Stable Software Release System
A while ago, i wrote an article called "Never update anything" that brought to light some of the issues with our current approaches to versioning software and the shortcomings of semantic versioning in particular. However, while i did offer some suggestions for creating more stable software at a slower pace, it feels to me that it'd require its own versioning system.
This article is an attempt at describing one such system, which i will probably end up using it for my own SaaS business in the coming years and i urge others to have at least a brief look at some of the ideas presented in this article.
Why we need a new versioning system
The pace at which we move along is too fast, with new features in our software being released every month, if not every week. At the same time, however, the majority of the software costs still lie in the maintenance process (PDF link). We do expect to write our software once and to have it work for as long as necessary in lieu of bug fixes or us needing to add new features ourselves, as opposed to this metaphorical rug of stability being pulled out from under our feet by a seemingly innocent update at some point in time. In this context, added features and changes to the state of our libraries, dependencies or software packages all imply it being more akin to a spreading infection, rather than useful additions to our toolbox.
At the same time, as stated in that other article of mine, we can't not update our software either - due to some very unfortunate realities of our world, we'll still need very particular otherwise non-breaking bug fixes or at the very least to get regular security updates as necessary. And yet, you try convincing anyone, for example, the developers of MySQL or MariaDB, to have branches of their codebases and versions that do nothing apart from fixing bugs in perpetuity - in most cases, new features (and thus risks) will still be snuck in, because branching the whole codebase and then backporting fixes will only lead to utter chaos due to simple mathematics. If you have 5 feature releases per year and you want to support each release for 5 years, then after 5 years you'll need 25 separate versions of your codebase. No one can deal with that level of branching.
Many of the larger corporations out there just sidestep this issue entirely, by just dropping software for releases that are older than X years. This, coupled with minor releases being the only way to get updates which shouldn't break compatibility, but in practices sometimes do anyways, leads to us never being able to rely upon our dependencies, without having extensive test suites in place and us not being ready to keep up with the release notes and these release cycles. And, as my experience shows, this only ever leads to working with deprecated and insecure packages, even in governmental systems. That's unacceptable, we need to do better, or at least move in the direction of doing better.
What's wrong with our current approaches
Furthermore, the major versions and the feature versions don't actually mean anything. For example, if we take a piece of software with the version of 5.7.36 and another version of 8.0.27, what does that actually tell us? Do we have any idea of what's in these versions or even what we're currently looking at? It doesn't and i'd posit that that's also a problem. Once you have a project that has a pom.xml with about 100 to 200 external libraries as dependencies, you'll understand my suffering - to figure out what needs updating and how old each of those packages are, you can't just look at the version numbers which in this case are just nonsensical strings of text, but have to open the release history for each of them (or find out a way to automate it, which can be either painful or impossible, depending on how much time/knowledge you have).
Luckily, some of the software packages out there have actually been surprisingly sane in this regard and format their versions in a way that immediately gives you a better idea of what you're looking at. For example, let's look at my install of IntelliJ IDEA, a lovely Java IDE by JetBrains:
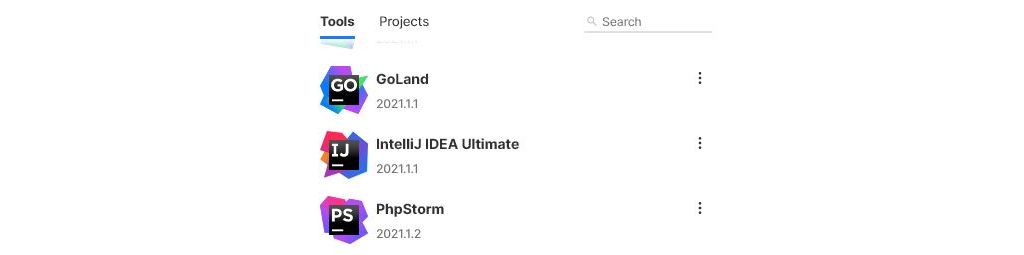
While the latter versions are similarly meaningless to the example above, the inclusion of the release year gives you immediate feedback about how old the particular piece of software is. Seeing 2015. there would without a doubt make you more concerned than seeing 2020. would and rightfully so! That's a simple, yet a very clear example of why having the versioning system encode information like that would be useful. But let's look at some more software, for example, releases of Ubuntu:

Not only do we have the release year given, but we also see that we're dealing with a long term support (LTS) version, which should be more stable than the latest ones by definition! While the latter numbers within the version still are pretty useless to an outsider, because frankly you can't encode everything that has changed into a short string without having a full changelog somewhere, knowing which "edition" of the software we're dealing with is still nice!
Similarly, the Unity game engine also adopts an approach that's very much like what Ubuntu does:
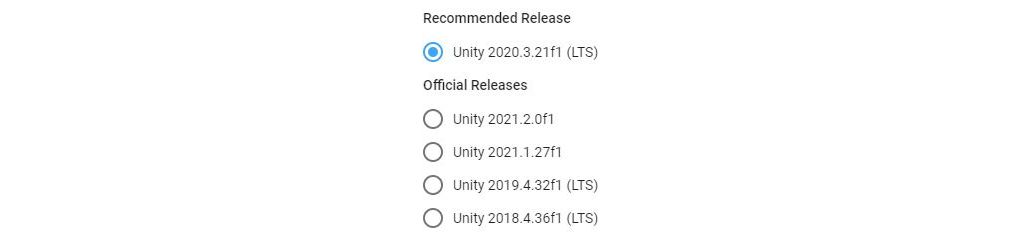
In my eyes, that sort of versioning is very close to what should be used in any and all pieces of software, at least until something better comes along. Yet, it seems like these approaches haven't really seen more widespread success, or at least no one tries talking about them that much. So, let's shamelessly steal some of these good practices that have vaguely shown up over the years in many of the projects out there, and let's give them a formalized name and a list of instructions to describe them.
Introducing...

(the "the" was dropped because it didn't look pretty in an image with 2 lines of text)
In the spirit of the SemVer site, let's give some formal guidelines:
Each release must use the following format: YEAR-TYPE-NUMBER
Where:
YEAR - is the current year, for example, 2021
TYPE - is the release type, depending on project specifics; suggested values are "stable" (the equivalent of LTS) and "latest" (for development releases and rolling releases)
NUMBER - is an unsigned integer, starting at 0 and is incremented with each next release for that particular YEAR & TYPE combination

Because of the format above, you may have "large" releases which bundle breaking changes of any kind at most once per year.
Everything else depends on the TYPE value. Following the recommended naming above:
stable - will only contain non-breaking backwards compatible changes: bug fixes and security updates
latest - will contain feature releases of any sort, which add new functionality to the codebase
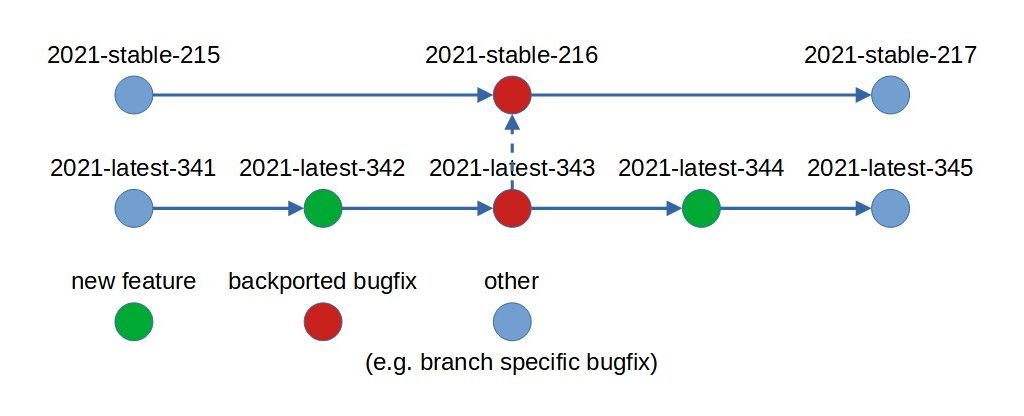
Because of the grouping above, for each "large" (yearly) release you'll have a split of your codebase into no more than 2 branches, one which will introduce new functionality and another that will only have backported fixes.
These should be developed in parallel, also addressing the slowly diverging codebases and providing each version with fixes for their unique contents.
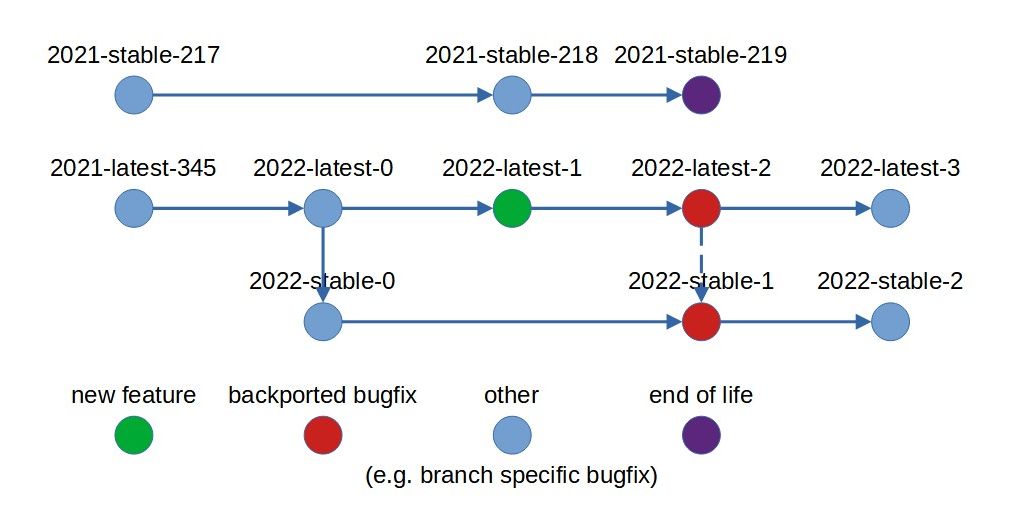
At the end of a year, the current "latest" release can become the next "large" (yearly) release, while also splitting off into a new "stable" release at that point in time.
Thus, updating between versions may be done in the following manner:
stable - the people using any stable release may continue to do so throughout its lifecycle (depending on the project, whether it's supported for 1 year or 5 years)
latest - the people using any latest release may continue to use the new features, until eventually either migrating over to the next "latest" release, or choosing to stick with the next "stable" release
The long term implications
That's about it! Now, personally, i'd say that the above method is better than semantic versioning and most others due to a variety of reasons:
- it's extremely simple to implement
- it gives you immediate information about how old any system or dependency is
- every "latest" version eventually becomes a "stable one", so that you can switch over to that if you only need a particular new feature in one point in time but want to settle down later
- alternatively, you can treat the consequent "latest" versions as rolling release, since it's one uninterrupted codebase, if you can keep up with the changelogs, you can always run the latest software
- older "stable" versions can eventually not worry about parity with the latest ones for backporting, since eventually they won't have a corresponding "latest" version to match and will be standalone; these are the JDK 8 and MySQL 5.7 of the world, on which much of the world runs on
- better yet, knowing that there's bound to be an EOL for a particular "stable" version, a migration guide should be easy to create; for example, if you choose to support your LTS releases for 5 years, you'll know that you'll need at least 1 guide for the 2020-stable-NUMBER version to something newer, one for 2021-stable-NUMBER to something newer and so on
- best of all, the TYPE part of the version can correspond to Git branches 1:1, further simplifying anything, since most projects out there already have a development and maintenance branch of some sort
- it should satisfy everyone within your community, both those that want stable software that doesn't break, as well as those who want all of the latest features
- oh, and it keeps the bits that no one actually cares much about (the sequential version number) as simple as possible - a numeric value that gets incremented, a stark contract to how in practice minor versions in semantic versioning still routinely break things; if you're on "stable", that's not allowed by definition, end of story
So, once you put all of it together, you get a very simple and elegant system, a bit like the combination of the images above:
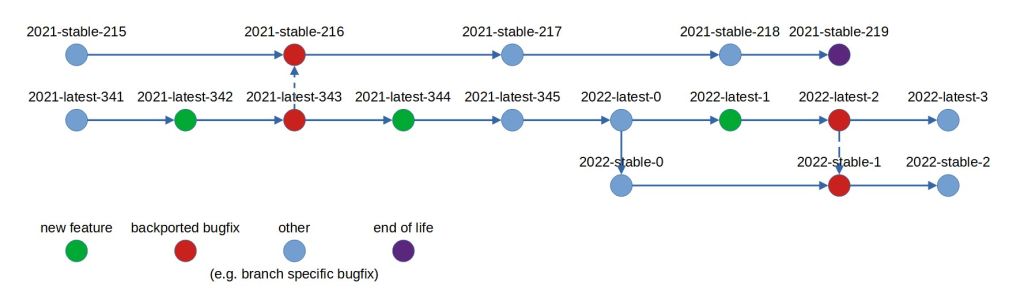
Caveats:
- there will always be opposition with arguments along the lines of "don't you want new non-breaking feature enhancements", which is highly situational and actually might be what you're after
- in practice, some companies out there have overcomplicated release strategies, like 4 or 5 parallel feature releases, each released and tested separately - this approach sadly allows you to do that with the TYPE values, which can match said features, e.g. 2021-stable-24, 2021-tournaments-244, 2021-judging-241, which i'd personally avoid; feature branches are for version control only, don't fragment your release strategy that much
- you can still go from 2021-latest-343 to 2021-stable-216, which in the context of this particular changeset seems nonsensical, 343 shouldn't be followed by 216; however this is by design, since if you'd attempt to increment the stable version number, you'd oftentimes skip numbers, or alternatively would put yourself in a world of hurt once your stable versions would get ahead of the latest ones but you'd still need to merge something from latest into the stable version; this remains unacknowledged as an actual problem
- the above approach won't magically make your code more stable in of itself, you still only should commit "mostly stable" code to branches that you'll release, with special care given to the "stable" release type; alas, your feature branches still are the ones that can be unstable, but need to have any problems addressed before being merged and released
- furthermore, there's the implication that around the turn of the year you'd probably set aside anywhere from a month to a quarter of a year towards fixing the outstanding technical debt, so that your next "stable" release can live up to its name upon being released to the public; frankly, it's probably not necessary for the projects that keep on top of their technical debt and pay it back as they're developing their software, but in my experience those are about as rare as unicorns
Summary
In summary, looking at the above, i think i've basically described how and why Git branches with some additional tag information should be used as a basis for versioning as opposed to semantic versioning with its abstraction that doesn't really conform to how branching works, nor is reflected well upon by the abilities of the average developer to recognize the difference between a minor version and a patch.
Actually, i don't think that that's a bad thing and would definitely lessen the cognitive load. I actually remember rather liking how SVN had numbered revisions which seemed more reasonable than Git hashes for figuring out how sequential changes happened. If Git and its branches get us most of the way there already, why not just stand on the shoulders of giants and throw in some easily automated text generation for the CI server to take care of, whilst remembering just a few very simple rules?
from Hacker News https://ift.tt/3kTPOth
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.