mean, this is a Ruby conference, right? So this talk is really about learning hard things, and DNS is an example of something that was hard for me to learn.
It took me maybe 16 years from the first time that like I bought a domain name and set up my DNS records to when I really felt like I understood how the system worked.
And one thing I want to say at the beginning of this talk, is that I think that taking like 16 years to learn something like DNS is kind of normal. The idea that "I should understand this already" is a bit silly. For me, I was doing other stuff for most of the 16 years! There was other stuff I wanted to learn.
And so, this talk is not about how you should learn about any particular thing. I don't care if you learn how DNS works! It's really about how to approach learning something hard that's a priority for you to learn.
So, we're going to talk about learning through a series of tiny deep dives. My favorite way of learning things is to do nothing, most of the time.
That's why it takes 10 years.
So for six months I'll do nothing and then like I'll furiously learn something for maybe 30 minutes or three hours or an afternoon. And then I'll declare success and go back to doing nothing for months. I find this works really well for me.
Here are some of the strategies we're going to talk about for doing these tiny deep dives
First, we're going to start briefly by talking about what DNS is.
Next, we're going to talk about spying on DNS.
Then we're gonna talk about being confused, which is my main mode. (I'm always confused about something!)
Then we'll talk about reading the specification, we'll going to do some experiments, and we're going to implement our own terrible version of DNS.
And so what's DNS really briefly? DNS stands for the Domain Name System. And every time you go to a website like www.example.com, your browser needs to look up that website's IP address. So DNS translates domain names into IP addresses. It looks up other information about domain names too, but we're mostly just going to talk about IP addresses today.
I want to briefly sell why I think DNS is cool, because we're going to be talking about it a lot.
One cool thing about DNS is that it's this invisible system that controls the entire internet.
For example, you're on your phone, you're using Google Maps, it needs to know, where is maps.google.com, right? Or on your computer, where's reddit.com? What's the IP address? And if we didn't have DNS, the entire internet would collapse.
I think it's fun to learn how this behind the scenes stuff works.
The other thing about DNS I find interesting is that it's really old. There's this document (RFC 1035) which defines how DNS works, that was written in 1987. And if you take that document and you write a program that works the way that documents says to work, your program will work. And I think that's kind of wild, right?
The basics haven't changed since before I was born. So if you're a little slow about learning about it, that's ok: it's not going to change out from under you.
Next I want to talk about spying on DNS, which is one of my favorite ways to learn about things.
I'm going to talk about two spy tools for DNS: dig and wireshark.
dig is a tool for making DNS queries. We talked about you know, how your browser needs to look up the IP address for maps.google.com. We can do that in dig!
When we run dig maps.google.com, it prints out 5 fields. Let's talk about what those 5 fields are.
I've used example.com instead of maps.google.com on this slide, but the fields are the same. Let's talk about 4 of them:
We have the domain name, no big deal
The Time To Live, which is how long to cache that record for so this is a one day
You have the record type, A stands for address because this is an IP address
And you have the content, which is the IP address
But I think that the funniest field in a DNS record is this field in the middle, IN, which stands for INternet. I guess in 1987, they thought that we might be on a lot of different networks. So they made an option for it. In reality, we're all on the internet. And every DNS query has class set to "internet". There are a couple of others query classes (CHAOS and HESIOD), which truly almost nobody uses.
We can also kind of poke around on the internet with Dig. We've talked about A records to look up IP addresses.
But there are other kinds of records like TXT records. So we're going to look at a TXT record really quickly just because I think this is very fun. We're going to look at twitter.com's TXT records.
So TXT records are something that people use for domain verification, for example to prove to Google that you own twitter.com.
So what you can do is you can set this DNS record google-site-verification. Google will tell you what to set it to, you'll set it, and then Google will believe you.
I think it's kind of fun that you can like kind of poke around with DNS and see that Twitter is using Miro or Canva or Mixpanel, that's all public. It's like a little peek into what people are doing inside their companies
Oh, the other thing about dig is that by default, dig's output looks like this, which is very ugly and unreadable. There's a lot of nonsense here.
So dig has a configuration file, where you can put +noall +answer and then your dig responses look much nicer (like they did in the screenshots above) instead of having a lot of nonsense in them. Whenever possible, I try to make my tools behave in a more human way.
The other thing I want to talk about is Wireshark, which is my favorite computer networking tool in the universe for spying on all things computer networks. In this case, DNS queries. So let's go look at Wireshark.
When we make a DNS query like this and look up example.com, Wireshark can capture it.
When you start looking in the guts of things, I think it can be a bit scary at first. Like what do all these numbers? It kind of seems like a lot. So when I'm looking at something new, I try to start by looking at stuff that I understand.
For example, I know that example.com is a domain name, right? So we should able to use Wireshark to go find that domain name in the DNS query. If we click into the "query" part of the DNS packet, we can see 3 fields that we recognize. First, the domain name.
We can also see the type ("A")
And the third one is the class which is INternet, which is always the same. What I find comforting here is that in the query, there are really only 2 important fields: a DNS query is just saying "I want the IP address for example.com". There's just two fields. And that that always makes me feel a little bit better about understanding something.
A quick caveat: your browser might be using encrypted DNS and spying on your DNS queries with Wireshark will not work if your DNS is encrypted. But there's lots of non-encrypted DNS to spy on.
The second thing I want to talk about for learning new things is to notice when you're confused about something.
I want to tell you a story, "the case of the mysterious caching", of something that happened to me with DNS that really confused me.
First, I want to talk to you a little bit about how DNS works a little bit more. So on the left here, you have your browser. And when your browser makes a DNS query, it asks a server called a resolver. And all you need to know about the resolver is that it's cache, which as we know is like the worst thing in computer science. So the resolver is a cache, and it gets its information from the source of truth, which has the real answers.
So your browser talks to a resolver, which is a cache.
At the time of this story, I had this mental model for like how I thought about DNS, which is that if I set a TTL (the cache time) of 5 minutes when configuring my DNS records, then I would never have to wait more than five minutes. Something you need to know about me is that I'm a very impatient person. And I hate waiting. So this model was mostly working for me at the time, though there are a few other very important caveats that we're not going to get into.
But one day I was setting up a new subdomain for some new project. Let's say it was new.jvns.ca. So I set it up. I made its DNS records, and I refreshed the page. And it wasn't working. So I figured, that's fine, my model says, I only have to wait five minutes, right? Because that's what I was used to. But I waited five minutes and still didn't work.
And I was like, oh, no. My mental model was broken! I did not feel good.
And often when this happens to me, and I think for most of us, if something weird happens with a computer, you let it go, right? You might decide okay, I don't have time to go into a deep investigation here. I'll just wait longer.
But sometimes I have a lot of energy, and maybe I'm feeling mad, like "the computer can't beat me today"! Because there's a reason that this is happening, right? And I want to find out what it is. So this day for some reason. I had a lot of energy.
So I started Googling furiously. And I found a useful comment on Stack Overflow.
The Stack Overflow comment talked about something called negative caching. What's that?
And so here's what it said might be going on. The first time I opened the website (before the DNS records had been set up), the DNS servers returned a negative answer, saying hey,this domain doesn't exist yet. The code for that is NXDOMAIN, which is like a 404 for DNS.
And the resolver cached that negative NXDOMAIN response. So the fact that it didn't exist was cached.
So my next question was: how long do I have to wait for the cache to expire? This brings us to a another learning technique.
I think like maybe the most upsetting learning technique to me is to read a very boring technical document. I'm like very impatient. I kind of hate reading boring things. And so when I read something very boring, I like to bring a specific question. So in this case, I had a specific question, which is how long do I have to wait for the cache to expire?
In networking, everything has a specification. The boring technical documents are called RFC is for request for comments. I find this name a bit funny, because for DNS, some of the main RFCs are RFC 1034 and 1035. These were written in 1987, and the comment period ended in 1987. You can definitely no longer make comments. But anyway, that's what they're called.
I personally kind of love RFCs because they're like the ultimate answer to many questions. There's a great series of HTTP RFCs, 9110 to 9114. DNS actually has a million different RFCs, it's very upsetting, but the answers are often there. So I went looking. And I think I went looking because when I read comments on StackOverflow, I don't always trust them. How do I know if they're accurate? So I wanted to go to an authoritative source.
So I found this document called RFC 2308. In section 3, it has this very boring sentence, the TTL of this record is set to the minimum of the minimum field of the SOA record and the TTL of the SOA itself. It indicates how long a resolver may cache the negative answer.
So, um, ok, cool. What does that mean, right? Luckily, we only have one question: I don't need to read the entire boring document. I just need to like analyze this one sentence and figure it out.
So it's saying that the cache time depends on two fields. I want to show you the actual data it's talking about, the SOA record.
Let's look at what happens when we run dig +all asdfasdfasdfasdfasdf.jvns.ca It says that the domain doesn't exist, NXDOMAIN. But it also returns this record called the SOA record, which has some domain metadata. And there are two fields here that are relevant.
Here. I put this on a slide to try to make it a little bit clearer. This slide is a bit messed up, but there's this field at the end that's called the MINIMUM field, and there's the TTL, time to live of the record, that I've tried to circle.
And what it's saying is that if a record doesn't exist, the amount of time the resolver should cache "it doesn't exist" for is the minimum of those two numbers.
In this case, both of those numbers are 10800. So that's how long have to wait. We have to wait 10,800 seconds. That's 3 hours.
And so I waited three hours and then everything worked. And I found this kind of fun to know because often like if you look up DNS advice it will say something like, if something has gone wrong, you need to wait 48 hours. And I do not want to wait 48 hours! I hate waiting. So I love it when I can like use my brain to figure out that I can wait for less time.
Sometimes when I find my mental model is broken, it feels like I don't know anything
But in this case, and I think in a lot of cases, there's often just a few things I'm missing? Like this negative caching thing is like kind of weird, but it really was the one thing I was missing. There are a few more important facts about how DNS caching works that I haven't mentioned, but I haven't run into more problems I didn't understand since then. Though I'm sure there's something I don't know.
So sometimes learning one small thing really can solve all your problems.
I want to say briefly that there's a solution to this negative caching problem. We talked about how like if you visit a domain that's nonexistent, it gets cached. The solution is if you haven't set up your domain's DNS, don't visit the domain! Only visit it after you set it up. So I've learned to do that and now I almost never have this problem anymore. It's great.
The next thing I want to talk about is doing experiments.
So let's say we want to do some experiments with caching.
I think most people don't want to make experimental changes to their domain names, because they're worried about breaking something. Which I think is very understandable.
Because I was really into DNS, I wanted to experiment with DNS. And I also wanted other people to experiment with DNS without having to worry about breaking something. So I made this little website with my friend, Marie, called Mess with DNS
The idea is, if you don't want to do that DNS experiments on your domain, you can do them on my domain. And if you mess something up, it's my problem, it's not your problem. And there have been no problems, so that's fine.
So let's use Mess With DNS to do a little DNS experimentation
The way this works is you get a little subdomain. This one is chair131.messwithdns.com. And then you can make DNS records on it and try things out. Here we're making a record for test.char131.messwithdns.net, with type A, the IP 7.7.7.7, and TTL 3000 seconds.
What we would expect to see is that if we make a query to the resolver, then it asks kind of like the source of truth, which we control. And we should expect the resolver to make only one query, because it's cached. So I want to do an experiment and see if it's true that we get only 1 query.
So I'm going to make a few queries for it, with dig @1.1.1.1 test.chair131.messwithdns.com. I've queried it a bunch of times, maybe 10 or 20.
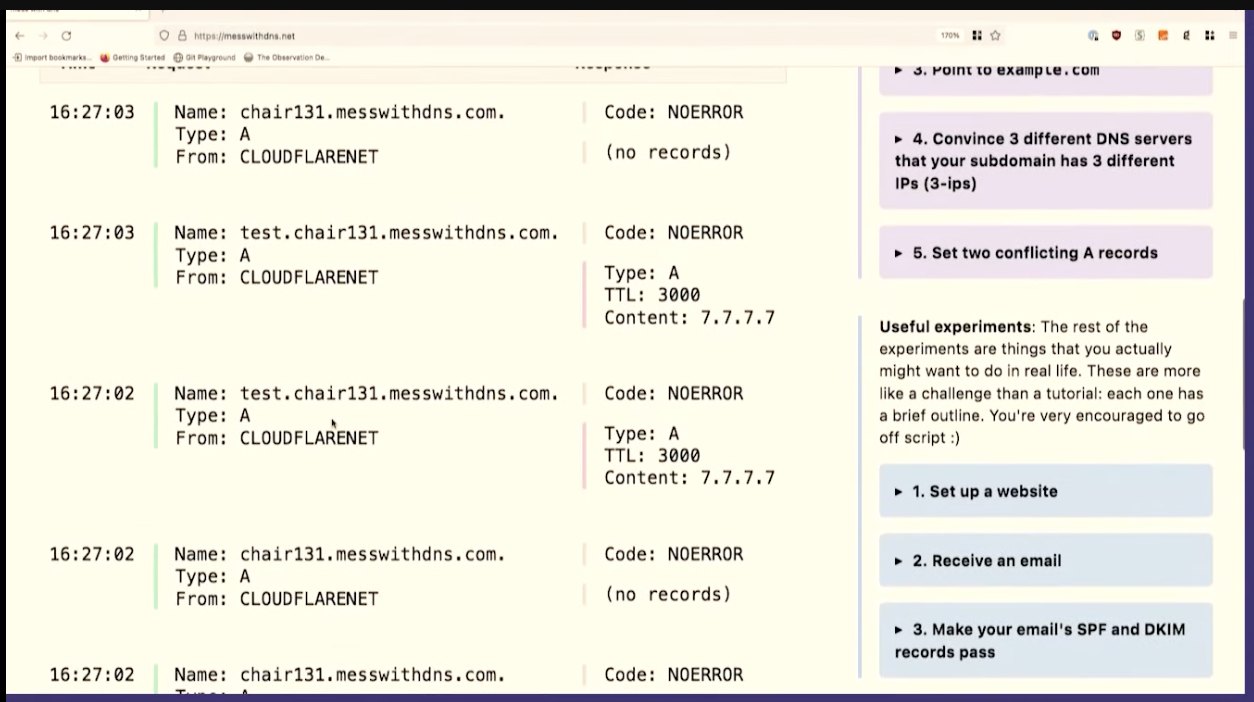
Oh, cool. This isn't what I expected to see. This is fun, though, that's great. We made about 20 queries for that DNS record. The server logs all queries it receives, so we can count them. Our server got 1, 2, 3, 4, 5, 6, 7, 8 queries. That's kind of fun. 8 is less than 20.
One reason I like to do demos live on stage is that sometimes what I what happens isn't exactly what I think will happen. When I do this exact experiment at home, I just get 1 query to the resolver.
So we only saw like eight queries here. And I assume that this is because the resolver, 1.1.1.1, we're talking to has more than one independent cache, I guess there are 8 caches. This makes sense to me because Cloudflare's network is distributed -- the exact machines I'm talking to here in Providence are not the same as the ones in Montreal.
This is interesting because it complicates your idea about how caching works a little bit, right? Like maybe a given DNS resolver actually has like eight caches and which one you get is random, and you're not always talking to the same one. I think that's what's going on here.
We can also do the same experiment, but ask Google's resolver, 8.8.8.8, instead of Cloudflare's resolver.
And we're seeing a similar thing here to what we saw with Cloudflare, there are maybe 4 independent caches.
We could also do an experiment with negative caching, but no, I'm not going to do this demo. Sorry. I could just see it going downhill. The problem is that there's too many different caches, and I really want there to be one cache, but there's like seven. That's fine, let's move on.
Now I'm going to talk about my favorite strategy for learning about stuff, which is to write my own very bad version of the thing. And I want to say that writing my very bad implementation gives me a really unreasonable amount of confidence.
So you might think that writing DNS software is complicated, right? But it's easier than you might think, as long as you keep your expectations low.
To make the DNS queries, the first thing we need to do is we need to make a network connection. Let's do that.
These four lines of Ruby connect to 8.8.8.8, the Google DNS resolver, on UDP port 53. Now we're like halfway there. So after we've made a connection, we need to send Google a DNS query. You might be thinking, Julia, I don't know how to write a DNS query.
But there's no problem. We can copy one from something else that knows what a DNS query looks like. AKA Wireshark.
So if I right click on this DNS query, it's very small, but I'm clicking on "copy", and then "copy as hex stream". You might not know what this means yet, but this is a DNS query. And you might think that like, Hey, you can't just copy and paste something and then send the exact same thing and it'll reply, but you can. And it works.
Here's what the code looks like to send this hex string we copied and pasted to 8.8.8.8.
So we take this like hex string that we copy and pasted, and paste it into our tiny Ruby program, and use `.pack` to convert into a string of bytes and send it.
Now we run the Ruby program.
Let's go to Wireshark and look for the packet we just sent. And we can see it there! There's some other noise in between, so I'll stop the capture.
We can see that it's the same packet because the query ID matches, B962.
So we sent a query to Google the answer server and we got a response right? It was like this is totally legitimate. There's no problem. It doesn't know that we copied and pasted it and that we have no idea what it means!
But we do want to know what this means, right? And so we'll take this hex string and split it into 2 parts. The first part is the header. And the second part is the question, which contains the actual domain name we're looking up.
We're going to see how to construct these in Ruby, but first I want to talk about what a byte is for one second. So this (b9) is the hexadecimal representation of a byte. The way I like to look at figure out what that means is just type it into IRB, if you type in 0xB9 it'll print out, that's the number 184.
So the question is 12 bytes
Those 12 bytes correspond six numbers, which are two bytes each. So the first number is the thing b962 which is the query ID. The next number is the flags, which basically in this case, means like this is a query like hello, I have a question. And then there's four more sections, the number of questions and then the number of answers. We do not have any answers. We only have a question. So we're saying, hello, I have one question. That's what the header means.
And the way that we can do this in Ruby, is we can make a little array that has the query ID, and then these numbers which correspond to the other the other header fields, the flags and then 1 for 1 question, and then three zeroes for each of the 3 sections of answers.
And then we need to tell Ruby how to take these like six numbers and then represent them as bytes. So n here means each of these is supposed to represent it as two bytes, and it also means to use big endian byte order.
Now let's talk about the question.
I broke up the question section here. There are two parts you might recognize from example.com: there's example, and com. The way it works is that first you have a number (like 7), and then a 7-character string, like "example". The number tells you how many characters to expect in each part of the domain name. So it's 7, example, 3, com, 0.
And then at the end, you have two more fields for the type and the class. Class 1 is code for "internet". And type 1 is code for "IP address", because we want to look up the IP address. is
So we can write a little bit of code to do this. If we want to translate example.com into seven example three column zero, can like split the domain on a dot and then like get its length and concatenate that together and put a 0 on the end. It's just a little bit of Ruby. how to encode a domain name.
And then we can wrap all this up together where we make a random query ID. And then you make the header, encode the domain name, and then we add the type and the class, 1 and 1, and then we can just concatenate everything together and that's our query.
There's definitely more work to do here to print out the response, but I wrote a 120-line Ruby script that parses the response too, and I want to show you a quick demo of it working.
What domain should we look up>. rubyconfmini.com. All right, let's do it. Hey, it works!
We're at the end! Let's do a recap.

Okay. Let's go over the ways we've talked about learning things!
First, spy on it. I find that when I look at things like to see like really what's happening under the hood, and when I look at like, what's in the bytes, you know what's going on? It's often like not as complicated as I think. Like, oh, there's just the domain name and the type. It really makes me feel far more confident that I understand that thing.
I try to notice when I'm confused, and I want to say again, that noticing when you're confused is something that like we don't always have time for right? It's something to do when you have the energy. For example there's this weird DNS query I saw in one of the demos today that I don't understand, but I ignored it because, well, I'm giving a talk. But maybe one day I'll feel like looking at it.
We talked about reading the specification, which, there are few times I feel like more powerful than when I'm in like a discussion with someone, and I KNOW that I have the right answer because, well, I read the specification! It's a really nice way to feel certain.
I love to do experiments to check that my understanding of stuff is right. And often I learn that my understanding of something is wrong! I had an example in this talk that I was going to include and I did an experiment to check that that example was true, and it wasn't! And now I know that. I love that experiments on computers are very fast and cheap and usually have no consequences.
And then the last thing we talked about and truly my favorite, but the most work is like implementing your own terrible version. For me, the confidence I get from writing like a terrible DNS implementation that works on 11 different domain names is unmatched. If my thing works at all, I feel like, wow, you can't tell me that I don't know how DNS works! I implemented it! And it doesn't matter if my implementation is "bad" because I know that it works! I've tested it. I've seen it with my own eyes. And I think that just feels amazing. And there are also no consequences because you're never going to run it in production. So it doesn't matter if it's terrible. It just exists to give you huge amounts of confidence in yourself. And I think that's really nice.
That's all for me. Thank you for listening.
thanks to the organizers!
Thanks to the RubyConf Mini organizers for doing such a great job with the conference – it was the first conference I’d been to since 2019, and I had a great time.
from Hacker News https://ift.tt/Rg1Pwf6
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.