When it comes to the events, the big debate is about the contents of its body. Martin Fowler has written a great post on this topic.
Some devs argue that events should carry the complete load with it, I am calling them Fat Events (Event Carried State Transfer) in this blog.And then we have others who believe that events should be lightweight and containing minimum details, hence I call them Thin Events (Event Notification). In Thin Events, subscriber of the event is expected to request the required data after receiving the event.
Like every other dilemma in choosing suitable design patterns, this is a hard question to answer and it depends on various things. Lets compare them:
- Thin Events add coupling which is one of concerns we wanted to address by using events. It forces the event subscriber to call the publisher APIs to get more details. This means a subscriber cannot do its job if the publisher is down. In case of a bulk execution, it can adversely impact the APIs it will be calling. In contrast, Fat Events remove that dependency and lead to a better decoupling of the systems.
- The data in any event could be outdated by the time it is processed. This impacts both sides in quite opposite ways. Thin Events shine when the real-time information is crucial at the time of processing while Fat Events work better where sequential or point-in-time processing is required.
- Deciding the contents for an event is the part where Thin Events win, simply because it will only contain the bare minimum details for the subscriber to call back if required. But for Fat Events, we will have to think about the event body. We want to carry enough for all the subscribers but it comes at an expense: the publisher model would be coupled to the contract. It also adds an unnecessary dependency to consider in case you want to remove some data from the domain.
Thin Events do not cut it for me
From my experience so far, I think Thin Events does not offer anything that Fat Events cannot. As with Fat Events, the subscriber can also choose to call back the API if needed. In fact, I tried to think of an example where calling back the publisher is the only way to get the real time information but in those cases it felt like the bounded contexts are not cut right. However, in certain circumstances the use case may not allow putting the payload on the events if the published on uncontrolled/unprotected or low bandwidth infrastructure. In those cases event can carry a reference (URI) back to the change (e.g. resource, entity, event etc.).
So are Fat Events the answer?
It depends, though carrying the complete object graph with every event is not a good idea. Loosely coupled bounded contexts are meant to be highly cohesive to act as a whole, so when you create event of a domain model, the question is how far you go in the object graph i.e. to an aggregate, or a bounded contexts or includes entities outside bounded context as well. We have to be very careful, as noticed above, it tightly couple the event contents to your domain model. So we don’t want thin events then how fat our event should be?
There are two further options, event body based on the event purpose (Delta Event) or the aggregate it represents (Aggregate Event).
Delta Events
I am not sure if ‘Delta Events’ is a known term for this, but it is the best name I could think to describe the event contents. The basic concept is to make events carry ‘just enough details’ to describe the change in addition to the identity (Id) of the entities changed. Delta events work even better with the Event Sourcing because they are like a log of what has happened, which is the basic foundation of the Event Sourcing.
So in Delta Events, the contents can consist of:
- Public Id of the primary entity, that event is broadcast for.
- Fields that have changed in the event.
e.g. AccountDebited
{
AccountHolderUserId: <Account holder Id>
FromAccountNumber: "<Account Number that is debited from>"
ToAccountNumber: "<Account Number that money is credited to>"
Description: "Description of transaction"
AmountDebited: "<Amount that is debited from the account>"
Balance: "<Balance remaining after this transaction>"
TransactionId: "<To correlate with the parent transaction>"
}
The event above carries the complete details to explain what has happened along with the public Id of the entities involved.
Aggregate Event
We can make it a Fat Event and carry the additional content such as the Account holder name for the systems which may need that information e.g. notification, reporting, etc. But unfortunately, that will couple publisher domain unnecessarily to that data it does not need. So to work out the right content for the event, we will apply two key principles:
Domain-Driven Design: Scope the event body to the aggregate level. As Martin Fowlers explains in his post, aggregate is the smallest unit of consistency in Domain-Driven Design.
A DDD aggregate is a cluster of domain objects that can be treated as a single unit.
Data On The Outside: Events are an external interface of our system. So they fall into the “Data On the Outside” category explained in an excellent paper “Data on the Outside versus Data on the Inside” by Pet Helland. Applying the constraints of sharing data outside the bounded context, we will send a complete snapshot of the aggregate, including the fields that didn’t change as part of the event. This allows the consumer to keep the point-in-time reference of the state. I have unpacked this concept in my other post: https://codesimple.blog/2021/03/14/events-on-the-outside-vs-events-on-the-inside/
By following these principles, the body of the event contains the model for the aggregate (i.e. transaction) and a sequence number to highlight the point in time reference to the state of the aggregate.
e.g. AccountDebited
{
Sequence: Timestamp / Sequence Number,
Transaction: {
TransactionId: "<To correlate with the parent transaction>",
FromAccountNumber: "<Account Number that is debited from>",
ToAccountNumber: "<Account Number that money is credited to>",
Description: "Description of transaction",
Amount: "<Amount that is debited from the account>",
Balance: "<Balance remaining after this transaction>"
}
}
How does the subscriber get the missing pieces?
In both above event types, there can be some related information that is not present in the event body e.g. references to entities of other bounded context such as account holder name. It depends on the situation, for a new subscriber you may want to listen to the other events in the system and build a database of the subscriber’s domain.
Let’s assume we have a Notification domain that will send an SMS to the account holder whose account will be debited if the amount to debit is above $100.00. SMS body would be like:
Hi <First Name> <Last Name>,
Your account number <account number> is debited. Transaction details:
Amount: $<amount>
Remaining Balance: $<remaining balance>
Description: $:<Transaction description>
For the sake of an example, lets assume our system is cut into the following sub domains:
- User Profile: Maintains account holder details such as Name, Address, Mobile Number and Email etc.
- Notification: Maintain user preferences about receiving notifications and sending notifications.
- Accounts: Maintain ledger of debits and credits of accounts
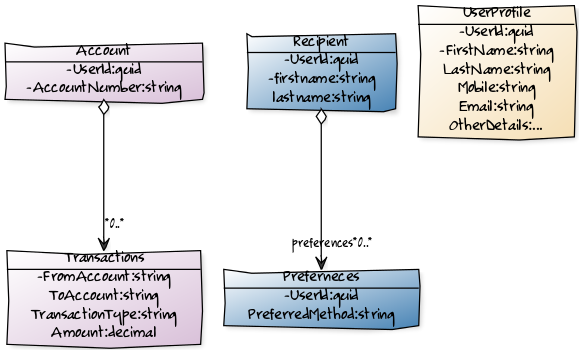
To send the SMS, we have almost all the details in the event body except the account holder name and mobile number of the recipient. In our imaginary system, it is the user profile domain that has those details instead of the accounting domain, that is broadcasting the event. There are two things that can happen here:
Notification domain can call the User Profile to get more details before sending the SMS. So now we always get the up to date contact details of the user but at the cost of run time dependency. If User Profile system is down for any reason, it would break the notification system as well.
OR
We can make the notification system listen to the events from the User Profile system as well to maintain a local database of its recipients (translated from account holders) along with their notification preferences. e.g.
- UserProfileAdded
- UserProfileUpdated
I prefer the later option to keep the system decoupled and avoid run time dependency. The workflow will be like this:
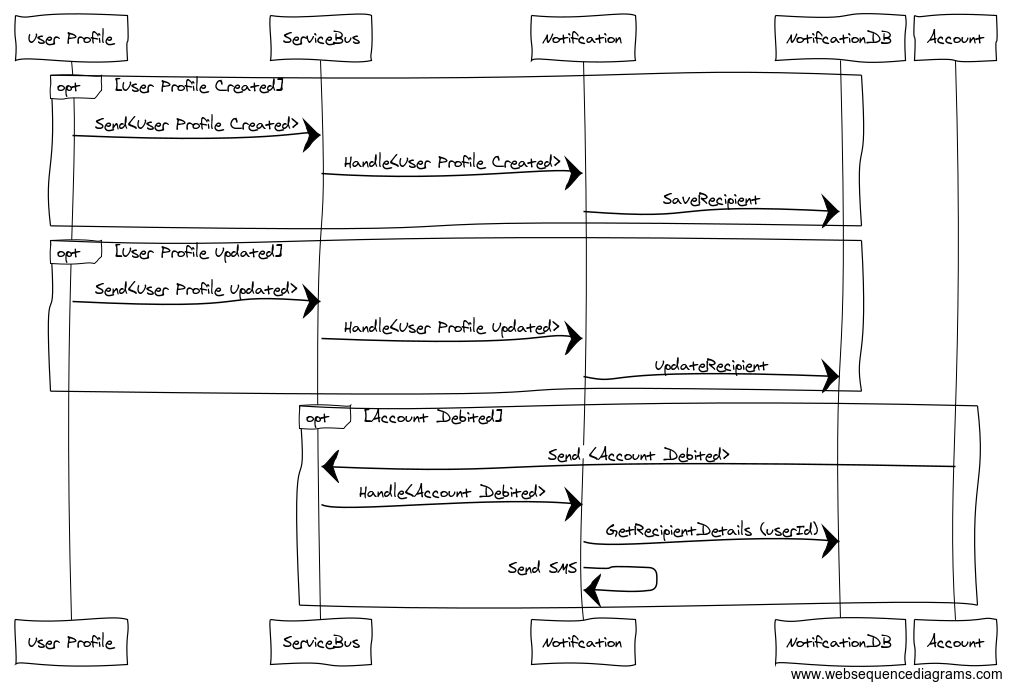
The subscriber will build the store as they go, but still there can be scenarios where they don’t have this data:
- New Subscriber
- An event lost for some reason – not sent, not delivered, delivered but failed etc.
For the first scenario you can start with some data migration to give it a seed data, but for the second case data migration may not work. I have dealt with this situation by introducing a snapshot builder.
Snapshot Builder:
If subscriber does not know about the entity it has received in the event, it would call the relevant systems and build a snapshot. This can be quite handy in scenarios where occasionally the subscriber needs to sync its data (translated from other domains) with the original owner of the data.

I hope you find this post useful, if not the complete approach, it may give you some options to consider when thinking about the event contents.
from Hacker News https://ift.tt/8PTmxop
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.