Cosmopolitan makes C a build-once run-anywhere language, similar to Java, except it doesn't require interpreters or virtual machines be installed beforehand. Cosmo provides the same portability benefits as high-level languages like Go and Rust, but it doesn't invent a new language and you won't need to configure a CI system to build separate binaries for each operating system. What Cosmopolitan focuses on is fixing C by decoupling it from platforms, so it can be pleasant to use for writing small unix programs that are easily distributed to a much broader audience.
Getting Started
Assuming you have GCC on Linux, then all you need are the five additional files which are linked below:
# create simple c program on command line echo ' main() { printf("hello world\n"); } ' >hello.c # run gcc compiler in freestanding mode gcc -g -Os -static -fno-pie -nostdlib -nostdinc -o hello.com hello.c \ -Wl,--oformat=binary -Wl,--gc-sections -Wl,-z,max-page-size=0x1000 \ -Wl,-T,ape.lds -include cosmopolitan.h crt.o ape.o cosmopolitan.a # ~40kb static binary (can be ~16kb w/ MODE=tiny) ./hello.com
The above command fixes GCC so it outputs portable binaries that will run on every Linux distro in addition to Mac OS X, Windows NT, FreeBSD, and OpenBSD too. For details on how this works, please read the αcτµαlly pδrταblε εxεcµταblε blog post. This novel binary format is also optional: conventional ELF binaries can be compiled too by removing the -Wl,--oformat=binary flag.
Your program will also boot on bare metal too. In other words, you've written a normal textbook C program, and thanks to Cosmopolitan's low-level linker magic, you've effectively created your own operating system which happens to run on all the existing ones as well. Now that's something no one's done before.
Performance
Cosmopolitan has been optimized by hand for excellent performance on modern desktops and servers. Compared with glibc, you should expect Cosmopolitan to be almost as fast, but with an order of a magnitude tinier code size. Compared with Musl or Newlib, you can expect that Cosmopolitan will generally go much faster, while having roughly the same code size, if not tinier.
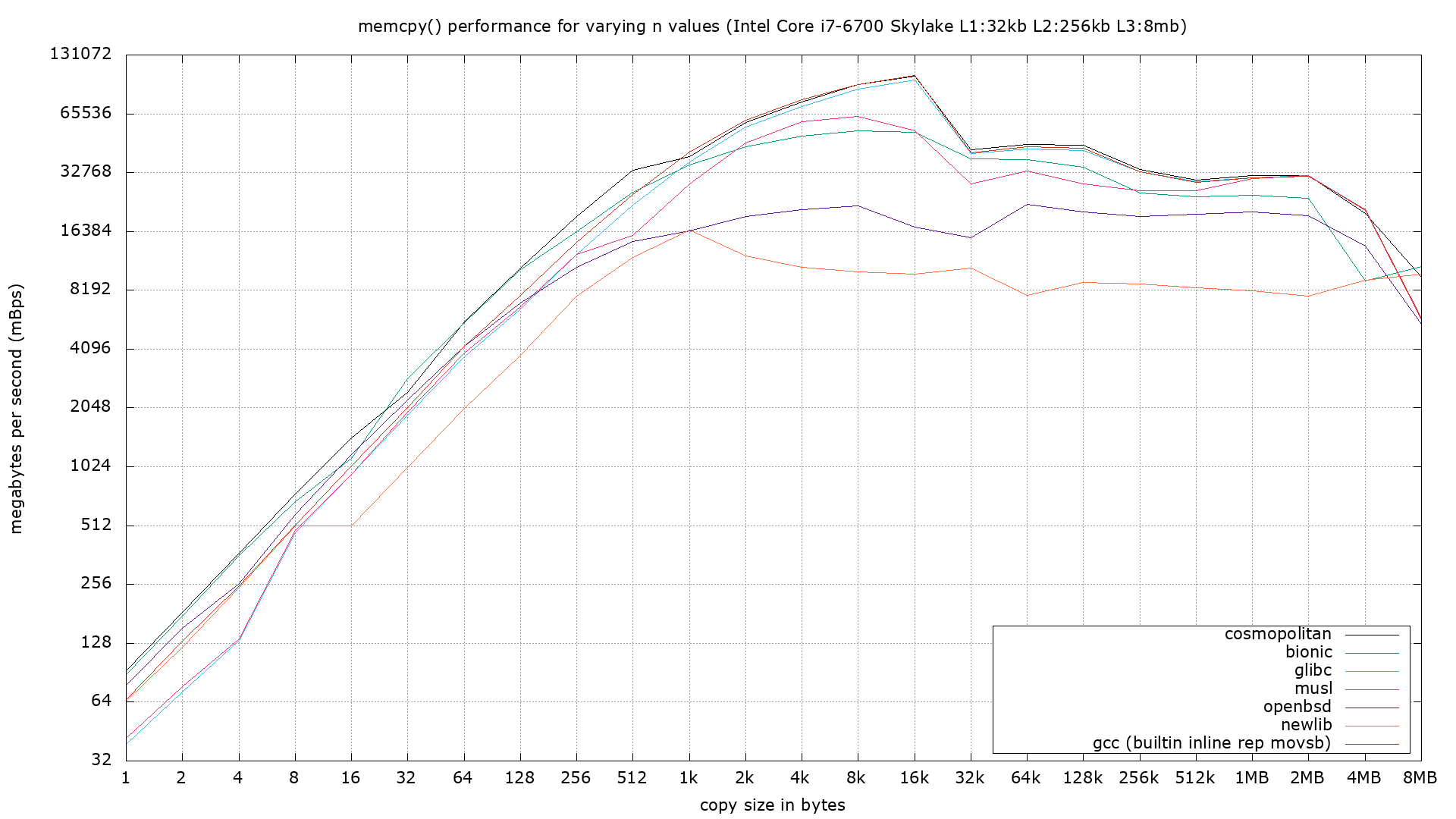
In the case of the most important libc function, memcpy(), Cosmopolitan outperformed every other open source library tested. The chart below shows how quickly memory is transferred depending on the size of the copy. Since it's log scale, each grid square represents a 2x difference in performance. What makes Cosmopolitan so fast here is it uses uses several different memory copying strategies. For small sizes it uses an indirect branch with overlapping moves; for medium sizes it uses simd vectors, and for large copies it uses nontemporal hints which prevent cache trash. Other libraries usually fall short because they use a one-size-fits-all strategy. For example, Newlib goes 10x slower for the optimal block size (half L1 cache) because it always does nontemporal moves.
Trickle-Down Performance
Performing the best on benchmarks isn't enough. Cosmopolitan also uses a second technique that the above benchmark doesn't measure, which we call "trickle-down performance". For an example of how that works, consider the following common fact about C which that's often overlooked. External function calls such as the following:
memcpy(foo, bar, n);
Are roughly equivalent to the following assembly, which leads compilers to assume that most cpu state is clobbered:
asm volatile("call memcpy" : "=a"(rax), "=D"(rdi), "=S"(rsi), "=d"(rdx) : "1"(foo), "2"(bar), "3"(n) : "rcx", "r8", "r9", "r10", "r11", "memory", "cc", "xmm0", "xmm1", "xmm2", "xmm3", "xmm4", "xmm5", "xmm6");
In other words the compiler assumes that, in calling the function, fifteen separate registers and all memory will be overwritten. See the System V ABI for further details. This can be problematic for frequently-called functions such as memcpy, since it inhibits many optimizations and it tosses a wrench in the compiler register allocation algorithm, thus causing stack spillage which further degrades performance while bloating the output binary size.
So what Cosmopolitan does for memcpy() and many other frequently-called core library leaf functions, is defining a simple macro wrapper, which tells the compiler the correct subset of the abi that's actually needed, e.g.
#define memcpy(DEST, SRC, N) ({ \ void *Dest = (DEST); \ void *Src = (SRC); \ size_t Size = (N); \ asm("call memcpy" \ : "=m"(*(char(*)[Size])(Dest)) \ : "D"(Dest), "S"(Src), "d"(n), \ "m"(*(char(*)[Size])(Src)) \ : "rcx", "xmm3", "xmm4", "cc"); \ Dest; \ })
What this means, is that Cosmopolitan memcpy() is not simply fast, it also makes unrelated code in the functions that call it faster too as a side-effect. When this technique was first implemented for memcpy() alone, many of the functions in the Cosmopolitan codebase had their generated code size reduced by a third.
For an example of one such function, consider strlcpy, which is the BSD way of saying strcpy:
/** * Copies string, the BSD way. * * @param d is buffer which needn't be initialized * @param s is a NUL-terminated string * @param n is byte capacity of d * @return strlen(s) * @note d and s can't overlap * @note we prefer memccpy() */ size_t strlcpy(char *d, const char *s, size_t n) { size_t slen, actual; slen = strlen(s); if (n) { actual = MIN(n, slen); memcpy(d, s, actual); d[actual] = '\0'; } return slen; }
If we compile our strlcpy function, then here's the assembly code that the compiler outputs:
/ compiled with traditional libc strlcpy: push %rbp mov %rsp,%rbp push %r14 mov %rsi,%r14 push %r13 mov %rdi,%r13 mov %rsi,%rdi push %r12 push %rbx mov %rdx,%rbx call strlen mov %rax,%r12 test %rbx,%rbx jne 1f pop %rbx mov %r12,%rax pop %r12 pop %r13 pop %r14 pop %rbp ret 1: cmp %rbx,%rax mov %r14,%rsi mov %r13,%rdi cmovbe %rax,%rbx mov %rbx,%rdx call memcpy movb $0,0(%r13,%rbx) mov %r12,%rax pop %rbx pop %r12 pop %r13 pop %r14 pop %rbp ret .endfn strlcpy,globl |
/ compiled with cosmopolitan libc strlcpy: mov %rdx,%r8 mov %rdi,%r9 mov %rsi,%rdi call strlen test %r8,%r8 je 1f cmp %r8,%rax mov %r8,%rdx mov %r9,%rdi cmovbe %rax,%rdx call MemCpy movb $0,(%r9,%rdx) 1: ret .endfn strlcpy,globl |
That's a huge improvement in generated code size. The above two compiles used the same gcc flags and no changes to the code needed to be made. All that changed was we used cosmopolitan.h (instead of the platform c library string.h) which contains ABI specialization macros for memcpy and strlen. It's a great example of how merely choosing a better C library can systemically eliminate bloat throughout your entire codebase.
from Hacker News https://ift.tt/34N3qOY
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.