A library to train large neural networks across the internet. Imagine training one huge transformer on thousands of computers from universities, companies, and volunteers.
That said, training large neural networks isn't cheap. The hardware used for the previous largest language model costs over $25 million. A single training run for GPT-3 will set you back at least $4.6M in cloud GPUs. As a result, researchers can't contribute to state-of-the-art deep learning models and practitioners can't build applications without being supported by a megacorporation. If we want the future of AI to be bright, it can't be private.
What is hivemind?
Hivemind is a library for decentralized training of large neural networks. In a nutshell, you want to train a neural network, but all you have is a bunch of enthusiasts with unreliable computers that communicate over the internet. Any peer may fail or leave at any time, but the training must go on. To meet this objective, hivemind models use a specialized layer type: the Decentralized Mixture of Experts (DMoE). Here's how it works:
- host one or more experts depending on their hardware;
- run asynchronous training, calling experts from other peers,
- form a Distributed Hash Table to discover each other's experts
- the same type of protocol that powers BitTorrent file sharing.
Hivemind uses Kademlia-based DHT that can scale to tens of thousands of peers with logarithmic search complexity.
On each forward pass, a peer first determines what "speciality" of experts is needed to process the current inputs using a small "gating function" module. Then it finds k (e.g. 4) most suitable experts from other peers in the network using the DHT protocol. Finally, it sends forward pass requests to the selected experts, collects their outputs and averages them for the final prediction. Compared to traditional architectures, the Mixture-of-Experts needs much less bandwidth as every input is only sent to a small fraction of all experts.
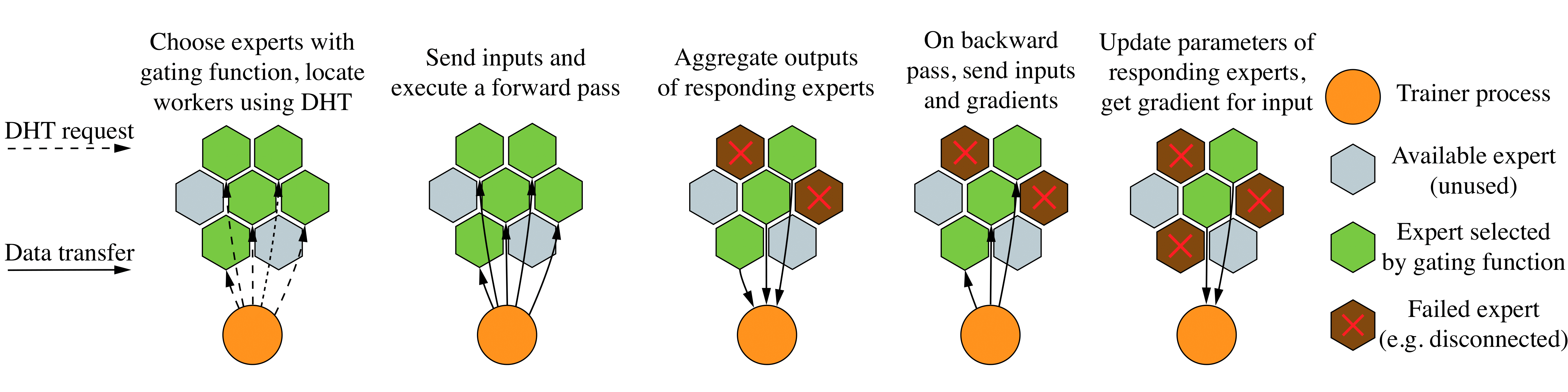
More importantly, the decentralized Mixture-of-Experts layers are inherently fault-tolerant: if some of the chosen experts fail to respond, the model will simply average the remaining ones and call that dropout. In the event that all k experts fail simultaneously, a peer will backtrack and find another k experts across the DHT. Finally, since every input is likely to be processed by different experts, hivemind peers run several asynchronous training batches to better utilize their hardware.
What is hivemind for?
Hivemind is designed for you to:- run crowdsourced deep learning using compute from volunteers or decentralized participants;
- train neural networks on multiple servers with varying compute, bandwidth and reliability;
- [to be announced] join a worldwide open deep learning experiment.
Conversely, here's what it isn't for:
- splitting your model between 2-3 servers that you fully control: use torch.distributed.rpc;
- distributed training for a reliable, uniform and highly connected cluster: use DeepSpeed;
- training small More specifically, models that fit into a single worker's memory. models with dynamically allocated of in-house workers: use torch.elastic.
Hivemind v0.8 is in the early alpha stage: the core functionality to train decentralized models is there, but the inferface is still in active development. If you want to try hivemind for yourself or contribute to its development, take a look at the quickstart tutorial. Feel free to contact us on github with any questions, feedback and issues.
from Hacker News https://ift.tt/3lP6Bwo
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.