My digital life in a nutshell: I discover relevant content I don’t have time to consume, I find time and become overwhelmed with my scattered backlog, I wish the content were in a different format, and then I’m unable to find something again once I’ve consumed it. Not retaining enough is a valid problem but we’ll tackle that one later.
There’s a lot of generalization in my summary but the core issue is an extraordinarily high level of friction in the process of finding, organizing, and sharing digital content. During the past few years I’ve noticed:
-
The more seamless the acquisition & ingestion, the more engaged I am with the content
-
Insights are just as likely to be found in a 400-page book as in a 40-minute podcast
-
Notes and their subsequent review are essential for long-term retention
-
Recommendations from other humans are as good, if not better, than algorithmic suggestions
In the rest of this post I attempt to explain the digital tools I wish existed, and how the the currently available tools do not suffice. What are also probably lacking are my habits and workflows around this - but I’m looking at tools specifically here.
Queue management for inbound digital content
Where to begin? Probably the most common problem I see myself and other people dealing with is processing the incoming deluge of articles to read and videos to watch. This isn’t all personal recommendations - it encompasses any and all content I think my future self would appreciate me consuming. A list of issues, roughly by order of appearance:
-
Content (or links to it) arrive from a variety of sources including text messages from friends, email conversations, tweetstorms and replies, references in books, suggestions in real-world conversations, and more.
-
Every book, article, post, or tweet has the potential to lead to more content.
-
Content is published in a variety of formats including but not limited to images, sound files, videos, Google Drive docs, diagrams, long-from paywalled articles, PDFs, powerpoint presentations, and base 64 encoded blobs.
-
I have little visibility into required time investment and foundational context until I’ve opened it and started thinking about it. Should I sit down with a pen and paper to read this or can I skim it while waiting for my coffee?
-
Learning, work, news, and entertainment all have different priorities in my life (roughly in that order).
-
I would like to batch process content in different “streams” regardless of where they are stored. For example: I have two hours, let me work through interesting text content my friends sent me last week. Or: show me all the interesting/relevant videos I’ve queued over the past month.
-
I’m not always connected to a stable internet connection.
-
If it’s a long piece of content I want my position saved reliably so I can resume at a later point.
-
I often want it in a different format than the one it was originally published in (audio → text, text → audio, pdf → ebook). Automated conversion works but is cumbersome. Listening to text articles requires sending them to a special app and converting articles to ebooks is annoying and loses a lot of formatting and navigation.
-
I love to respond to a person’s recommendation - preferably before they’ve forgotten why they sent me it in the first place.
-
I’d like a centralized history of content tied to my notes and annotations in case I want to find it again later. It feels like every week I’m speaking with someone and I remember a blog post I read a few months ago they might find relevant … or was it a Reddit post? Can I find it my history? Oh no, it’s been replaced with
[deleted]… find a archived copy… rinse and repeat.
Following my curiosity feels like chasing a caffeinated bunny around while real understanding requires time, perspective, and reflection. The internet makes the former much easier - so I find myself constantly balancing the two. Additionally, my energy and attention levels vary throughout the day and it’s far easier to just open Twitter rather than continue reading a long-form article I started on my laptop two days ago. Too often I default to the lower-friction one.
Honorable Mentions: Pocket, Instapaper
A universal book log, recommendation & sharing system
I love exploring other peoples’ reading lists. Here’s my own. I find everyone keeps their reading lists in different formats on different platforms. Plaintext lists are nice but hard to parse. Spreadsheets are easy to parse but a pain to manage. Third-party services aren’t interoperable, require logins, and are not future-proof.
Part of the problem here is metadata is hard. Someone has to sit there and fill out the author, title, subtitle, summary, page count - and they’re probably not going to do it for free. Amazon is a good at it but is hostile to publishers. Goodreads has much potential but seems to have stagnated. Linking to the book’s Wikipedia entry would be my preference but very few books have an entry.
Whatever this tool for managing my ever-growing reading list will be, it should:
-
Let me compare my reading list with another to see overlap. I find this a wonderful way to spark conversation and find common interests.
-
Allow me to tag books instead of placing them into static lists (think clusters or tag clouds).
-
Be tied to my highlights, annotations, and bookmarks in a non-proprietary, searchable, and shareable format. Make them public if I want to.
-
Save context on where and when I found this book: why I thought it was important to read, when I read it, what I wrote down while reading it, and what other content I discovered through it.
-
Let me query this tool like a relational database. For example: show me all books about scaling startups recommended by people I follow on Twitter or by people they follow. The current Twitter search makes me feel like I’m using a government site created before I myself even knew what a computer was.
-
Help me deal with prioritization. My reading list is a mess and I can’t be alone. Are certain books better read before others? Prerequisites? Could three of them be replaced with one? What are the other books by the this author? Are they worth reading too? Why exactly did I think reading this 800 page book was relevant when I added it? Is 80% of the content attainable from a blog post? Where is that post? Has someone in my network written a rebuttal to the ideas in this book? The list goes on and on.
-
Provide relevant suggestions with the typical recommender approach based on what people interested in the same topics also enjoyed reading and learning from.
Honorable Mentions: None :(
Intelligent PDF viewers, eBook readers, audiobook & podcast players
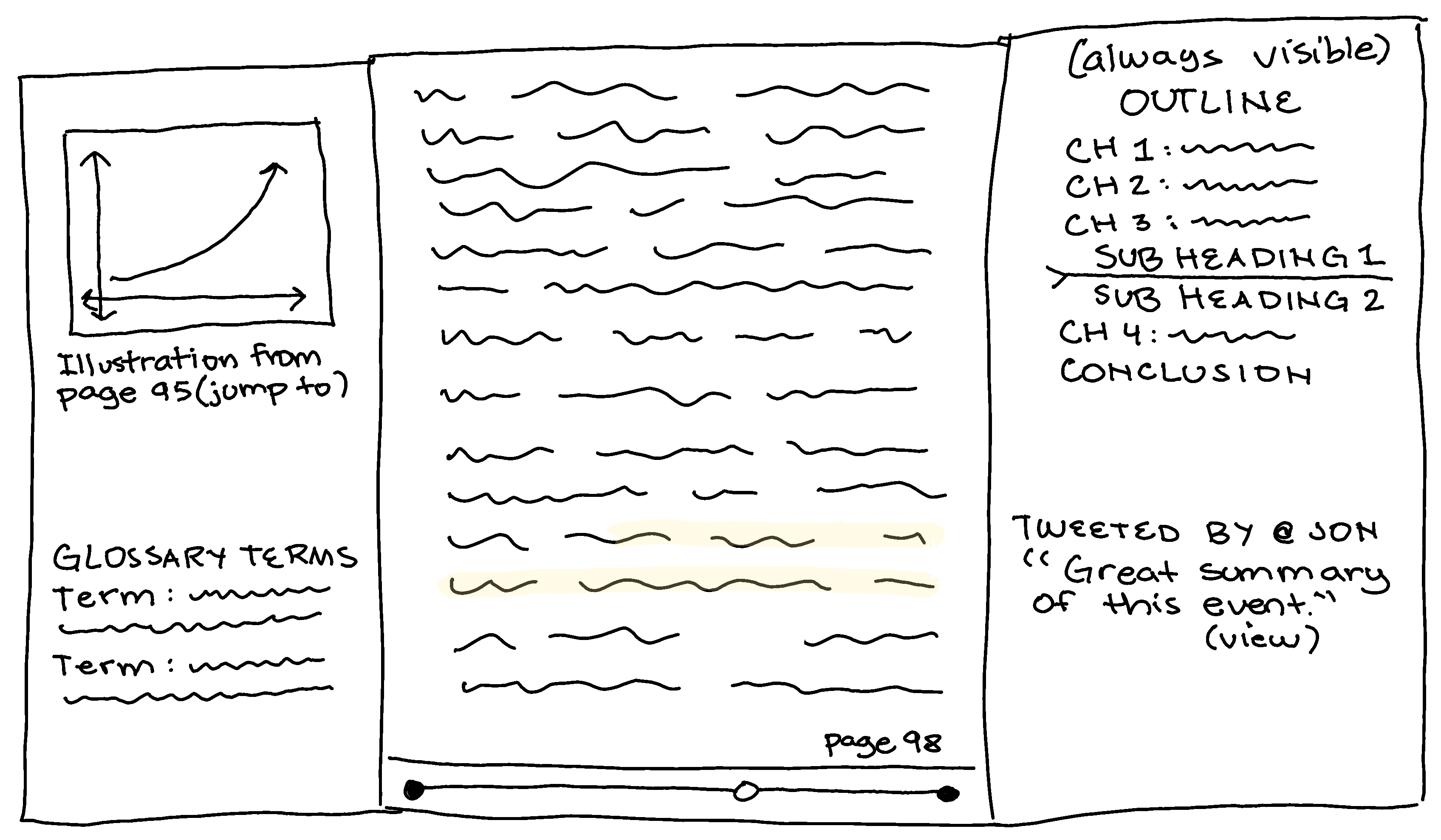
Reading is incredible and I love my Kindle. But eBooks today are just a step above OCR’ing a book and slapping on a few basic features which have existed for 30+ years. While I’m reading an eBook I want to:
-
Have relevant illustrations, graphs, and tables appear for duration of their mentions so I don’t have to flip back and forth between them.
-
See glossary terms and their definitions which appear on this page. Highlighting and searching a term is great but the author may have added important context to the glossary definition.
-
View popular annotations and highlights across all mediums - not just by other readers who own an Amazon Kindle readers and purchased this book version and also happened to highlight it enough times. A quote was referenced in 300 blog articles? A two sentence excerpt retweeted 50,000 times? You bet I want to know!
-
Follow referenced information easily. You cited a paper - great, let’s look at the footnotes. Oh, the full reference is in the back of the book. Online list of citations? Of course not! Drop a bookmark, navigate to the back of the book, pull out my laptop, find the paper. Of course, a paywall. Grab a snack. Acquire the PDF. Search for keywords to try to find the referenced information. Sigh, 2019.
-
Not be hindered by the DRM system. Copyright is important and I want to support authors but it’s insane to me all these content licenses I’m acquiring can’t be donated to a library upon account closure. Yes, legal DRM-free eBooks exist but they aren’t without their own issues.
-
Seamlessly switch between devices and formats while retaining my position. Something like Whispersync (a neat idea but come on, I’m not made of money. Also, see above points).
-
Let me use a digital or physical keyboard instead of an e-ink keyboard to type my annotations. A possibility here is a companion app, which feels like a notes app but ties my notes to their location/text in the book I’m reading.
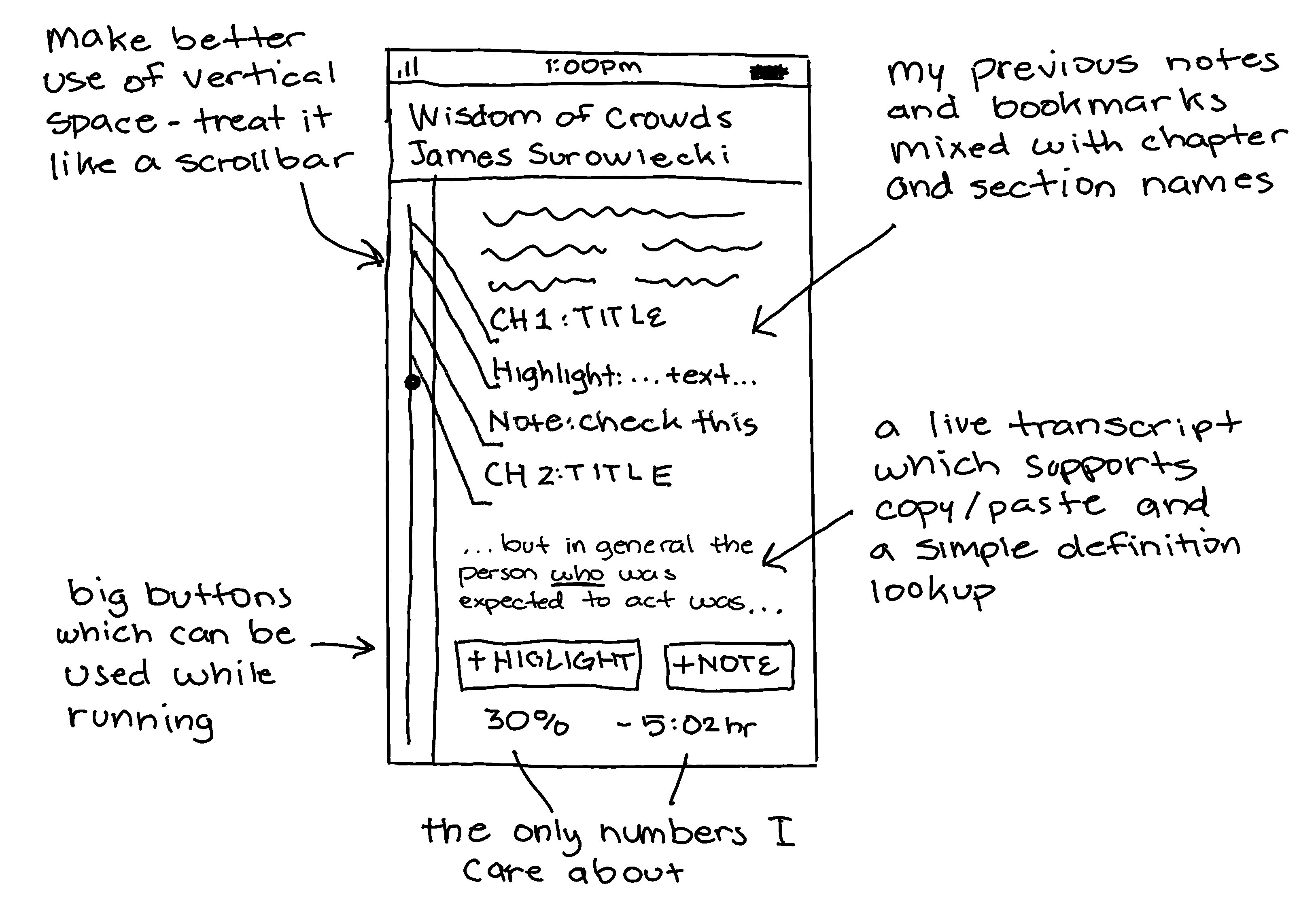
Most of these points above also apply to my experience listening to podcasts, audiobooks, and watching Youtube videos and interviews. I find myself wishing I could:
-
Navigate them more comfortably. Both Libby and Audible leave much to be desired in terms of navigation. Finding a quote I remember hearing to three days ago is basically blindly stumbling around - and I lose my current spot too. Seeing a list of chapter numbers for the book I’m listening to has been helpful a grand total of 0 times. And how cool would it be to drop a bookmark from my bluetooth-connected headphones as I’m biking down a street.
-
View an auto-generated transcript of a podcast as I’m listening to it. It should have easy-to-follow links to references to other podcasts, media, books and support searching for key terms. YouTube already transcribes all of their videos and Google Meet now generates live captions as we’re talking - why can’t we do something similar with podcast apps?
Honorable Mentions: Readwise, Weava, Descript, Otter.ai, Polar
A centralized search interface for my digital brain (memex)
I want to be able to open an interface, type three words, and instantly see results from everything my digital self has interacted with. Emails, years of full-text browsing history, text messages, Slack messages across all my organizations, calendar invites and events, books, podcast transcripts I’ve consumed, Twitter and Instagram DMs, PDFs I’ve downloaded, bash commands, videos I’ve seen, my online and offline files, notes, blog post drafts - I really do mean everything.
I acutely feel the need for this when I’m trying to find something I know I’ve seen online but can’t remember where I saw it. Google is wonderful for finding new information, but absolutely poor for re-finding things. Chrome’s history has so much potential - but I suspect Google would much rather have us look at their ads a few additional times rather than go direct to the source. I accept I might be in the minority on this one. Regardless, this tool should:
-
Accept and parse the following queries:
-
spacex announcement type:video 2016
-
links from:jon@test.org topic:python
-
paper on temperature, productivity referenced in book:Uninhabitable Earth
-
type:pdf habits digital interfaces
-
reading comprehension type:blog post
-
printer ink receipt
-
type:book read:2017 finance
-
file:py datetime parse
-
-
Respect my privacy: hosted on something I control and never mined for ads.
-
Support all my devices with two-way sync so I can search and add to it wherever I am.
-
Be extensible: allow me to easily ingest my own information and extend with desired functionality.
-
Cluster information based on content, tags, geo-location, connected people, conversations, source, and other factors I’m not even aware of.
-
Notify me about changes to documents and webpages I’ve visited.
-
Allow a rough export of my research on a topic (like, a knowledge dump off everything I’ve consumed on pandas) with the ability to easily share it.
Honorable Mentions: Memex by Worldbrain.io, Roam Research, Alfred, Trove, Local Native, ArchiveBox, Raindrop
Parting Thoughts
I’m fascinated with a better bridge between our minds and our digital devices. A well-designed tool should disappear and allow complete attention to the task at hand, but digital devices today are far from this ideal - often due to arcane copyright laws or profit-seeking. These aren’t new ideas by any means. See Vannevar Bush’s original conception of a memex over 70 years ago. We are way overdue for this. I see enormous potential at combining a true memex with all of our personal data (health, fitness, biometrics) along with our habits, goals, tasks, reflections, and communication tools.
It seems to me that as information becomes more abundant, the connections drawn between disparate pieces are becoming increasingly important. The easier it is to share that graph with other people, the faster we can learn from each other and understand complex relationships. I’m excited for a world where knowledge is easier to discover, validate, dispute, understand, retain, and share.
I hope to cover my thoughts on processes, note-taking apps, and knowledge graphs next. Stay tuned here. My thanks to Arthur Tyukayev, Alex Ly, David Heimann, Em deGrandpré, Alexey Guzey, Sam Tkachuk, and Brian Timar for reading drafts of this and providing wonderful feedback.
from Hacker News https://ift.tt/37K2sCR
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.