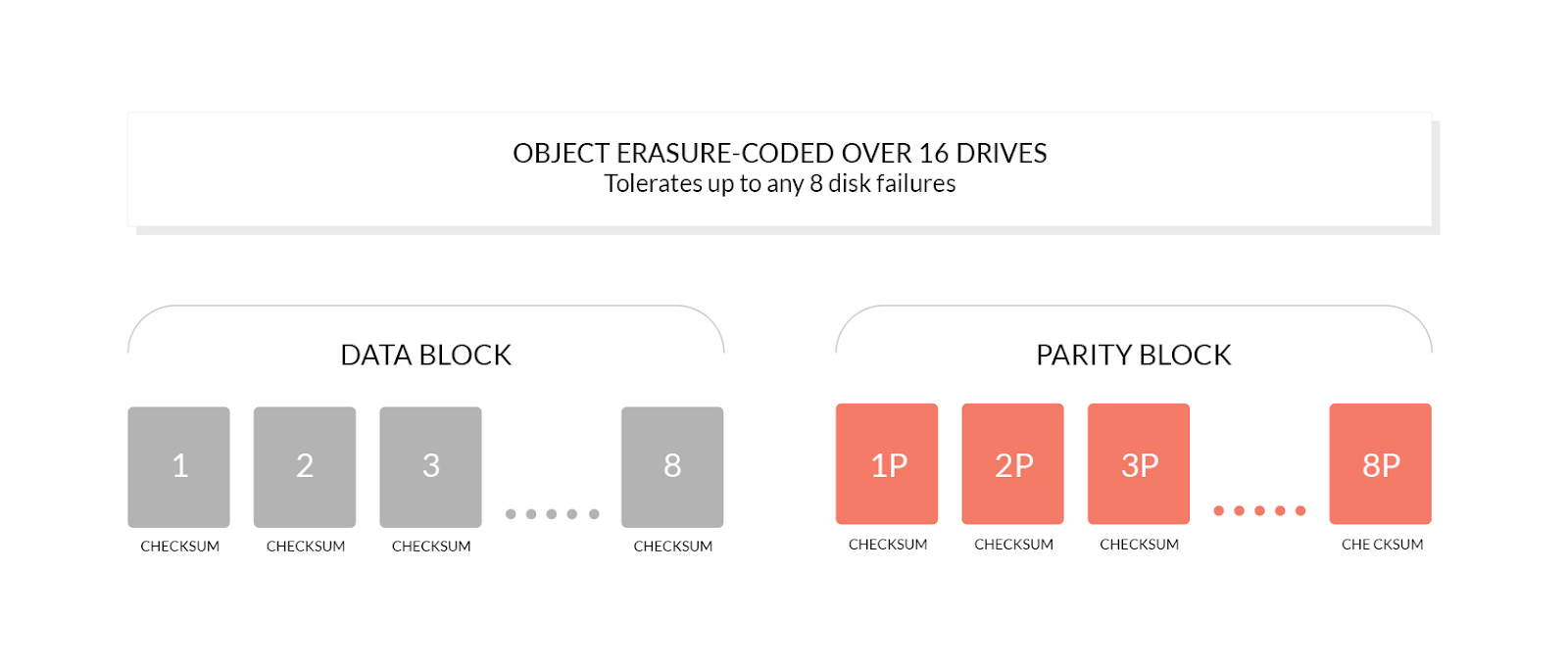
Erasure Coding is a feature at the heart of MinIO. It is one of the cornerstones that provides high availability to distributed setups. In short, objects written to MinIO are split into a number of data shards (M). To supplement these we create a number of parity shards (K). These shards are then distributed across multiple disks. As long as there are M shards available the object data can be reconstructed. This means we can lose access to K shards without data loss. For more details, please see Erasure Coding 101.
Erasure Coding has traditionally been seen as a CPU intensive task. Therefore, hardware dedicated to creating erasure codes exists. However, MinIO does not utilize such hardware, so is that something that should be a concern in terms of performance?
In 2006 Intel released Supplemental Streaming SIMDExtensions 3, commonly referred to as SSSE3. Several years later it was discovered that a particular instruction in SSSE3 could be used to speed up erasure coding by nearly an order of magnitude. Since then Intel has released Galois Field New Instructions (GFNI) that further accelerated these computations by approximately 2x.
These innovations, coupled with software that could take advantage of the extensions made Erasure Coding feasible without specialized hardware. This is important to us, since one of our primary goals is to make MinIO perform well on commodity hardware. That said, let us explore actual performance.
Test Setup
To test performance across a variety of platforms we created a small application and an accompanying script that benchmarked performance in a scenario realistic for MinIO.
- Block size: 1MiB
- Blocks: 1024
- M/K: 12/4, 8/8, 4/4
- Threads: 1->128
All MinIO objects are written in blocks up to 1MiB, which is divided by the number of drives we are writing data shards to. So we keep this number constant for our tests.
The benchmark operates on 1024 blocks. This means that input is 1GiB of data. This is to eliminate CPU caches from the equation. We do this to test worst case performance, and not only performance when data is in L1/L2/L3 cache.
CPUs were selected to give an overall picture of performance across various platforms.
See the end of the article for a link to the measured data.
Benchmarks
We measured encoding and decoding speed across three different erasure code configurations.
Encoding 12+4
First we look at encoding speed with a setup where objects are sharded across 16 disks. With default settings MinIO will split the data into 12 shards and create 4 parity shards. We will look at the speed using a different number of cores for calculations. This is the operation performed when uploading objects to MinIO. To make it easily comparable to NIC speeds we show speed in gigabits per second.
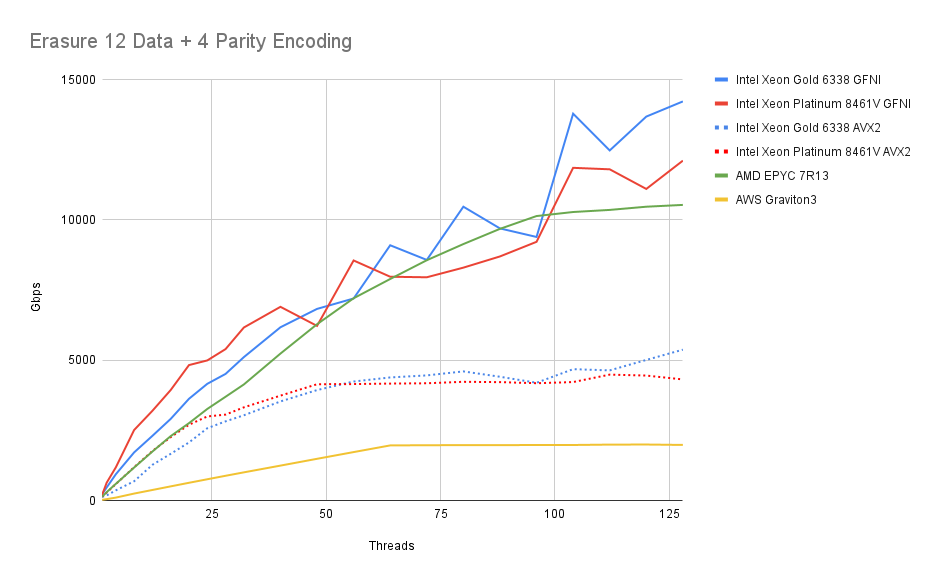
In this chart, we can see that we quickly outperform a top-of-the-line 400Gibps NIC - in fact all x86-64 platforms can do this using less than 4 threads, with the Graviton 3 needing approximately 16 cores.
The older dual-socket Intel CPU can just about keep up with the newer generation single socket Intel CPU. AMD is keeping up well with Intel, even though GFNI isn’t available on this CPU generation. For curiosity, we also tested the Intel CPUs without GFNI, using only AVX2.
We see the Graviton 3 maxing out when we reach its core count, as we’d expect.
Decoding 12+4
Next we look at performance when reconstructing objects. MinIO will reconstruct objects even if it is not strictly needed in cases where a local shard contains parity to reduce the number of remote calls.
The setup is similar to above. For each operation 1 to K (here 4) shards are reconstructed from the remaining data.
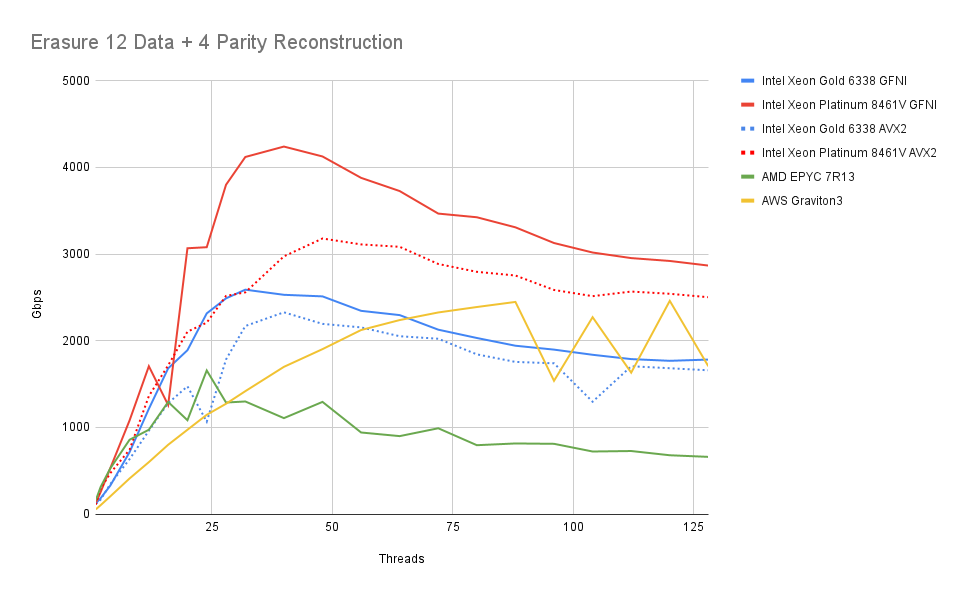
First of all, we observe that we very quickly get above the maximum NIC speed we can expect to encounter. This will, in practice, mean that CPU utilization from Erasure Coding will never consume more than a few cores on any setup.
We can also see that performance decreases slightly as the number of cores utilized goes up. This is likely a result of memory bandwidth contention. As mentioned above it is unlikely that any server will get into this range of utilization due to other system bottlenecks.
8 Data + 8 Parity
Another setup we investigate is a 16 drive setup, with each object being divided into 8 data shards and having 8 parity shards created.
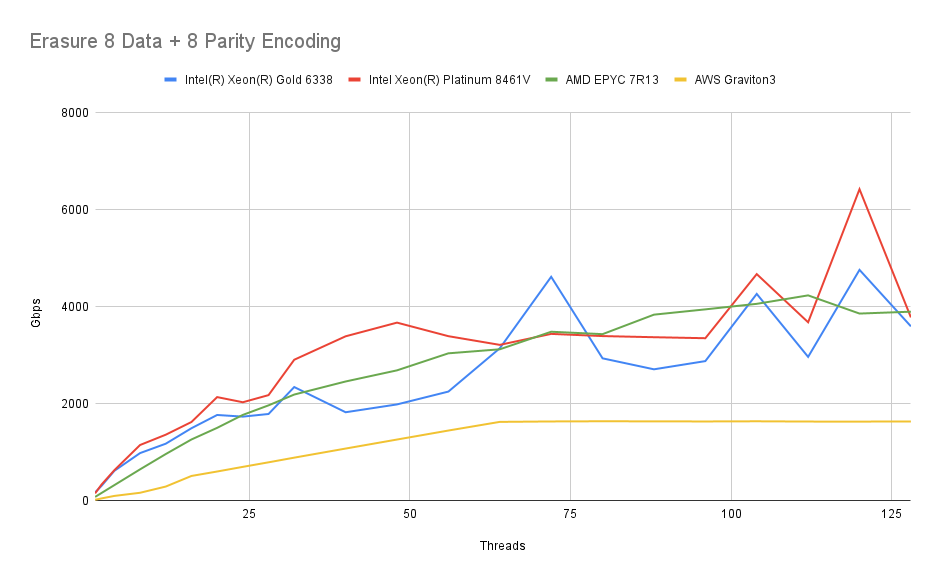
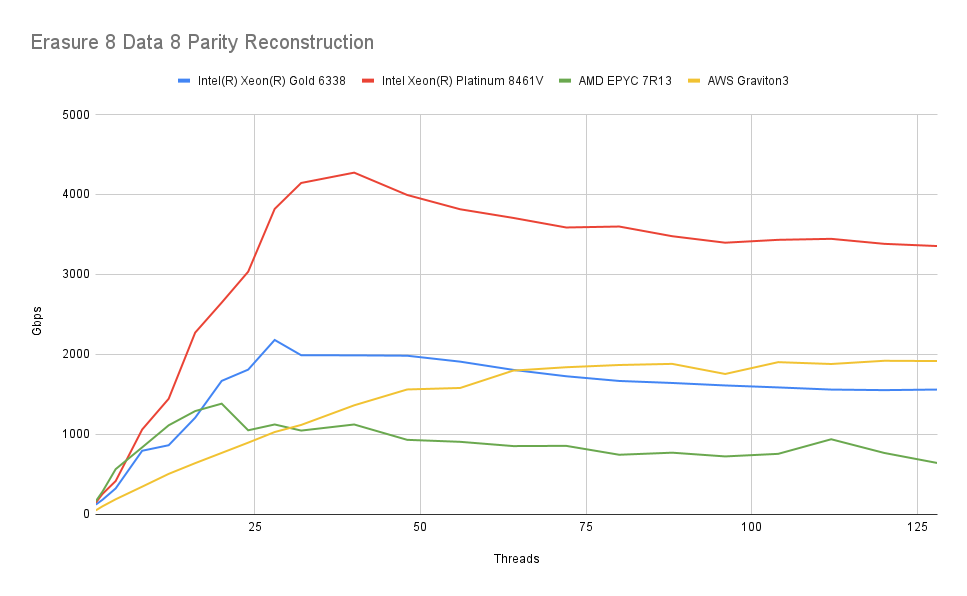
We observe a similar pattern with a slightly higher fall-off in speed. Presumably, this is due to the higher amount of data that is written for each operation. But there’s nothing alarming about the fall-off, and reaching the speed of a 400 GbE NIC should not be an issue.
4 Data + 4 Parity
Finally we benchmark a setup where objects are split into 4 data shards and 4 erasure shards:
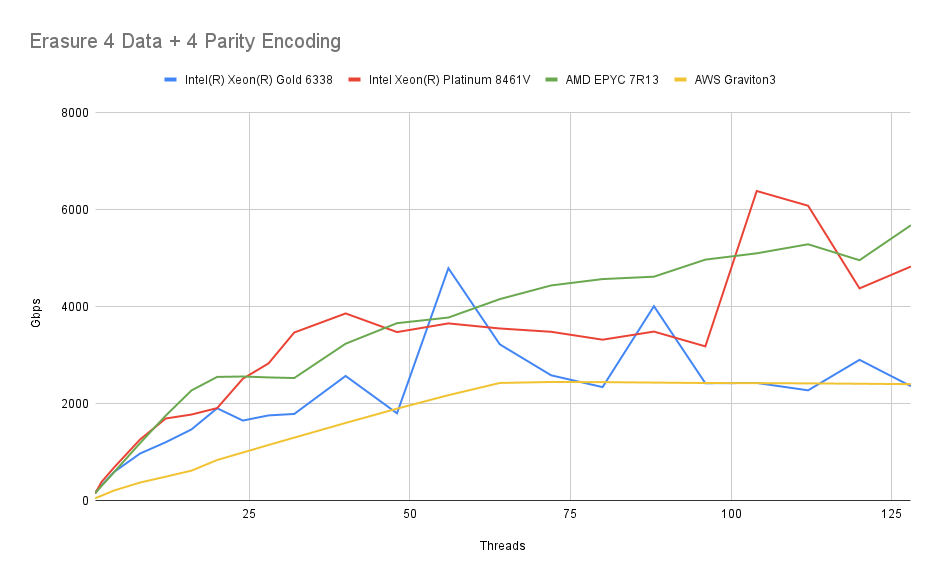
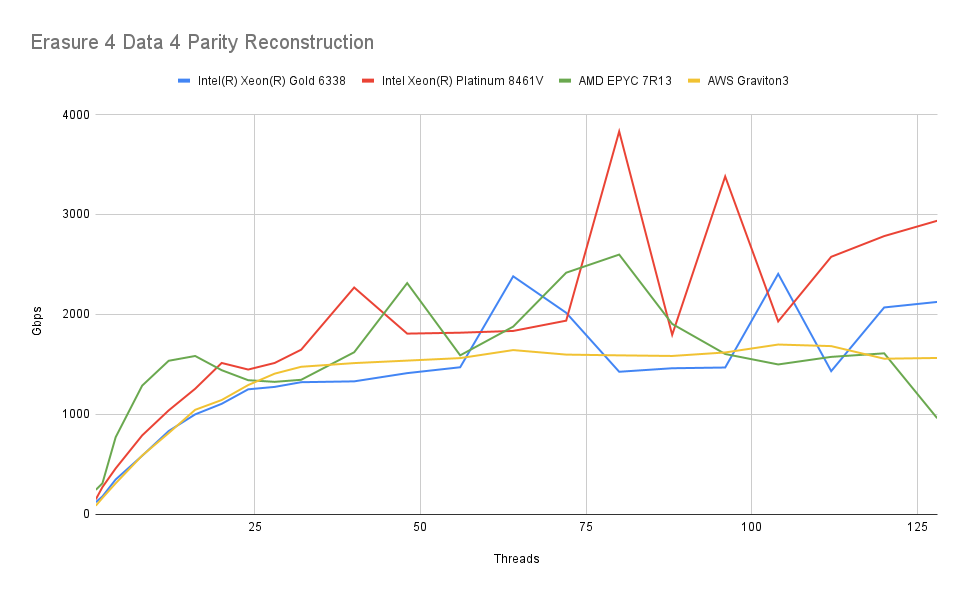
The picture remains similar. Again, neither reads nor writes present a significant load for any of these modern CPUs.
You can find complete test results here.
Analysis and Conclusion
With this test we were looking to confirm that Erasure Coding on commodity hardware can be every bit as fast as dedicated hardware - without the cost or lock-in. We are happy to confirm that even running at top-of-class NIC speeds we will only use a minor fraction of CPU resources for erasure coding on all of the most popular platforms.
This means that the CPU can spend its resources on handling IO and other parts of the requests, and we can reasonably expect that any handling of external stream processors would take at least an equivalent amount of resources.
We are happy to see that Intel improved throughput on their latest platform. We look forward to testing the most recent AMD platform, and we expect its AVX512 and GFNI support to provide a further performance boost. Even if Graviton 3 turned out to be a bit behind, we don’t realistically see it becoming a significant bottleneck.
For more detailed information about installing, running, and using MinIO in any environment, please refer to our documentation. To learn more about MinIO or get involved in our community, please visit us at min.io or join our public slack channel.
from Hacker News https://ift.tt/KmYMrnv
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.