Faster software through register based calling
Posted on
The release notes for Go 1.17 mention an interesting change in the Go compiler: function arguments and return values will now be passed using registers instead of the stack
. The proposal document for the feature mentions an expected 5-10% throughput improvement across a range of applications
which is significant, especially for no effort on the developers part aside from recompiling with a newer version of the Go compiler. I was curious to see what this actually looks like and decided to take a deeper look. This will get more than a little nerdy so buckle up!
Note that although the catalyst for this blog article was a change in Go, much of this article should be of interest generally even if you don't use Go.
Refresher: Registers
At this point it's helpful to remind ourselves of what CPU registers are. In a nutshell, they are small amounts of high speed temporary memory built into the processor. Each register has a name and stores one word of data each - this is 64 bits on almost all modern computers.
Some registers are general purpose while others have specific functions. In this article you'll come across the AX, BX and CX general purpose registers, as well as the SP (stack pointer) register which is special purpose.
Refresher: the Stack
It's also useful to remind ourselves what the stack is in a computer program. It's a chunk of memory that's placed at the top of a program's memory. The stack is typically used store local variables, function arguments, function return values and function return addresses. The stack grows downwards as items are added to it.
Eli Bendersky has an excellent article about how stacks work which contains this helpful diagram:
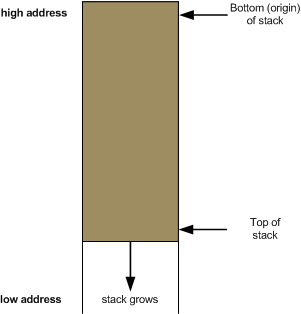
When items are added to the stack we say that they are pushed onto the stack. When items are removed from the stack we say that they are popped off the stack. There are x86 CPU instructions for pushing and popping data onto and off the stack.
The SP register mentioned earlier points to the item currently at the top of the stack.
Note that I'm taking some liberties here. The stack works like this on x86 computers (and many other CPU architectures) but not on all of them.
Calling Conventions
In compiled software, when some code wants to call a function, the arguments for that function need to somehow be passed to the function (and the return values need to be passed back somehow when the function completes). There are different agreed-upon ways to do this and each style of passing arguments and return values around is a "calling convention".
The part of the Go 1.17 release notes quoted above is really about a change in Go's calling conventions.
This is all hidden from you unless you're programming in assembler or are trying to make bits of code written in different programming languages work together. Even so, it's still interesting to see how the machinery works under the hood.
A Small Program
In order to compare the code the Go compiler generates in 1.16 vs 1.17 we need a simple test program. It doesn't have to do much, just call a function that takes a couple of arguments which then returns a value. Here's the trivial program I came up with:
package main
import "fmt"
func add(i, j int) int {
return i + j
}
func main() {
z := add(22, 33)
fmt.Println(z)
}
Disassembling
In order to see the CPU instructions being generated by the Go compiler we need a disassembler. One tool that can do this is venerable objdump which comes with the GNU binutils suite and may already be installed if you're running Linux. I'll be using objdump in this article.
The Go build pipeline is a little unusual in that it generates a kind of bespoke abstract assembly language before converting this to actual machine specific instructions. This intermediate assembly language can be seen using the
go tool objdump
command.
It's tempting to use this output for our exploration here but this intermediate assembly language isn't necessarily a direct representation of the machine code that will be generated for a given platform. For this reason I've chosen to stick with objdump.
Go 1.16's Output
Let's take a look at the output from Go 1.16 which we expect to be using stack based calling. First let's build the binary using Go 1.16 and make sure it works:
$ go1.16.10 build -o prog-116 ./main.go
$ ./prog-116
55
My Linux distro already had Go 1.17.3 installed and I used the approach described in the
official docsfor installing Go 1.16.10.
Great! Now lets disassemble it to see the generated instructions:
$ objdump -d prog-116 > prog-116.asm
The first thing I noticed is that there's quite of lot of code:
$ wc -l prog-116.asm
164670 prog-116.asm
That's a lot of instructions for such a small program but this is because every Go program includes the Go runtime which is a non-trivial amount of software for scheduling goroutines and providing all the conveniences we expect as Go developers. Fortunately for us, the instructions directly relating to the code in our test program are right at the bottom:
(I'm omitting the offsets and raw bytes that objdump normally provides for clarity; also some of Go's setup code)
0000000000497640 <main.main>:
...
movq $0x37,(%rsp)
call 40a3e0 <runtime.convT64>
mov 0x8(%rsp),%rax
xorps %xmm0,%xmm0
movups %xmm0,0x40(%rsp)
lea 0xaa7e(%rip),%rcx # 4a2100 <type.*+0xa100>
mov %rcx,0x40(%rsp)
mov %rax,0x48(%rsp)
mov 0xb345d(%rip),%rax # 54aaf0 <os.Stdout>
lea 0x4290e(%rip),%rcx # 4d9fa8 <go.itab.*os.File,io.Writer>
mov %rcx,(%rsp)
mov %rax,0x8(%rsp)
lea 0x40(%rsp),%rax
mov %rax,0x10(%rsp)
movq $0x1,0x18(%rsp)
movq $0x1,0x20(%rsp)
nop
call 491140 <fmt.Fprintln>
...
Weird! This doesn't look like our code at all. Where's the call to our add function? In fact, movq $0x37,(%rsp) (move the value 0x37 to memory location pointed to by the stack pointer register) looks super suspicious. 22 + 33 = 55 which is 0x37 in hex. It looks like the Go compiler has optimised the code, working out the addition at compile time, eliminating most of our code in the process!
In order to study this further we need to tell the Go compiler to not inline the add function which can be done using a special comment to annotate the add function. add now looks like this:
//go:noinline
func add(i, j int) int {
return i + j
}
Compiling the code and running objdump again, the disassembly looks more as we might expect. Let's start with main() - I've broken up the disassembly into pieces and added commentary.
The main func begins with base pointer and stack pointer initialisation:
0000000000497660 <main.main>:
mov %fs:0xfffffffffffffff8,%rcx
cmp 0x10(%rcx),%rsp
jbe 497705 <main.main+0xa5>
sub $0x58,%rsp
mov %rbp,0x50(%rsp)
lea 0x50(%rsp),%rbp
followed by,
movq $0x16,(%rsp)
movq $0x21,0x8(%rsp)
Here we see the arguments to add being pushed onto the stack in preparation for the function call. 0x16 (22) is moved to where the stack pointer is pointing. 0x21 (33) is copied to 8 bytes after where the stack pointer is pointing (so earlier in the stack). The offset of 8 is important because we're dealing with 64-bit (8 byte) integers. An 8 byte offset means the 33 is placed on the stack directly after the 22.
call 4976e0 <main.add>
mov 0x10(%rsp),%rax
mov %rax,0x30(%rsp)
Here's where the add function actually gets called. When the call instruction is executed by the CPU, the current value of the instruction pointer is pushed to the stack and execution jumps to the add function. Once add returns, execution continues here where z (stack pointer + 0x30 as it turns out) is assigned to the returned value (stack pointer + 0x10). The AX register is used as temporary storage when moving the return value.
There's more code that follows in main to handle the call the fmt.Println but that's outside the scope of this article.
One thing I found interesting looking at this code is that the classic push instructions aren't being used to add values onto the stack. Values are placed onto the stack using mov. It turns out that this is for performance reasons. A mov generally requires fewer CPU cycles than a push.
We should also have a look at add:
0000000000497640 <main.add>:
mov 0x10(%rsp),%rax
mov 0x8(%rsp),%rcx
add %rcx,%rax
mov %rax,0x18(%rsp)
ret
The second argument (at SP + 0x10) is copied to the AX register, and the first argument (at SP + 0x08) is copied to the CX register. But hang on, weren't the arguments at SP and SP+0x10? They were but when the call instruction was executed, the instruction pointer was pushed to the stack which means the stack pointer had to be decremented to make room for it - this means the offsets to the arguments have to be adjusted to account for this.
The add instruction is easy enough to understand. Here CX and AX are added (with the result left in AX). The result is then pushed to the return location (SP + 0x18).
The ret (return) instruction grabs the return address off the stack and starts execution just after the call in main.
Phew! That's a lot of code for a simple program. Although it's useful to understand what's going on, be thankful that we don't have to write assembly language very often these days!
Examining Go 1.17's Output
Now let's take a look at the same program compiled with Go 1.17. The compilation and disassembly steps are similar to Go 1.16:
$ go build -o prog-117 ./main.go
$ objdump -d prog-117 > prog-117.asm
The main disassembly starts the same as under Go 1.16 but - as expected - differs in the call to add:
mov $0x16,%eax
mov $0x21,%ebx
xchg %ax,%ax
call 47e260 <main.add>
Instead of copying the function arguments onto the stack, they're copied into the AX and BX registers. This is the essence of register based calling.
The xchg %ax,%ax instruction is a bit more mysterious and I only have theories regarding what it's for. Email me if you know and I'll add the detail here.
As we've already seen earlier, the call instruction moves execution to the add function.
Now let's take a look at add:
000000000047e260 <main.add>:
add %rbx,%rax
ret
Well that's simple! Unlike the Go 1.16 version, there's no need to move arguments from the stack into registers in order to add them, and there's no need to move the result back to the stack. The function arguments are expected to be in the AX and BX registers, and the return value is expected to come back via AX. The ret instruction moves execution back to where call was executed, using the return address that call left on the stack.
With so much less work being done when handling function arguments and return values, it's starting to become clearer why register based calling might be faster.
Performance Comparison
So how much faster is register based calling? I created a simple Go benchmark program to check:
package main
import "testing"
//go:noinline
func add(i, j int) int {
return i + j
}
var result int
func BenchmarkIt(b *testing.B) {
x := 22
y := 33
var z int
for i := 0; i < b.N; i++ {
z = add(x, y)
}
result = z
}
Note the use of a variable outside of the benchmark function to ensure that the compiler won't optimise the assignment to z away.
The benchmark can be run like this:
go test bench_test.go -bench=.
On my somewhat long in the tooth laptop, the best result I could get under Go 1.16 was:
BenchmarkIt-4 512385438 2.292 ns/op
With Go 1.17:
BenchmarkIt-4 613585278 1.915 ns/op
That's a noticeable improvement - a 16% reduction in execution time for our example. Not bad, especially as the improvement comes for free for all Go programs just by using a newer version of the compiler.
Conclusion
I hope you found it interesting to explore some lower level details of software that we don't think about much these days and that you learned something along the way.
Many thanks to Ben Hoyt and Brian Thorne for their detailed reviews and input into this article.
from Hacker News https://ift.tt/30T1mWQ
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.