Reinforcement Learning (RL) should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose pretrained models, rather than a paradigm that can bootstrap intelligence from scratch.
Most contemporary reinforcement learning works involve training agents “tabula-rasa”, without relying on any sort of knowledge about the world. So when solving a task(s), the agent not only has to optimize the reward function at hand, but in the process also discover how to see, how physics works, what consequences its actions have, how language works, and so forth. This tends to work okay in simulations where we can collect infinite data, and don’t need to discover a lot of common-sense knowledge because the simulators themselves are quite niche. But it breaks down when solving tasks in the real world which has fractals of complexity and practical limits on how much data we can collect.
To train agents on real-world data, why don’t we simply endow them with knowledge about the real world, and let the RL algorithms focus on what they are good at: black-box optimization of a reward function.
Thanks to large-scale self-supervised models trained on the internet — ones that soak up enormous amounts of physical and cultural knowledge, we now have a way of doing so. After training general-purpose pre-trained models, reinforcement learning (and/or search) can be used to fine-tune them to amplify their capabilities — making them experts at a particular tasks (goal-directedness), providing them agency, learning from feedback, aligning them with human values, and many more.
RL fine-tuning provides a way out of the “simulation trap”, and lets us train agents on real world data and environments directly.

Fig: Pre-training and RL fine-tuning, a two stage process. While pre-trained models are super general, RL fine-tuning can make them highly capable at individual tasks.
Why RL fine-tuning over other alternatives?
Now, it’s natural to ask why don’t we just use prompts to discover capabilities (Just ask for Generalization), or use supervised learning to fine-tune. RL fine-tuning stands out in a few ways:
There’s very little work that treats RL as a fine-tuning paradigm, but this should change — for the advantages of RL-fine tuning are plain in sight. Here’s a couple of examples of how RL-fine tuning is used in practice:
Making GPT-3 an expert summary writer
Consider the capability of writing high-quality summaries of books or news articles, as judged by human readers.
We can start off by prompting a large language model like GPT-3 with well written summaries, but we can only fit a few examples before we run out of prompt length. We can go one step further, collect a dataset of (article, summary) pairs written by humans and do supervised fine-tuning on this dataset. However there’s a subtle difference in this objective (mimic human written text) vs the true objective (generate high-quality outputs as determined by humans). This can manifest in written summaries that look human-like, but contain factual errors for example. Moreover, we are limited to the quality of the dataset, and it’s hard to write summaries of better quality than those provided in the dataset.
We can instead directly optimize the true objective by first learning a reward function corresponding to it (by asking humans to rank summaries), and then use this reward function to fine-tune GPT-3 using RL. This is called reward modelling, and is the approach taken in Learning to Summarize from Human Feedback.
Most tasks in the real world are of a similar flavor—we don’t have an idea of how to write down a precise objective that corresponds to it. In lieu of that, learning a reward function directly from human intentions serves as a reasonable proxy for constructing objectives that align with human values.
The scaling curves for the summarization task highlight a pretty important point: scaling laws for RL as fine-tuning are more favorable than prompts or supervised learning. And for the same model-size, RL can significantly amplify the summarization capability of GPT-3 over supervised learning (SL). This is not a one-off phenomenon, we’ve also seen this occur in AlphaStar where RL fine-tuning improves performance over RL or SL alone.
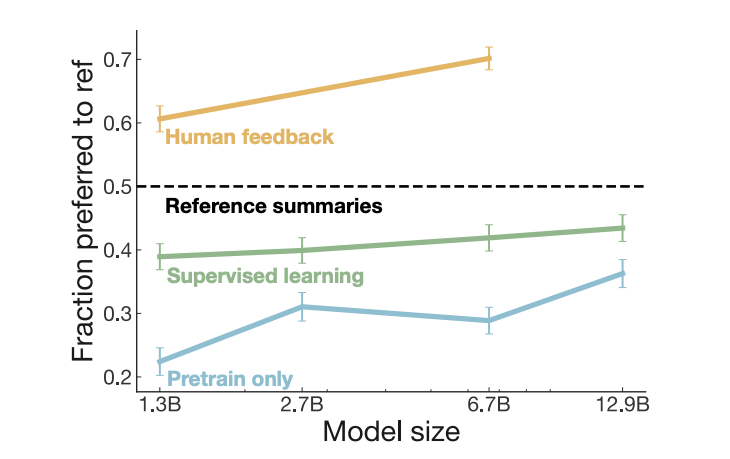
Fig: Scaling curves for prompt based generalization, supervised fine-tuning and RL fine-tuning for the summarization task. Figure from Learning to Summarize from Human Feedback
A neat thing about having a next-step prediction model is that we can treat is as a dynamics model of the environment (in this case, language). So, once we have access to a reward function, we can do search (planning) over the pre-trained model directly. This papers leverages this to generate a bunch of summaries and select the one which our reward model says has the highest quality.
Adding agency to pre-trained models
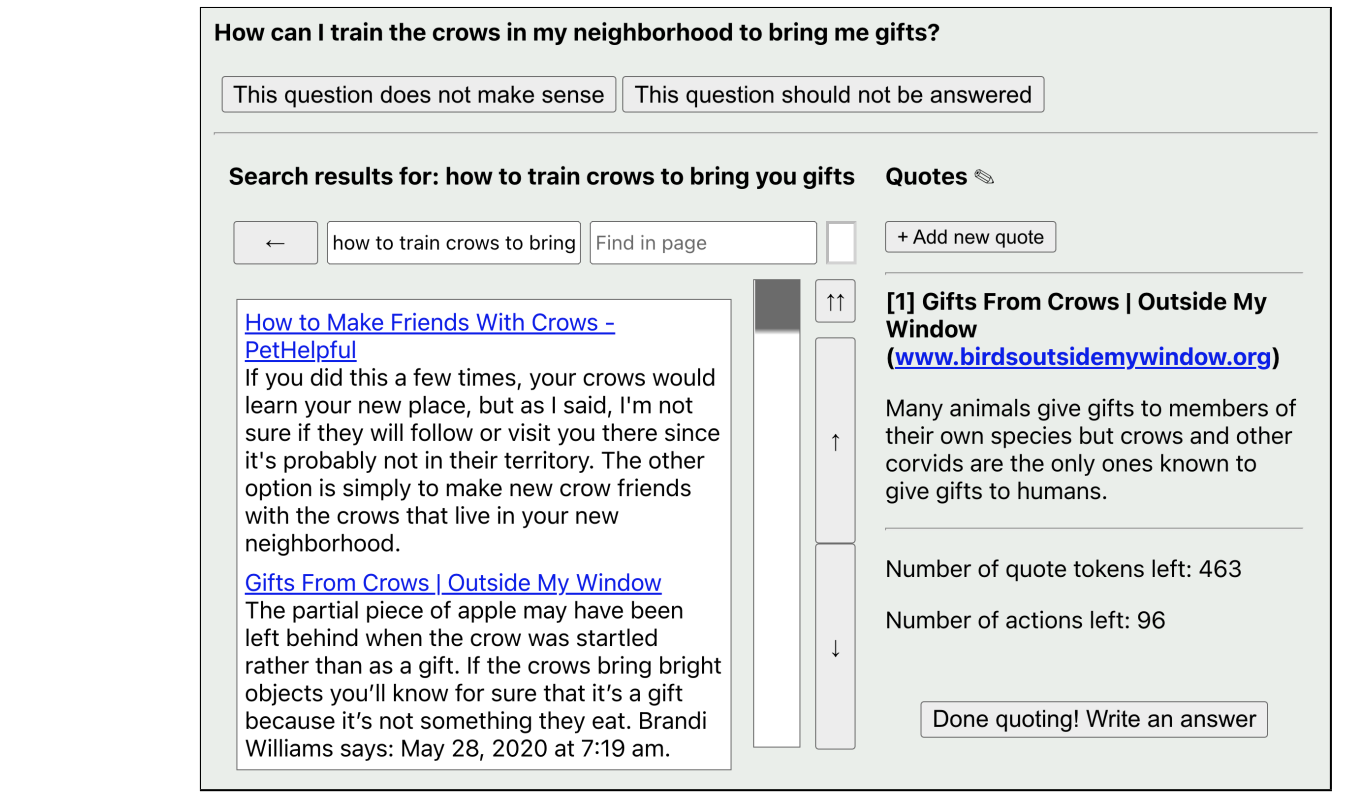

Fig. Pre-trained models without notions of agency (GPT-3 and CLIP) acting in interactive environments after being fine-tuned with imitation learning. Left: A text-based browser environment from Web-GPT. Right: A table-top robotic manipulation scene from CLIPPort.
Many tasks in the real world inherently involve an action, perception loop. An agent has to take actions repeatedly in order to solve tasks. Prediction based models by default don’t have agency, and thus can’t perform tasks that require taking repeated actions (like browsing the internet, or manipulating objects). However, they can be fine-tuned to “inject” agency as a meta-capability.
In Web-GPT, a GPT-3 model is fine-tuned to browse the internet. In CLIPPort, CLIP is fine-tuned to perform language conditioned manipulation tasks (for ex: “pack the scissors in the brown box”).
Both these papers primarily use imitation learning to learn policies, but it’s not hard to imagine RL versions of these.
Summary:
It’s more productive to view RL as a fine-tuning paradigm that can add capabilities to general-purpose pre-trained models, rather than viewing it as a self-sufficient paradigm to bootstrap intelligence. By separating concerns, RL fine-tuning overcomes limits of the scaling and RL paradigms individually, and provides a simple recipe of training agents which can have a multitude of capabilities over time.
Thanks to Sherjil, Ethan, Nitarshan, Bogdan and Hattie for reading earlier drafts of this post and providing valuable feedback.
from Hacker News https://ift.tt/3ty0rar
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.