Writing Rust is pretty neat. But you know what's even neater? Continuously testing Rust, releasing Rust, and eventually, shipping Rust to production. And for that, we want more than plug-in for a code editor.
We want... a workflow.
Why I specifically care about this
This gets pretty long, so if all you want is the advice, feel free to jump to it directly.
I owe you all an explanation.
When I started my Patreon, I didn't know where it would take me, but I knew this: that I wanted to go deep.
And sweet mercy, deep we've gone indeed.
We've read files the hard way, we've made our own ping, and we've even made our own executable packer.
These epics went places. And they were a lot of fun to write! But they've not been lot of fun to maintain. When I started the executable packer series for example, the nom crate was still at version 5.x.
Before I finished the series, nom 6.x came out, with a slightly incompatible API, and folks who were just now starting to follow the series ran into compilation errors. Shortly after the series finished, nom 7.x came out!
Updating an 18-part series is a lot of manual work. I basically have to follow the series again from scratch, bumping crate versions as I go along, updating any error messages, explanations, terminal outputs, etc. It doesn't take quite as long as writing the series in the first place, but it's up there.
And as I write more and more series, the problem will only become worse!
I want those series to remain relevant, and somewhat up-to-date with current versions of the crates, tools and operating systems that we use in them. But I fear that, over time, I'll have to spend so much time maintaining existing series, that I won't have any time left to write new ones! And that would be bad.
Uh oh... are you announcing your retirement?
Oh, no no cool bear. Quite the opposite. I'm doubling down. I have a plan. I won't go into too many details yet, but I'm thinking of... a system. To make those series reproducible. And allow me to more easily upgrade them.
Oh... oh god, do you mean...
Yes! That the markdown sources should be the only source code for a series, and that Rust files, terminal sessions, even screenshots should be "build artifacts", that can all be produced from the markdown by my content pipeline.
That's... radical? But I can already think of so many cool things this would allow, iff you don't burn out before getting it to a point where it's useful.
This seems like a lot of work!
It is! It is an incredible amount of work. I mean, my whole content pipeline (which I've already improved on) is already, let's say, "a little more involved" than most blogs out there. But its main focus was on letting me write articles and series quickly, not on maintaining them easily.
And because it's an incredible amount of work, my only chance of making it happen relies on these two things:
- The work needs to be split into smaller, achievable bits
- I'm going to need the best tooling and the best practices I know of
And that first point is why, for example, I've recently written about Linux terminals. I got a bunch of grief for the intro, like: "what kind of asshole needs to looks at large JSON files from a terminal with colors?"
It's me! I'm the asshole. But that's only because I want to write some commands in my markdown sources, and have my content pipeline execute them, and since I'm making everything reproducible / automated, it might as well capture colors as well, so that I can stop apologizing for the lack of colors and tell the reader to "just trust me, the colors are great" and then surrender and just include a screenshot.
Ah. So every bit of research you do to make that "reproducible content pipeline", you write an article about?
Yes! Because there's no guarantees I'll ever finish it, or how long it'll take me. And I want to keep publishing articles while I'm working on that, because folks support me financially every month. And although they're the nicest folks and always tell me to "take it easy", I still feel like a very long gap in content is not really what any one of them signed up for.
Which brings me to the second point... tooling.
The subject of this article I assume?
Correct!
Because folks support me financially every month to write content, I feel like I have to continuously put out content (that is "the deal").
But thanks to folks supporting me financially every month to write content, I can actually invest in a proper setup to develop my writing/editing/publishing tools. Just like I do in my day job.
One-time efforts
When I got tired of hopping between static site generators and rewrote my whole site in Rust, I had no idea whether it would even work! So I didn't really take the time to set up things all nice-like for myself.
I had a fairly good idea of what I wanted out of a somewhat-static site generator, and I went and wrote it.
This gave me futile, currently around 8K lines of code, which uses SQLite, a markdown parser, a syntax highlighter, a templating system, Patreon and Reddit API clients, an http server and a few other components, and now whenever I want to write content, I do this...
Shell session$ futile serve
...in my fasterthanli.me repository, and I have an exact replica of my website, but locally. My local config has "drafts" and "future articles" enabled, so I can iterate on them (and even commit them) before they get deployed to production.
For quick iteration, futile watches for file changes and triggers a browser reload (in development), which means that most of the time, I have VS Code to the left of me, Chromium to the right, here I am, stuck in the middle with you.
On a large-ish dedicated server somewhere, I also have an instance of futile running as well, and it is also watching for file changes (although it doesn't trigger live-reloads), which means that my "deploy process" for content is really just running:
Shell session$ ssh ftl "bash -c 'cd ~/fasterthanli.me; git pull'"
The production instance of futile detects file changes, and in the background, starts processing those assets, and when it's done, atomically switches over to a new "deploy". Each deploy points to a set of content-addressed resources, so there's no downtime whatsoever.
Deploying a new version of futile is a bit more complicated, but not that much: I pull futile on the server, rebuild it, save the older binary just in case, restart a systemd service, and if it breaks I restore the saved binary and investigate. It's not even using any fancy systemd socket activation stuff. I can live with the occasional one-second "downtime", given that it's all behind Cloudflare anyway.
For diagrams, I use diagrams.net (née "draw.io"). Originally, because I wanted to go fast, I was just taking "area screenshots" of bits of those diagrams, and saving those as .png in my content repository.
But this had several issues! Any time I wanted to update a diagram, I had to redo the screenshot, and it made the content repository a little heavier every time. It also didn't look great on high-DPI screens, and it wasn't dark-mode friendly either, since each diagram screenshot had a white background.
Instead, I figured out a pipeline from .drawio files to .pdf, then .svg, then optimized .svg, that involves a bunch of different tools. I didn't want to have to run all these steps by hand, so I came up with another tool, salvage.
It's basically a glorified build tool, but it's smart enough to, for example, only rebuild content when its seahash has changed (so it pairs very well with watchexec-cli):
Shell session$ watchexec salvage . 2021-10-26T22:47:52.354350Z INFO salvage: Workspace: /home/amos/bearcove/fasterthanli.me/content/articles/my-ideal-rust-workflow/assets => /home/amos/bearcove/fasterthanli.me/content/articles/my-ideal-rust-workflow/assets
salvage also knows how to find and run the Windows versions of some tools (from within WSL2), which is necessary because some of these tools need a GUI, or some fonts to be installed.
I later realized salvage was the perfect place to convert .png files to some other formats: .avif for the cutting-edge browsers out there, .webp as a middle-of-the-road compromise, and .jpg as a previous-decade fallback.
(Right now, salvage is around 900 lines of code).
Dreaming bigger
I've been happy with this content pipeline for a while, but as mentioned, I want more. I want something radical, like "the markdown sources actually contains human-readable diffs and my tooling knows how to apply them so I can check out the source code at any point in the series" radical.
But there's much lower-hanging fruits! Even with a tool like salvage, every time I set up a new computer, or re-install one, I have to spend forever installing tooling, like draw.io, inkscape, svgo, avifenc, cwebp, imagemagick, and some fonts!
And as I'm sure you've noticed, the .png/.avif/.webp/.jpg situation isn't ideal either, because I end up committing four files for every image asset to my content repository. That's good for bandwidth when serving the site, but it does make the repository a little heavy: right now, it's 974MiB.
A much better solution would be to only store the sources: .drawio files and .png files, and to just build the outputs on-demand. As a service, you might say.
And I would've done it that way to begin with if I hadn't been a true pragmatist: back when I moved from hugo to something completely hand-made, I was afraid of burning out then too! I had no idea if it was even going to work!
So, you may stop judging me now, and instead applaud how incremental this whole endeavor has been.
But now that it's been working solidly for over a year, I see those low-hanging fruits, and I want them. But I also look to the future, and I'm thinking: I've spent so much time making our Rust development environment nicer at my day job.
Together with colleagues, we've optimized CI, set up caching, release automation, bot-driven dependency upgrades, etc. I'm going to iterate a lot more on my own stuff for this website so... why not just treat myself? Why not try and be just as professional as I'm being at my day job?
And so, without further ado, I present to you (and you may not like it, but this is...) what peak Rust looks like. For me!
Code editor
I've been using Visual Studio Code for a long while. I refer to it, lovingly, as "no one's favorite code editor". I still use Vim keybindings for it, and the illusion is far from perfect, but it has:
- First-class support for language servers like rust-analyzer
- A decent markdown preview
- A decent Git UI
- Support for Dev containers, SSH remotes, WSL remotes, etc.
- An integrated terminal, split panes support
- Great project-wide search & replace (with regex support)
- A bunch of very useful extensions, like Error Lens and Git Lens
- ...and many other things I now take for granted
You can take a look at my user settings if you want — really the main thing of interest in there is how I set up t j as a shortcut for "next tab" for example, or meta g for "Go to definition". I hardly ever have to use the mouse.

Repositories
All repositories related to my website now live in the bearcove GitHub organization.
There's only one public repository out there, for bearcove.net, the rest is all private.
Open-source is... complicated. Developing software for yourself vs maintaining it for the whole community are two very different things.
The financial support from the Patreon goes towards "producing content", and the tooling discussed above is just a prerequisite. The funding isn't for getting into endless arguments about "how things should be done" or spending an exponential amount of time reviewing PRs that take each project in twelve different directions.
When discussing that online, there's exactly two reactions: "what are you talking about, open source is a great way to stay in shape", and "oh god yes, never again unless a company is contracting me for it" and in this house we're firmly in the second category.
If you're still hesitant, please work under the assumption that various options have been considered, and out of "this not happening at all" vs "keeping everything private", the second was chosen.
Which is a boon for this article, because it means we need to showcase how to make that happen without relying on every platform's "open source" tier while keeping costs at a minimum, so this advice applies to small-to-medium companies as well!
GitHub's "Free" plan now includes unlimited private/public repositories, and unlimited collaborators for private repositories, so for our purposes, it's quite enough.
A bunch of PR-related features (like draft PRs, required reviews, required checks etc.) are locked behind "Team" so if I start contracting out folks to help me out on various pieces, I may have to upgrade, but at $4 per user per month, it's not a big ask. The CI situation is different, but we'll get to it later.
Every repository should have a README.md file quickly explaining "why does this exist", "what does this assume / rely on", and maybe "how is this built and where is it used".
Here's the README current for salvage: it's not great yet, but it's a start.

Building, checking, testing, linting
The first low-hanging fruit for any Rust repository is to add a rust-toolchain.toml file.
It could be as simple as this:
TOML markup[toolchain] channel = "1.56.0" components = [ "rustfmt", "clippy" ]
(If you're reading this from the future, I'm sure 1.56.0 is outdated by now. You can always check What Rust is it? to know what the latest version is).
Although various Linux distributions are now starting to ship Rust toolchains in one way or the other, for me, rustup is the gold standard.
With only rustup installed, a toolchain file make sure that commands like cargo work out of the box. If the required version is not installed, rustup seamlessly downloads and installs it before running.
To pin even more versions, the Cargo.lock file should be committed, but only for bin crates (not for lib crates), then --locked should be used whenever possible: for cargo install, cargo check, etc.
Speaking of cargo check — I never use it. cargo clippy does everything and more. In VS Code this means setting "rust-analyzer.checkOnSave.command": "clippy", and from the terminal, this means my check command is:
Shell session$ cargo clippy --locked -- -D warnings
-D warnings "denies warnings", turning them into errors. They're still warnings in my code editor, but in the terminal and in CI (Continuous Integration) I only want the check command to exit with a 0 status if there were no warnings at all.
There's other ways to deny warnings, like exporting RUSTFLAGS. Unfortunately, this will overwrite any rust flags set in .cargo/config.toml for example.
When upgrading between Rust versions, new warnings are born (another reason to pin the Rust version), but luckily cargo fix and cargo clippy --fix can do a lot of the heavy lifting there, which beats going through each warning from VS Code and hitting ctrl+period, applying fixes one by one.
Some of my Rust repositories are cargo workspaces, containing multiple crates, some of which have different cargo features. Checking only with "all features" or "default features" or "no default features" is missing some potential combinations.
To make sure I'm checking all possible combinations, ie. the "feature powerset", I use cargo-hack:
Shell session$ cargo hack --feature-powerset --exclude-no-default-features clippy --locked -- -D warnings
Of course, that's a little long-winded... so instead of typing everything by hand, I have a Justfile.
just is a command runner. A Justfile looks superficially like a Makefile, except there's no implicit rules, no dependency tracking, no strange GNU-only syntax, no quadruple-quoting - it's nice and refreshing!
It literally is "just a bunch of targets" and each target is actually shell, or other languages — I occasionally throw some javascript in there, for complicated tasks.
So, for a simple crate, the Justfile might be just this:
Justfile# just manual: https://github.com/casey/just/#readme _default: @just --list # Runs clippy on the sources check: cargo clippy --locked -- -D warnings # Runs unit tests test: cargo test --locked
Running just just gives a nice list:
Shell session$ just Available recipes: check # Runs clippy on the sources test # Runs unit tests
And running just check does what you think it would. If I'm in my ~/bearcove directory, I can run just futile/check or just salvage/check for example, where futile/ and salvage/ are directories.
just supports .env files, variables, has a few built-in functions for system information, environment variables, directories, string and path manipulation, it even has conditionals. So I guess you could say it has a bunch of specific syntax — but overall I find it a lot less surprising than GNU make idioms. Your mileage may vary.
The nice thing about having recipes like just check, just test, is that they work both locally and in CI — but we'll get to CI later.
Let's talk about Cargo.toml. The defaults are relatively solid, but there's a few tips nonetheless.
For workspaces, the v2 resolver fixes many subtle issues the v1 resolver had. If you don't know what those are, count your blessings, and use it anyway.
It's the default starting with the 2021 edition of Rust, but if you're stuck with edition 2015 or 2018, in your top-level Cargo.toml, simply have:
TOML markup[workspace] members = [...] resolver = "2" # yes, as a string
If you're going to need to debug software in production, or even just profile it, you'll probably want debug information. debug = 2 is "a bit much", and debug = 1 is probably enough for most use cases.
I've also made it a habit to turn off LTO completely (link-time optimization) and turn on incremental compilation for release builds, locally:
In either the top-level Cargo.toml, or the only Cargo.toml if we're talking about a single-crate repository, I have:
TOML markup[profile.release] debug = 1 incremental = true lto = "off"
All these settings together reduce compile time for local release builds. ThinLTO is faster than full LTO, but still slower than "no LTO at all". Incremental compilation removes "optimization opportunities" but is faster for rebuilds.
Speaking of faster rebuilds: in 2021, the GNU linker (GNU ld) is far from being the fastest. The current fastest is the mold linker, but it's still in early stages, doesn't support all platforms / features. If you're targeting Linux x86_64 only and aren't doing something too fancy at link time, it might work for you!
In the meantime, I find LLVM's linker (lld) to be a happy middle ground: faster than GNU ld, still runs everywhere and I've never been able to blame it for a link failure.
I set it in .cargo/config.toml (that's relative to the repository root — not in my home directory).
TOML markup# in .cargo/config.toml [target.x86_64-unknown-linux-gnu] rustflags = [ "-C", "link-arg=-fuse-ld=lld", ] # (repeat for other targets as needed)
In a CI environment, where "actual" release builds are made (those that will be deployed on a server), I override these settings by exporting environment variables:
bash# Turn incremental compilation off export CARGO_INCREMENTAL=0 # Turn on ThinLTO export CARGO_PROFILE_RELEASE_LTO=thin
For production release builds made in CI, I also want to:
- Compress debug sections (so the resulting executables are still debuggable, but not awfully large)
- Force frame pointers (the equivalent of
-fno-omit-frame-pointer)
The latter makes it much easier to profile software in production using the perf Linux profiler. The other options, like LBR or DWARF, each have limitations and work only for short stack traces or very low sample rates.
Because these are "rust flags", I need to export RUSTFLAGS in CI, and that overrides the rustflags section of .cargo/config.toml, so I need to repeat the -fuse-ld=lld bit.
bashrustflags=( "-C link-arg=-fuse-ld=lld" "-C link-arg=-Wl,--compress-debug-sections=zlib" "-C force-frame-pointers=yes" ) export RUSTFLAGS="${rustflags[*]}"
rustflags=("a" "b" "c") is a bash array, and ${rustflags[*]} expands to "all items of the array", space-separated. Look, mom, no line continuations!
Of course, that's not the whole CI story...
CI solutions
My first CI system was Jenkins, and I distinctly remember writing a YAML-to-XML compiler just to make configuration manageable (before Jenkinsfiles were a thing).
Jenkins did everything I wanted back then, but at what cost?
Then there was Travis CI, which I don't feel like I need to comment on too much, since it's been acquired and effectively killed by its new parent company. Here's one example — there's many others.
Also of note, AppVeyor, whose main selling point at the time was its Windows support. But it always felt clunky, and other major CI solutions in 2021 support Windows as well now.
When I maintained the itch.io desktop app, to avoid having to use Jenkins, and before GitHub actions was a thing, I set up a GitLab instance just for GitLab CI. I had a small service, git-mirror receive GitHub webhooks and push any changes to the GitLab mirrors for all our repositories.
(Note: At the time, only GitLab EE supported mirroring out of the box. Now, it looks like all tiers do).
It worked... well enough? We built for Linux, macOS and Windows, and we used custom runners for that (respectively Hetzner boxes, MacInCloud/MacStadium VMs, and a Google Compute Engine VM).

I ended up having to do a fair bit of sysadmin work, but it was a high-performance, low-cost solution.
Then GitHub Actions appeared on the scene, and it seemed attractive at first! The killer feature was, of course, how well it's integrated with GitHub, and that it's free for open-source projects.
But as far as CI systems go, it's... pretty bad. It has a weird little sublanguage for conditionals embedded in YAML. It's really hard to re-use CI config across repositories, because they picked the wrong abstractions all around.
Their Ubuntu VMs use custom Microsoft-provided APT repositories that used to break our builds every two weeks (I say used to, because we switched away from them, not because they fixed it).
It's really hard to validate GitHub Actions config locally: there's a json schema (which works for YAML), but it's far from enough. Running jobs locally is a headache, the third-party act solution works very differently from the real thing and is super fragile.
Throughout the first half of 2021 at least, it wasn't uncommon for GitHub Actions to be, just... down? For hours at a time. Jobs just staying queued, no recourse.
When builds fail, they just fail. You get no opportunity to look at the executor after they failed, to try and do some manual debugging. Which is a shame, since you can't reliably run those locally either.
My spicy take here, is pretty much that the whole open-source world standardized on a subpar CI system just because it was free for open-source. This is why can't have nice things.
But the nail in the coffin — for me — and as far as Rust stuff is concerned, is that GitHub-hosted runners are really small. At the time of this writing, the hardware specs for Linux & Windows runners are:
- 2-core CPU
- 7 GB of RAM memory
- 14 GB of SSD disk space
Two cores to build Rust or C++ is... not a lot. Even with proper build caching, the builds are slow. Really slow. And if CI is part of your deploy pipeline, or if passing CI pipelines is a requirement for merging PRs (which it should be), then if you're on GitHub Actions you're straight up wasting engineering time.
GitHub has bigger runners internally. They've had a roadmap issue opened since Feb 10 of 2021, and at the time of this writing it's slated for Q1 2022, but they've pushed it back a few times already, so I'm not holding my breath.
CircleCI
And then... there's CircleCI.
I've become quite a fan of their service. When I decided to set up a proper work environment for my content pipeline projects, it's the very first thing I signed up for — after a quick look at their pricing.
(This is not a sponsored article, but they're one of the rare companies I wouldn't mind being sponsored by, because I think their product is really, really good.)
I'm on their "Performance" plan. For $30/month, I get 50K credits. One user is 25K credits (that's me!), and the remaining 25K credits are my "budget" for build minutes and whatnot.
I've currently used 1.4% of my 25K credits, in a week-end of playing around setting up a lot of things. Let's just say I don't expect to need to bump my plan anytime soon.

I'm bear from the future! Amos just finished writing this article, ten days later, and he's only got 7400 credits left. That's what you get when you generate a gazillion PRs to update dependencies. More on that later.
CircleCI has different types of executors. There's "machine" executors (essentially VMs), but there's also the "docker" executor, where you can bring your own Docker image, or use one of their pre-built images.
This means no longer spending any time installing APT packages (or otherwise) in CI. Every execution uses the image you want, that already has all the required toolchains and tooling installed.
Also, you can start up multiple containers. So if you rely on having a MongoDB instance around, or a mock S3/GCS storage, or redis, you can spin those up no problems!
Since I've been doing this a while, I immediately set up a docker-images GitHub repository with just the one Dockerfile (for now), using an ubuntu:20.04 base and adding rustup, a C/C++ toolchain, various build tools, the lld linker, just, and other tools.
That repo is built on CircleCI: using Circle's Remote Docker feature, the image is built and then pushed to a private AWS Elastic Container Registry.
Here's the full .circleci/config.yml for the docker-images repo:
yamlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@7.2.0 workflows: version: 2 build: jobs: - rust: context: [aws] jobs: rust: executor: aws-ecr/default steps: - aws-ecr/build-and-push-image: path: rust repo: bearcove-rust create-repo: true
The aws context contains environment variables, some of them secrets:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_ECR_ACCOUNT_URLAWS_REGION
I put my container registry in us-east-1, since that's also where CircleCI executors are, and that means... no egress fees, and everything is super fast: even when the docker image is not in cache it only takes 10s to download it and create the container:

That screenshot doesn't contain secrets. The ECR account url is not sensitive, you still need valid IAM credentials to access it.
CircleCI is integrated with "GitHub checks", so I see checkmarks as if I was using GitHub Actions:


Clicking on links on this page brings me to the CircleCI UI, which shows a job graph, complete with dependencies (not really visible on that screenshot, since there's only one job:

All commits to the main branch are pushed to my ECR registry and are automatically tagged with latest, replacing the previous latest. I have a lifecycle policy that keeps at most one untagged image, so my storage costs don't balloon up:

Using that image in a CircleCI job is as easy as specifying the image in .circleci/config.yml:
yamlversion: 2.1 workflows: version: 2 rust: jobs: - check: context: [aws] jobs: check: docker: - image: 391789101930.dkr.ecr.us-east-1.amazonaws.com/bearcove-rust:latest steps: - checkout - run: | cargo clippy
The circleci CLI (command-line interface) tool allows validating the config before pushing:
Shell session$ circleci config validate Config file at .circleci/config.yml is valid.
And I'm able to run any job locally, exactly as it would run on CI, if I pass the required credentials:
Shell session$ circleci local execute --job check --env AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID --env AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY Docker image digest: sha256:5b0601398e851795b9f59087bf1f600cfb068486e89b25afc8e1fb497ed66e2e ====>> Spin up environment Build-agent version () System information: Server Version: 20.10.8 Storage Driver: overlay2 Backing Filesystem: extfs Cgroup Driver: cgroupfs Cgroup Version: 1 Kernel Version: 5.10.16.3-microsoft-standard-WSL2 Operating System: Docker Desktop OSType: linux Architecture: x86_64 Starting container 391789101930.dkr.ecr.us-east-1.amazonaws.com/bearcove-rust:latest (etc.)
If a job fails in CI, I'm able to restart it with SSH enabled.

The job will look the same, with an added "Enable SSH" section:

...giving me the address to which I can connect with my existing GitHub SSH credentials, and from which I can examine the job right after it failed:
Shell session$ ssh -p 64537 54.160.152.120 circleci@903cdf13679d:~$ uname -a Linux 903cdf13679d 4.15.0-1110-aws #117-Ubuntu SMP Mon Aug 2 21:43:04 UTC 2021 x86_64 GNU/Linux circleci@903cdf13679d:~$ cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 9 (stretch)" NAME="Debian GNU/Linux" VERSION_ID="9" VERSION="9 (stretch)" ID=debian HOME_URL="https://www.debian.org/" SUPPORT_URL="https://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/" circleci@903cdf13679d:~$ ls / .circleci-runner-config.json etc/ media/ run/ usr/ .dockerenv go/ mnt/ sbin/ var/ bin/ home/ opt/ srv/ boot/ lib/ proc/ sys/ dev/ lib64/ root/ tmp/ circleci@903cdf13679d:~$ pwd /home/circleci circleci@903cdf13679d:~$ ls -lhA . total 20K -rw------- 1 circleci circleci 69 Oct 17 21:55 .bash_history -rw-r--r-- 1 circleci circleci 220 May 15 2017 .bash_logout -rw-r--r-- 1 circleci circleci 3.5K May 15 2017 .bashrc -rw-r--r-- 1 circleci circleci 76 Oct 17 21:54 .gitconfig -rw-r--r-- 1 circleci circleci 675 May 15 2017 .profile drwx------ 2 circleci circleci 57 Oct 17 21:54 .ssh drwxr-xr-x 6 circleci circleci 148 Oct 17 21:54 project circleci@903cdf13679d:~$ ls -lhA project/ total 20K drwxr-xr-x 2 circleci circleci 41 Oct 17 21:54 .circleci drwxr-xr-x 8 circleci circleci 163 Oct 17 21:54 .git drwxr-xr-x 4 circleci circleci 57 Oct 17 21:54 .github -rw-r--r-- 1 circleci circleci 90 Oct 17 21:54 .gitignore -rw-r--r-- 1 circleci circleci 109 Oct 17 21:54 .yamllint -rw-r--r-- 1 circleci circleci 468 Oct 17 21:54 CHANGELOG.md -rw-r--r-- 1 circleci circleci 1.1K Oct 17 21:54 LICENSE -rw-r--r-- 1 circleci circleci 2.3K Oct 17 21:54 README.md drwxr-xr-x 8 circleci circleci 128 Oct 17 21:54 src circleci@903cdf13679d:~$
I love this feature. It has saved me so much time.
But why stop there? AWS ECR (elastic container registry) is neat and, at my scale, costs literal cents, but I don't feel good about copy-pasting 391789101930.dkr.ecr.us-east-1.amazonaws.com/bearcove-rust:latest to the CI config on every one of my repositories.
I mentioned earlier that GitHub Actions picked the wrong abstractions for its "re-usable config" model, and that's painfully obvious if you've spent any amount of time with CircleCI. I have no doubt there's a solution out there that does it even better, but I'm sure you'll tell me all about it as soon as this article comes out.
CircleCI has this concept of "orbs", which are just collections of "executors", "jobs", "commands", etc.
So I went ahead an made an orb! The CLI makes it super easy to get started, with a great template. My orb has an executor:
yaml# in `bearcove-orb/src/executors/rust.yml` description: > Default Rust Executor docker: - image: 391789101930.dkr.ecr.us-east-1.amazonaws.com/bearcove-rust:latest
And a with-rust command:
yaml# in `bearcove-orb/src/commands/with-rust.yml` description: > Sets up caching, cargo authentication etc. parameters: steps: type: steps description: Rust compilation steps to run sccache-bucket: type: string description: Name of S3 bucket to use for sccache default: bearcove-sccache sccache-region: type: string description: S3 region the bucket is in default: us-east-1 steps: - run: name: Start sccache and configure rust environment: SCCACHE_BUCKET: << parameters.sccache-bucket >> SCCACHE_REGION: << parameters.sccache-region >> command: <<include(scripts/with-rust-pre.sh)>> - steps: << parameters.steps >> - run: name: Stop sccache command: <<include(scripts/with-rust-post.sh)>>
Because, as I mentioned before, I want different compile flags in CI... but I also want sccache, which is a much better solution that any built-in CI caching.
The basic idea behind sccache, at least in the way I have it set up, it's that it's invoked instead of rustc, and takes all the inputs (including compilation flags, certain environment variables, source files, etc.) and generates a hash. Then it just uses that hash as a cache key, using in this case an S3 bucket in us-east-1 as storage.
Because I'm already using AWS for storing Docker images, I don't have any additional credentials to set up — but really here I'm just selling the nice side-effects praises of a quasi-monopoly, so, I'll tone it down.
The with-rust command relies on two shell scripts, which I've all but spoiled above. Here's the pre:
bash#!/bin/bash set -eux sccache --version command -v lld export SCCACHE_IDLE_TIMEOUT="0" export RUST_LOG="sccache=info" export SCCACHE_ERROR_LOG=/tmp/sccache.log export SCCACHE_LOG="info,sccache::cache=debug" sccache --start-server rustflags=( "-C link-arg=-fuse-ld=lld" "-C link-arg=-Wl,--compress-debug-sections=zlib" "-C force-frame-pointers=yes" ) cat << EOF >> "${BASH_ENV}" export RUSTC_WRAPPER="sccache" export CARGO_INCREMENTAL="0" export CARGO_PROFILE_RELEASE_LTO="thin" export RUSTFLAGS="${rustflags[*]}" EOF
And here's the post:
bash#!/bin/bash set -eux sccache --stop-server grep -F "'403" /tmp/sccache.log | head || true
The default CircleCI template for orbs is extremely well thought-out and of course comes with a pre-made CircleCI workflow that handles testing and publishing!

Instead of shoving bash directly in your YAML, Circle encourages you to put it in .sh files instead, so that they can be checked with shellcheck, and unit-tested with Bats.
I couldn't be bothered writing unit tests for these scripts, but I did the next best thing... setting up an integration test!
yamljobs: # Define one or more jobs which will utilize your orb's commands and parameters to validate your changes. integration-test-1: executor: bearcove/rust steps: - checkout - run: command: | { echo '[toolchain]' echo 'channel = "1.55.0"' echo 'components = [ "rustfmt", "clippy" ]' } >> rust-toolchain.toml - bearcove/with-rust: steps: - run: command: | cargo --version cargo new hello cd hello cargo run
The integration test is triggered by the main pipeline and runs perfectly well:

When working in a branch, the orb is published as a dev version, something like bearcove/bearcove@dev:fc27ed6, so you can also test it immediately with other repositories. When it's ready for publication, it's simply "promoted" to a stable version, not re-published.
The whole setup is so far ahead from GitHub Actions it's really hard to describe until you've actually tried it. I am very happy to shell out 30 bucks a month to use it.
My orb is public, so you can check it out if you want, but I'd recommend you roll your own. CircleCI supports does proper private orbs, there's just no big secret in mine so I didn't bother.
Using the orb, I'm keeping duplication to a minimum. Here's the current .circleci/config.yml for salvage, for example - it's stupidly simple:
yamlversion: 2.1 workflows: version: 2 rust: jobs: - build: context: [aws] jobs: build: executor: bearcove/rust steps: - checkout - bearcove/with-rust: steps: - run: | just check just test orbs: bearcove: bearcove/bearcove@1.1.0
And in case you're wondering, sccache works extremely well. Here are the stats for salvage:
Shell session+ sccache --stop-server Stopping sccache server... Compile requests 182 Compile requests executed 152 Cache hits 152 Cache hits (Rust) 152 Cache misses 0 Cache timeouts 0 Cache read errors 0 Forced recaches 0 Cache write errors 0 Compilation failures 0 Cache errors 0 Non-cacheable compilations 0 Non-cacheable calls 30 Non-compilation calls 0 Unsupported compiler calls 0 Average cache write 0.000 s Average cache read miss 0.000 s Average cache read hit 0.053 s Failed distributed compilations 0 Non-cacheable reasons: crate-type 25 - 4 multiple input files 1 Cache location S3, bucket: Bucket(name=bearcove-sccache, region=UsEast1)
The non-cacheable crate-type executions cover bin crates (like salvage itself - easily fixable by splitting it into a library + a small bin crate), and crates that have a build script (build.rs). sccache cannot cache these, so it's a good motivation to get rid of crates that wrap C/C++ code.
The S3 cache bucket is shared across all jobs, on all branches, from all versions. There's no save/restore phase, no single cache key, no funny regex business — I just added a lifecycle policy on the S3 bucket so that objects expire after 30 days.
It's a pretty dumb policy: it'd be better to delete objects that haven't been accessed in 30 days, but last I checked that involved like 5 different AWS products and I have things to do. I'm okay with taking a slight compile time hit every month if it means I don't have to learn how Amazon Athena works.
Private crate registries
Because I want most of my stuff to remain proprietary for the time being, I can't publish them to crates.io - there's no concept of private crates on there.
Which leaves me with three solutions:
- Have a single, gigantic monorepo, never publish anything, and use path dependencies
- Have multiple repositories, never publish anything, and use Git dependencies
- Set up a private crate registry
The first two solutions are viable, but they come with their share of issues.
Option 1 (path dependencies only) means all your code lives in the same cargo workspace. This can quickly become an issue when editing code locally, since rust-analyzer will index all your code, clippy will lint all your code on save, etc. At some point you start being limited by how much RAM you have.
If you have a bunch of cargo features, compile/clippy/test times can be made better with something like cargo-hakari, which I haven't personally tried yet, but I've personally felt the problem it's trying to solve first-hand multiple times, and I truly believe Rain cracked it.
Option 2 makes it hard to have a proper release flow. Using Git dependencies means you don't really have version numbers, you don't really maintain a changelog, you can't enforce "tests must pass" before a crate is used as a dependency for another crate, and you can't "check for dependency upgrades" because your private crates don't follow semver.
Which leaves us with Option 3 - set up a private crate registry. I've used Cloudsmith in the past with success. If you have the budget for it, I'd recommend it! JFrog also does cargo registries now, and I'd expect it to work equally well.
But I've blown all my personal tooling budget on CircleCI, and I don't have that many crates, I don't need edge caching, granular access control, retention policies, etc. - the simplest crate registry out there will do!
There's a couple options to pick from, but I set my sights on ktra, which seems relatively self-contained and is written in Rust.
ktra has a book, and it's relatively easy to set up. I made a private repository at https://github.com/bearcove/crates, with this config.json file:
json{ "dl": "http://localhost:8000/dl", "api": "http://localhost:8000" }
Wait, localhost? But isn't that going to only work from the server on which ktra runs?
Yes yes, that's the fun part! We'll get to it.
Then I cloned ktra from my server, and built it:
Shell session$ git clone https://github.com/moriturus/ktra $ cd ktra $ cargo build --release
I added a config file:
TOML markup# in ktra.toml [index_config] remote_url = "https://github.com/bearcove/crates.git" https_username = "fasterthanlime" https_password = "A_GITHUB_PERSONAL_ACCESS_TOKEN" branch = "main"
And I fired it up!
Shell session$ RUST_LOG=debug ./target/release/ktra Oct 21 11:17:55.397 INFO run_server: ktra: crates directory: "crates" Oct 21 11:17:55.398 INFO run_server:new: ktra::db_manager::sled_db_manager: create and/or open database: "db" Oct 21 11:17:55.423 INFO run_server:new:clone_or_open_repository: ktra::index_manager: open index repository: "index" Oct 21 11:17:55.429 INFO run_server:pull:fetch: ktra::index_manager: fetches latest commit from origin/main Oct 21 11:17:55.749 INFO run_server:pull:merge: ktra::index_manager: start merging Oct 21 11:17:55.749 INFO run_server:pull:merge: ktra::index_manager: nothing to do Oct 21 11:17:55.755 INFO run_server:Server::run{addr=0.0.0.0:8000}: warp::server: listening on http://0.0.0.0:8000
Even though ktra binds on 0.0.0.0 by default (all interfaces), and my server has a public IP address, my hosting provider's firewall filters everything but a couple ports, so ktra is not accessible from the internet yet:
Shell session$ nmap -p 8000 REDACTED_IP Starting Nmap 7.80 ( https://nmap.org ) at 2021-10-21 11:22 CEST Nmap scan report for REDACTED_RDNS (REDACTED_IP) Host is up (0.023s latency). PORT STATE SERVICE 8000/tcp filtered http-alt Nmap done: 1 IP address (1 host up) scanned in 0.28 seconds
To be able to publish crates to ktra, I had to create a new user:
Shell session$ curl -X POST -H 'Content-Type: application/json' -d '{"password":"REDACTED"}' http://localhost:8000/ktra/api/v1/new_user/fasterthanlime {"token":"REDACTED_TOKEN"}
Then, after adding the URL of the registry to salvage/.cargo/config.toml:
TOML markup# omitted: "use LLVM's linker" config [registries] bearcove = { index = "https://github.com/bearcove/crates.git" }
I was able to run cargo login:
Shell session$ cd salvage $ cargo login --registry=bearcove REDACTED_TOKEN Login token for `bearcove` saved
And cargo publish:
Shell session$ cd salvage $ cargo publish --registry=bearcove (lots and lots of output)
Well.. no, actually, I wasn't able to run cargo publish, because I was trying to run it from my local computer. And although it did have permission to clone bearcove/crates, it then read the config.json file in there and tried to issue API requests to localhost:8000, which didn't work, because ktra is running on my server, not on my local computer.
And that's the crux of the issue! It's easy to work around with a simple SSH tunnel:
Shell session$ ssh -L 8000:localhost:8000 ftl (leave that running...)
With that, and until ssh terminates, any connections to localhost:8000 act as if they're made to localhost:8000 on my server.
And that worked great! I could see that ktra processed the new crate version, and pushed a commit:

...containing mostly metadata:

The index also exists on my server:
Shell session$ tree -I '.git' ./index ./index ├── config.json └── sa └── lv └── salvage 2 directories, 2 files
Alongside the actual .crate file:
Shell session$ tree -I '.git' ./crates ./crates └── salvage └── 0.1.0 └── download 2 directories, 1 file $ file ./crates/salvage/0.1.0/download ./crates/salvage/0.1.0/download: gzip compressed data, was "salvage-0.1.0.crate", max compression, original size modulo 2^32 66048
To try it out, I created a sample project:
Shell session$ cargo new privtest Created binary (application) `privtest` package
And added salvage, which I had just published, as a dependency:
TOML markup# in Cargo.toml [dependencies] salvage = { version = "0.1.0", registry = "bearcove" }
Running cargo tree at that point complains:
Shell session$ error: failed to parse manifest at `/home/amos/bearcove/privtest/Cargo.toml` Caused by: no index found for registry: `bearcove`
Because we need to add a .cargo/config.toml, as before:
TOML markup[registries] bearcove = { index = "https://github.com/bearcove/crates.git" }
That config file could be in ~/.cargo/config.toml, but then anyone who contributes to any of your private projects needs to know about that step.
If it's in the repositories themselves, all they have to care about is authentication.
And now cargo tree works!
Shell session$ cargo tree Updating `https://github.com/bearcove/crates.git` index Updating crates.io index Downloaded object v0.27.0 Downloaded backtrace v0.3.62 Downloaded 2 crates (302.3 KB) in 0.39s privtest v0.1.0 (/home/amos/bearcove/privtest) └── salvage v0.1.0 (registry `https://github.com/bearcove/crates.git`) ├── argh v0.1.6 (etc.)
And so do cargo check, cargo clippy, cargo build, cargo test, etc.
But if we didn't have our SSH tunnel for port 8000, then it would fail, like so:
Shell session$ cargo tree warning: spurious network error (2 tries remaining): [7] Couldn't connect to server (Failed to connect to localhost port 8000: Connection refused) warning: spurious network error (1 tries remaining): [7] Couldn't connect to server (Failed to connect to localhost port 8000: Connection refused) error: failed to download from `http://localhost:8000/dl/salvage/0.1.0/download` Caused by: [7] Couldn't connect to server (Failed to connect to localhost port 8000: Connection refused)
But the thing is... I don't want to expose an HTTP server on port 8000 to the public internet. Sure, the standard endpoints like /api/v1/crates/new require authentication, but the download endpoints like /dl/{crate}/{version}/download are not authenticated! And neither is /ktra/api/v1/new_user/{user_name}.
There's a couple RFCs of interest around that topic, like:
But these haven't landed yet, so in the meantime... the crates Git repository is already private, so only folks with read access to that repository can clone it. The "api" part is already protected by authentication (hence the required cargo login), we really just need to protect the "dl" part.
All we need is... an HTTPS reverse proxy.
It would be really fun to write it ourselves, using hyper and something like async-acme. That is left as an exercise to the reader.
Instead, I chose the easy way out, which in this case was Caddy. It acts as a reverse proxy, and automatically provisions TLS certificates via Let's Encrypt.
You... chose a Go server application?
Yup! That should prove once and for all that I'm pragmatic, not dogmatic.
I did choose to have a bit of fun elsewhere though — because my main server is fairly large, and I might want to wipe it and reinstall it from scratch at some point, I wanted to host my crate registry on its own instance, but I didn't want it to cost too much.
AWS has a bunch of ARM instances available now, and I thought it might be neat to try and get my tiny crate registry to run on their tiniest instance available, the t4g.nano, using Amazon's own Linux distribution, Amazon Linux 2.
Provisioning the instance was easy enough, and I wanted to try and compile ktra there just to see how long it would take with a single core and 512MiB of RAM, but I was stopped in my tracks when rustup was killed by the OOM killer.
Luckily, Docker is all set up to run ARM64 containers via qemu, so I was able to build an arm64 ktra binary from the comfort of my own laptop, following roughly those steps:
Shell session$ docker run --rm -it arm64v8/amazonlinux:2.0.20211001.0 /bin/bash # yum install htop tmux git gcc openssl-devel # git clone https://github.com/moriturus/ktra # cd ktra # cargo build --release
This took a long time - like, half an hour. I kinda wish I'd tried to build it directly on CircleCI instead, on an actual ARM64 machine. Or just provisioned a larger AWS instance just for the purposes of building this.
But it eventually finished, and one docker cp + scp later, I had an ARM64 binary for ktra on my instance. As for migrating the data, well - it's just plain old files:
Shell session# from big server $ tar czvf snapshot.tar.gz crates crates_io_caches db index ktra.toml # scp ensues... then, from the small instance $ tar pfx snapshot.tar.gz $ RUST_LOG=info ~/.local/bin/ktra Oct 21 14:48:14.105 INFO run_server: ktra: crates directory: "crates" Oct 21 14:48:14.105 INFO run_server:new: ktra::db_manager::sled_db_manager: create and/or open database: "db" Oct 21 14:48:14.115 INFO run_server:new:clone_or_open_repository: ktra::index_manager: open index repository: "index" Oct 21 14:48:14.122 INFO run_server:pull:fetch: ktra::index_manager: fetches latest commit from origin/main Oct 21 14:48:14.286 INFO run_server:pull:merge: ktra::index_manager: start merging Oct 21 14:48:14.286 INFO run_server:pull:merge: ktra::index_manager: nothing to do Oct 21 14:48:14.291 INFO run_server:Server::run{addr=0.0.0.0:8000}: warp::server: listening on http://0.0.0.0:8000
This was a big selling point of ktra for me — I can think of many fun things to fill my free time but doing PostgreSQL admin work is not one of them. Being able to just tarball a bunch of directories is great for backup/restore and migrations. It's still old-school, this should all be either Nix or Docker containers, but one can of worms at a time.
Which leaves us with the reverse proxying part - luckily Caddy distributes Linux ARM64 binaries, so there was no compilation involved here. I use Cloudflare to manage my DNS, so I checked the caddy-dns/cloudflare plugin and off I was.
Because I didn't feel like running caddy as root, I simply gave it permission to bind on low ports (443, in this case).
Shell session$ sudo setcap 'cap_net_bind_service=+ep' $(which caddy)
After some trial and error, I came up with the following Caddyfile:
Caddyfilecrates.bearcove.net tls REDACTED_LETSENCRYPT_EMAIL { dns cloudflare {env.CLOUDFLARE_API_TOKEN} } @restricted { path /dl/* path /ktra/* } basicauth @restricted { token REDACTED_SECRET_TOKEN_HASH } reverse_proxy 127.0.0.1:8000 log
$CLOUDFLARE_API_TOKEN is passed via the environment, and even though it's fairly permissive, it's also using an IP allowlist, so even if I somehow leak it, you'll need to make requests from my tiny ARM64 AWS instance to wreck my DNS.

REDACTED_SECRET_TOKEN_HASH was obtained by shoving a (very long) 1Password-generated password into caddy hash-password. I'm fairly sure I should be able to share the hashed version and climate change would be the end of us all before anyone is able to reverse it, but, I don't feel like giving you that particular challenge right now.
How does that work? Well! https://ift.tt/3bd2giD should be live for everyone, and simply reply with some JSON payload that says ktra doesn't know about that specific endpoint.
The /dl and /ktra prefixes are protected with HTTPS basic auth by Caddy, and the rest, ie. /api/v1, the "standard" API surface for a private crate registry, which is only used when publishing / yanking / unyanking a crate, is protected by ktra itself, using the fasterthanlime/password combo set above.
Next, we need to convince cargo to send HTTP basic auth when downloading crates. That's easy enough:
json{ "dl": "https://token:REDACTED_SECRET_TOKEN@crates.bearcove.net/dl", "api": "https://crates.bearcove.net" }
Pushed that change to config.json to the crates repo, restarted ktra, and just like that, everything started working — no SSH tunnel involved.
It feels iffy to have a secret in Git, but it's easy enough to rotate should something go terribly wrong, and also the prize isn't terribly attractive here: it's just a bunch of code I want to maintain only for myself.
Now that we have a proper crate registry, though, we can do interesting things...
We've got the solution, let's come up with a problem
futile, my web server, was already a cargo workspace when I started setting up all of this. It had a futile bin crate, and a preprocess crate, which I use to, well, preprocess markdown content: it supports inline math, block math, and shortcodes.
Shortcodes are how I get cool bear to talk, for example:
Hey, nobody makes me talk.
Or how I embed a YouTube video:

So, long story short, I've got a whole-ass nom-based parser just for these. They generate HTML (or more Markdown), and then the Markdown parser kicks in.
Currently that crate is named preprocess and lives in the futile repository, but let's look at how it would look in its own repository. First we gotta find a better name for it... it's mostly about "short" codes, so how about "pithy"?
Shell session$ cp -rfv futile/crates/preprocess pithy/ 'futile/crates/preprocess' -> 'pithy/' 'futile/crates/preprocess/Cargo.toml' -> 'pithy/Cargo.toml' 'futile/crates/preprocess/src' -> 'pithy/src' 'futile/crates/preprocess/src/lib.rs' -> 'pithy/src/lib.rs' 'futile/crates/preprocess/src/tests.rs' -> 'pithy/src/tests.rs'
The crate used to be called preprocess, so I had to change its name in Cargo.toml, and also, a very important step, add a publish field so it'll only publish to my private registry, bearcove — that way I won't accidentally publish it to crates.io:
TOML markup[package] name = "pithy" version = "0.1.0" authors = ["Amos <wouldntyou@liketoknow.org>"] edition = "2018" publish = ["bearcove"]
Next steps are setting up a rust-toolchain.toml, the .cargo/config.toml with lld and the "bearcove" crate registry, and a .circleci/config.yml file.
Oh, and a nice README, of course!

Convincing CircleCI to start builds for pithy is a manual step, done from the web UI, in the "Projects" tab (from the sidebar). CircleCI immediately finds .circleci/config.yml in the repo and starts building.
And the pipeline passes!

So far it's running clippy and some unit tests. That's good! But we can do better.
Finding unused dependencies
We can, for example, run cargo-udeps, to find unused dependencies. Technically, it requires Rust nightly, but Rust nightly also has a bug where sometimes it fails to download some crates? So uh, let's be super pragmatic here:
# in Justfile # Finds unused dependencies udeps: RUSTC_BOOTSTRAP=1 cargo udeps --all-targets --backend depinfo
Shell session$ just udeps RUSTC_BOOTSTRAP=1 cargo udeps --all-targets --backend depinfo Checking pithy v0.1.0 (/home/amos/bearcove/pithy) Finished dev [unoptimized + debuginfo] target(s) in 0.52s info: Loading depinfo from "/home/amos/bearcove/pithy/target/debug/deps/pithy-e41c3a23a19cb149.d" info: Loading depinfo from "/home/amos/bearcove/pithy/target/debug/deps/pithy-9b717f0b4e93afb5.d" All deps seem to have been used.
Ha! Looks like all deps have been used. Let's add one we don't need, just to make sure.
Shell session$ cargo add seahash Updating 'https://github.com/rust-lang/crates.io-index' index Adding seahash v4.1.0 to dependencies $ just udeps RUSTC_BOOTSTRAP=1 cargo udeps --all-targets --backend depinfo Updating crates.io index Checking pithy v0.1.0 (/home/amos/bearcove/pithy) Finished dev [unoptimized + debuginfo] target(s) in 1.99s info: Loading depinfo from "/home/amos/bearcove/pithy/target/debug/deps/pithy-329af741d325ac70.d" info: Loading depinfo from "/home/amos/bearcove/pithy/target/debug/deps/pithy-530fe92706d1a506.d" unused dependencies: `pithy v0.1.0 (/home/amos/bearcove/pithy)` └─── dependencies └─── "seahash" Note: They might be false-positive. For example, `cargo-udeps` cannot detect usage of crates that are only used in doc-tests. To ignore some dependencies, write `package.metadata.cargo-udeps.ignore` in Cargo.toml. error: Recipe `udeps` failed on line 16 with exit code 1
Fantastic! So if we add it to our CI Dockerfile...
Dockerfile# Install cargo-udeps ENV CARGO_UDEPS_VERSION=v0.1.24 RUN set -eux; \ curl --fail --location "https://github.com/est31/cargo-udeps/releases/download/${CARGO_UDEPS_VERSION}/cargo-udeps-${CARGO_UDEPS_VERSION}-x86_64-unknown-linux-gnu.tar.gz" --output /tmp/cargo-udeps.tar.gz; \ tar --directory "/usr/local/bin" -xzvf "/tmp/cargo-udeps.tar.gz" --strip-components 2 --wildcards "*/cargo-udeps"; \ rm /tmp/cargo-udeps.tar.gz; \ chmod +x /usr/local/bin/cargo-udeps; \ cargo-udeps --version;
And add a udeps job for in CI...
yamlversion: 2.1 workflows: version: 2 rust: jobs: - check: context: [aws] - test: context: [aws] - udeps: context: [aws] jobs: check: executor: bearcove/rust steps: - checkout - bearcove/with-rust: steps: - run: just check test: executor: bearcove/rust steps: - checkout - bearcove/with-rust: steps: - run: just test udeps: executor: bearcove/rust steps: - checkout - bearcove/with-rust: steps: - run: just udeps orbs: bearcove: bearcove/bearcove@1.1.0
...then it should fail!

And it does! Fantastic. Let's fix that real quick:
Shell session$ cargo rm seahash $ git add . && git commit -m "Remove unused dependency seahash" && git push
And move on.
Automating dependency updates
To find out about new versions of crates you're depending on, there's cargo-outdated.
But that's mostly useful locally! I don't really want to run that in CI, because, what are you gonna do: fail the build if any dependency update is available?
No! Instead I'd like for there to be a bot that simply opens PRs when a new dependency is available, so that I can see if the tests are going to pass, look at the diff, and make an informed decision.
GitHub acquired Dependabot in 2019, and now Dependabot is better integrated with the rest of the GitHub product.
But I'm also not sure how to contribute to it any more, and even though the GitHub-native dependabot docs mention "private registries support" for cargo, this issue and that issue seem to indicate that it's not going to be prioritized until 2022 at least.
Since I'm not in love with the idea of being at the mercy of GitHub's product roadmap, in January of 2021 I contributed support for private crate registries (and cargo workspaces) to a competing solution, renovate.
Renovate is available as a GitHub app, but it's also available as a simple npm package, and since I went the trouble of setting up CircleCI and I like to configure my workflow just the way I like it (in case the length of this article hasn't made it obvious enough), I took the following steps.
Step 1: create a docker-image that contains the known-good version of Renovate I'd like to use.
I ended up moving docker-images to use a single Dockerfile with multiple "targets", the Docker docs calls those multi-stage builds.
So, here's the part of my Dockerfile that installs renovate:
Dockerfile############################################## FROM base AS renovate ############################################## # Install node.js RUN set -eux; \ curl -fsSL https://deb.nodesource.com/setup_17.x | bash -; \ apt-get install -y nodejs; \ node --version # Install re2 (for renovate) RUN set -eux; \ apt update; \ apt install --yes --no-install-recommends \ # # Used by CircleCI, also Renovate libre2-5 \ ; # Install renovate ENV RENOVATE_VERSION=28.10.3 RUN set -eux; \ npm install --global renovate@${RENOVATE_VERSION}; \ renovate --version # Clean up APT artifacts RUN set -eux; \ apt clean autoclean; \ apt autoremove --yes; \ rm -rf /var/lib/{apt,dpkg,cache,log}/
Step 2: create a renovate-config repository with a base Renovate configuration for Rust:
json{ "$schema": "https://docs.renovatebot.com/renovate-schema.json", "dependencyDashboard": true, "semanticCommitType": "fix", "packageRules": [ { "packagePatterns": ["^futures[-_]?"], "groupName": "futures packages" }, { "packagePatterns": ["^serde[-_]?"], "groupName": "serde packages" }, { "packagePatterns": ["^tokio[-_]?"], "groupName": "tokio packages" }, { "packagePatterns": ["^tracing[-_]?"], "excludePackageNames": ["tracing-opentelemetry"], "groupName": "tracing packages" }, { "packagePatterns": ["^liquid[-_]?", "^kstring$"], "groupName": "liquid packages" } ], "regexManagers": [ { "fileMatch": ["^rust-toolchain\\.toml?$"], "matchStrings": [ "channel\\s*=\\s*\"(?<currentValue>\\d+\\.\\d+\\.\\d+)\"" ], "depNameTemplate": "rust", "lookupNameTemplate": "rust-lang/rust", "datasourceTemplate": "github-releases" } ] }
...and two CircleCI workflows: one that runs on every commit (and that can be triggered manually if needed), and one that runs daily:
ymlversion: 2.1 workflows: version: 2 commit: jobs: - renovate: context: [aws, renovate] nightly: jobs: - renovate: context: [aws, renovate] triggers: - schedule: # every day at 11:30 AM UTC cron: "30 11 * * *" filters: branches: only: - main jobs: renovate: docker: - image: 391789101930.dkr.ecr.us-east-1.amazonaws.com/bearcove-renovate:latest steps: - run: environment: LOG_LEVEL: debug command: | set -eux renovate \ --onboarding false \ --require-config true \ --allow-custom-crate-registries true \ --token ${RENOVATE_TOKEN} \ --git-author "Renovate Bot <renovate@bearcove.net>" \ --autodiscover \ ;
Step 3: Add a .renovaterc.json to every Rust repository I have:
json{ "$schema": "https://docs.renovatebot.com/renovate-schema.json", "extends": [ "github>bearcove/renovate-setup:rust" ] }
Step 4: Trigger a workflow run on bearcove/renovate-setup, and...

Voilà! Beautiful PRs.
That's right American friends: voilà is spelled voilà, with a grave accent on the a. It is not spelled voila, and it is MOST DEFINITELY not spelled viola, which is the instrument played by people who cannot play the violin properly.
I like this PR specifically, because it groups various liquid-related crates together (thanks to my colleague Marcus for showing me that Renovate feature!):

On the other hand, it fails. But that's good! I'll be able to make the required changes in that PR, as part of upgrading to liquid@23.0.0, and once CI passes, I'll be able to merge it.

That next PR is not for a crate, it's for the version of Rust specified in rust-toolchain.toml - I also learned that trick from Marcus. Marcus if you're reading this, you're a gem and I appreciate you.

Because I asked renovate to do so, it even maintains a "Dependency Dashboard" issue, from which I can see at a glance where I stand:

Now that I have renovate set up, it'll be less of a hassle to make sure I'm keeping up with the times on my various repositories. Which brings us to the next task we can automate... releasing new versions of a crate!
Release automation
Nothing prevents you from running cargo publish from your local machine. But if you want to do things right, you'll want to make sure that you only ever publish a version of a crate that passes tests - including integration tests, clippy lints, etc.
So now you have to remember to do that every time you publish a crate. Maybe you write a script! Maybe you just have a very long markdown document outlining how to publish your crate, or crates — because yes, if you have a workspace full of crates, that are interdependent, you have to publish them in order.
Oh, and you need to maintain a changelog as well! Sure, that's also something you can automate, but suddenly your release flow involves a half-dozen tools, with a bunch of manual steps you better not forget.
Well! I'm happy to show you a way to do all of that with only two tools.
release-please is a command-line tool that you can run in CI, on your default branch, and that scans semantic commits since the last release to maintain a "release PR".

A PR that looks like this:

And that updates the changelog and bumps all necessary crates:

But, mh, I don't think this should be a patch release, I think this should be a major release, because we upgraded to nom v7. If I had edited renovate's PR to be feat!(deps): upgrade to nom v7 instead of fix(deps): upgrade to nom v7, then release-please would've determined that the next version of pithy should be 2.0.0.
I was in a hurry so I didn't do that. But we can still tell release-please exactly what version we want to release, by making a commit with the following message:
feat!: Upgrade to nom v7 (major bump) Release-As: 2.0.0
And after a few seconds, release-please closes the release-v1.0.1 and opens a new PR, release-v2.0.0:

Before I go ahead and merge this PR, I need to tell you the other piece of the puzzle: cargo-workspaces.
Among other things, it lets you do cargo publish:
- For all crates in a workspace
- ...in order (by building a graph and walking it leaf-to-root)
- ...skipping crates that are already published.
The invocation, for me, looks like:
Shell sessioncargo workspaces publish \ --from-git \ --token "${KTRA_TOKEN}" \ --yes
Previous versions of cargo-workspaces had a --skip-published flag, but it didn't play well with private registries.
That cargo-workspaces PR fixes that, and it has been merged, but to release a new version of cargo-workspaces, a new version of rust-crates has to be released first, that includes this PR that fixes Git authentication.
Which brings the total number of PRs involved in this article to something like... seven? Or eight? I've lost track. You're welcome!
And that's something we can run in CI, on the default branch, after all the tests/checks/lints/etc. we want have passed. So, the job graph looks like that:

Of course for the last few commits, cargo workspaces publish hasn't actually been doing any work: it found, every time, that all the crates's latest versions were already published, and simply skipped them:

But once I merge this PR, the Cargo.toml manifest for pithy will indicate 2.0.0, and that hasn't been published yet! So it does publish it...

...and sure enough, it shows up in my private registry:

And in GitHub releases, complete with a changelog entry:

So what I just showed was for a repository containing a single crate: I'm invoking release-please like so (shown as a CircleCI job):
ymldescription: Update release PRs and create GitHub releases executor: renovate steps: - checkout - run: name: Install release-please command: | npm install --global release-please@11.23.0 - run: name: Run release-please command: | for command in release-pr github-release; do release-please --debug "${command}" \ --token "${GITHUB_TOKEN_BEARCOVEBOT}" \ --release-type "rust" \ --repo-url "${CIRCLE_REPOSITORY_URL}" done
But thanks to a couple PRs of mine...
More PRs?? You've been a busy boy!
...it also supports the "manifest releaser", that you would call like that:
ymldescription: Update release PRs and create GitHub releases executor: renovate steps: - checkout - run: name: Install release-please command: | npm install --global release-please@11.23.0 - run: name: Run release-please command: | for command in manifest-pr manifest-release; do release-please --debug "${command}" \ --token "${GITHUB_TOKEN_BEARCOVEBOT}" \ --repo-url "${CIRCLE_REPOSITORY_URL}" done
Notice the differences:
manifest-prinstead ofrelease-prmanifest-releaseinstead ofgithub-release- no
--release-typeneeded
Instead, a release-please-config.json file is needed:
json{ "bootstrap-sha": "COMMIT_SHA_BEFORE_RELEASE_PLEASE", "plugins": ["cargo-workspace"], "release-type": "rust", "packages": { "crates/foo": {}, "crates/bar": {}, "crates/baz": {} } }
And release-please maintains a .release-please-manifest.json file, which simply looks like:
json{ "crates/foo": "0.3.0", "crates/bar": "0.13.7", "crates/baz": "0.1.5" }
This greatly reduces the number of GitHub API requests needed for every release-please run, and more importantly, it handles arbitrarily deep transitive dependencies when upgrading packages!
For example, let's say foo depends on bar which depends on baz, and baz had a fix: Woopsie doopsie commit. There will be a single release PR that bumps all three packages:
bazis bumped because of the fix commitbaris bumped because itsbazdependency was bumpedfoois bumped becausebarwas also bumped
Any time you're ready to publish all the crates in the monorepo that have changed, you can simply merge the current release-please PR (it maintains one changelog per crate), and, if you have cargo workspaces publish set up, in this case it will publish first baz, then bar, then foo.
As far as I'm concerned, this is pretty much the ideal release workflow. There's very little manual work involved, semver is respected, you get neatly formatted changelogs, all you need to put in is to prefix your commits with fix: or feat:, and the occasional breaking-change fix!: and feat!:. It's okay if you forget it on one commit, you can always add another commit later.
For the manifest releaser, only commits that touch the subpath (e.g. crates/foo) qualify for a new release of the crate. That's how it can tell which changes belong to which crates.
In practice, when you're doing fixup commits (forgot to tag this feat:), you might end up having to add/remove a blank line to crates/foo/Cargo.toml for example. Not the most elegant solution, but still a nice escape hatch for all the value release-please provides.
Actually using our private dependency
So, now that we've privately published pithy (words are hard), how do we actually use it?
Well, for me, futile is going to use pithy. It used to be a cargo workspace so I've had to move some files around, but you can figure that part out for yourself.
Because it's going to use a crate from the bearcove registry, I have to add a .cargo/config.toml file just as before:
TOML markup# in `/futile/.cargo/config.toml` # included for completeness, but not super relevant here [target.x86_64-unknown-linux-gnu] rustflags = [ "-C", "link-arg=-fuse-ld=lld", ] # here's the relevant bit: [registries] bearcove = { index = "https://github.com/bearcove/crates.git" }
In Cargo.toml, gotta make sure to only ever publish to bearcove (even though I'm not planning on having futile as a dependency of some other crate, rather I want to build a binary for it in CI):
TOML markup# in `futile/Cargo.toml` [package] name = "futile" version = "0.1.0" authors = ["Amos <redac@ted.org>"] edition = "2018" publish = ["bearcove"]
And instead of having a path-dependency, I can now have a proper dependency!
TOML markup# in `futile/Cargo.toml` [dependencies] pithy = { version = "2.0.0", registry = "bearcove" }
Because bearcove-orb sets up git credentials, all the CI pipelines pass:

But let's make some changes just to see how the full workflow would work.
For example let's switch pithy to the Rust 2021 edition, which came out while I was writing this article, believe it or not:

Because that PR starts with feat!:, release-please steps in, suggesting we bump from 2.0.0 to 3.0.0:

And that sounds good to me, so let's merge it! Soon enough, the crate is published (and a GitHub release is created):

But what's next? Surely I don't have to go edit futile's Cargo.toml by hand, right?
Right! I just need to wait until tomorrow, 9:30AM my time. But I don't like to wait, so instead, let's trigger the workflow manually...

And... tada! A PR for upgrading pithy is available:

This only worked because --allow-custom-crate-registries true was passed to renovate. Which means this won't work with Renovate as a GitHub App, and also, you can't put that setting in a preset, like the rust.json we made above.
No worries though! If you misconfigure Renovate, or it encounters an error in some way, it'll update the "Dependency Dashboard" issue with helpful messages.
For example, a PR was having trouble updating Cargo.lock (because there were multiple versions of the time crate in the project), and Dependency Dashboard showed this:

And the PR itself showed this:
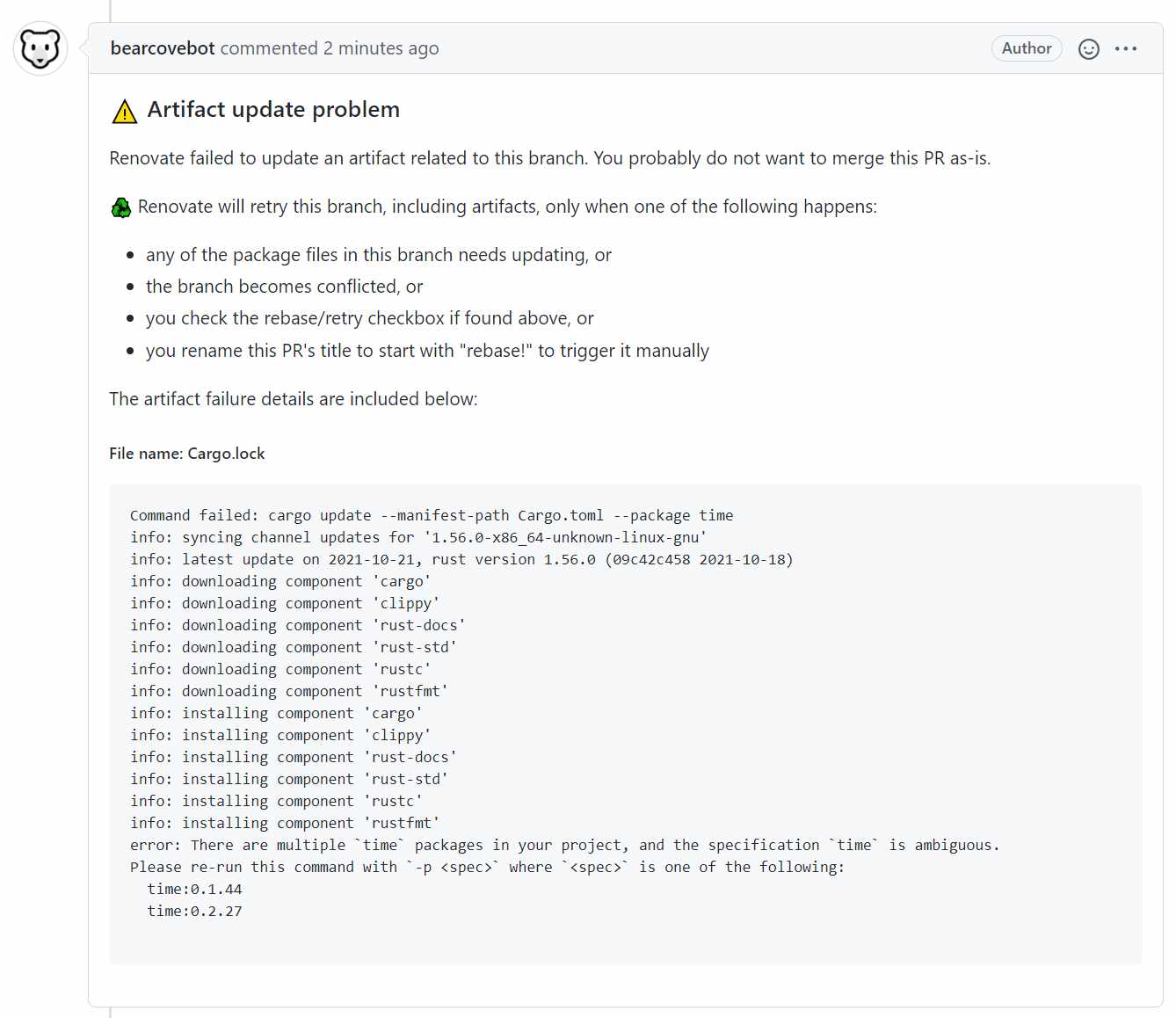
And then I opened another PR against renovate to fix it. And the an unrelated PR against release-please, all because of this article.
Wrestling tons of PR
If you've been following along and you've set up all of this for yourself/your company, well, congrats! Definitely tell me all about it!
But also, especially initially, if you haven't updated dependencies in a while, you may be faced with a wall of PRs. For me, 47 individual dependencies were out-of-date, on my largest project. It took a while to go through them.
But some things can help! For example, GitHub has a CLI tool that's really handy.
My workflow consisted mostly of gh pr list, gh pr checkout:

You can even use gh pr view if you don't feel like opening a browser:

And when I'm happy with the changes, gh pr merge (it has interactive menus, this is just the aftermath):

Another solution we've been using successfully at work is to have a merge bot.

Simply add the "automerge" label to a bunch of PRs you know are safe, and something like Kodiak will maintain a queue, rebase and wait for checks to pass before merging.
Even with a merge bot like Kodiak, there can be merge conflicts with Renovate PRs. Luckily Renovate is able to rebase/retry PRs. Unluckily, there doesn't seem to be an easy way to trigger CircleCI builds "when a PR is updated", for example, when you check the checkbox.
An alternative solution is to have a Renovate workflow on every repository. You can set the rebaseWhen setting to "conflicted", which means:
- Renovate will run on the default branch, and rebase any renovate PRs that have merge conflicts
- Kodiak will maintain its merge queue, rebasing PRs before merging if you have enforce "require PRs to be up-to-date with the base branch" in the repository setting, like so (only available for GitHub's Team Plan & above):

Now you try it!
There's a lot more to say about all this, but I'm fairly happy with the workflow I've set up both for work, and for my personal projects. Now I can focus on the code I want to ship, and I can liberate some storage space in my brain, that was previously dedicated to all these manual procedures I had to follow all the time.
I hope this can be useful to some of y'all. If it is, don't hesitate to reach out! I always enjoy hearing how my work is having an impact in the real world.
from Hacker News https://ift.tt/3jFxbZc
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.