Summary: I decided to set up my own language translation server so the chatbot I created can understand more than just English.
DwayneBot
DwayneBot is a chatbot I’ve been building over the past few months. It connects to different kinds of chat rooms, listens to what’s being said, and responds to stuff. It works by scanning each message that’s sent to the room for a command it can respond to. Like with most chatbots, commands are words that start with some customizable character, which is usually “!”. So: !uptime, !commands, !random, !wiki, etc.
Sometimes they take arguments/options. You can ask the bot for a random number between 16 and 32 by saying !random 16 32. Or you can ask for a Wikipedia summary of He Who Remains with !wiki He Who Remains. I wrote a lot of commands to do a lot of different things.
The thing about these types of commands and arguments though is that they’re actually pretty limited. Since they’re just words with no delimiters or anything, there isn’t a lot of flexibility. Like if there are multiple options, the first one can only be one word or else the bot wouldn’t know which was which. And there’s no way to have multiple optional arguments.
So DwayneBot understands commands like those, but it’s also advanced enough to understand regular questions/statements too, so it can respond to things like:
- hey bot, how long have you been running?
- DwayneBot: how do you work?
- ok bot, pick a number from 1 to 10
- dwaynebot: search wikipedia for natural language processing
And even more complicated requests like:
- hey bot, get me the second gif for Dune
- dwaynebot: tell us the weather in 10 minutes
Enabling this meant I had to write some NLP (natural language processing) code so the bot could actually convert those complicated-ass requests into actions it can execute. At first I tried using a Go NLP library to make things easier, but things like tokenization and named-entity extraction weren’t actually helping me the way I thought they would.
Instead I settled on my own solution using lots of my own manual language/date parsing code (some of which I had already slowly written over the 1.5 years of building this website) and a huge list of regular expressions, which is just a way to easily (lol) search text for specific phrases/patterns.
So what this means is I designed the bot to compare every single message that it reads to a list of phrases. Each one of those phrases is mapped to an action the bot understands. For example, “how do you work” is a phrase that maps to the About action, just like !about does. And “pick a number from 1 to 10” maps to the Random Number action like !random 1 10 does.
This is very cool to me and has actually been working extremely well so far. But while it’s undeniably dope af, it’s still not good enough. Because I only understand English, the bot only understands English. Every regular expression pattern is in English. The thing is, I don’t even like English. I really don’t like that I don’t know any other languages, and so I don’t like that the bot doesn’t either.
One thing DwayneBot can do that I can’t though is automatically translate input before processing it. So building translation deep into its core became a high priority goal for me. I figured it wouldn’t be perfect of course, but it would be a good enough start.
Translation APIs
Luckily there are a lot of translation APIs out there that allow you to easily detect what language the given text is in and quickly do a translation. I wasn’t all that happy with my choices though. I came across a few categories of APIs:
The Tech Giants
Of course Google, Microsoft, and Amazon all have extensive APIs for “cognitive services”, including language translation. Google supports 109(!!) languages, Microsoft supports 90, and Amazon supports 71.
None of these companies are an option for a few reasons:
- They hold too much power over the AI, machine learning, and “cognitive” fields and I’m not interested in feeding them even more data than they’re already getting.
- I really have no desire to give any of them any more money than I have to. I don’t even like shopping on Amazon these days.
The RapidAPI Collection
So many of my web searches led to RapidAPI, which immediately made me distrust them. As far as I can tell, they just collect APIs from around the Internet (from API authors/providers who decide to sign up with them) and handle payment. Decent business, but of course like any company who would find themselves in that position, they clearly are trying to benefit as much as possible from being API gatekeepers and there’s something annoying about it to me.
Anyway, there were some in this group that seemed okay, even though of course they all support way fewer languages than the Giants. I decided not to use any APIs from RapidAPI pretty early on though so it didn’t matter.
The Other Ones
Then there are the ones that aren’t in the first two groups that looked pretty good. Generally even worse language support, but that’s to be expected considering the Giants suck up all money, talent, and resources from the industry.
Luckily around the time I was thinking about all of this, I happened to come across a project called LibreTranslate. It was especially interesting to me because it’s open source and is meant to be self-hosted.
Turns out, a self-hosted solution is perfect for what I’m trying to do.
Self-Hosted Translation API
DwayneBot, like this website (and like myself really), doesn’t have many dependencies. Most of the functionality comes from the server itself, so for the most part as long as Digital Ocean’s infrastructure is running, the website will be running. Everything that is external (like all the different APIs the server uses: OpenWeather, Spotify, Giphy, Steam, etc) is handled gracefully if unreachable, as you would expect from an extremely well designed system.
The base features of the bot (including all of the language processing) were written by me and have no dependencies. That’s how I want it. I don’t like the idea of introducing a core feature that’s entirely dependent on another service.
So I installed LibreTranslate here on the web server, which means I now have a perpetually free translation API under my control. It was pretty easy to set up too, even with me building the project from scratch for no reason (I just had to use pip install after fixing up my python installation and installing a couple of dependencies).
LibreTranslate/Argos Translate
Note: Before I get into this next part, I want to be clear about the details of this project. LibreTranslate is a project that provides an API (and does API management) using the Argos Translate project as a dependency. Argos Translate is the one that actually does the translations. I’ll mention both projects below, but for the most part you can think of them as the same thing.
The nice thing about Argos Translate is that it works by using language separate language “models”. Each model is the result of machine learning, and is basically a zip file that contains translation data for two languages. When you install LibreTranslate, you’re responsible for finding and installing models for the languages you’re interested in. There’s a default set, but the more you can find, the more languages your instance can translate to/from.
The default set contains: Arabic, Chinese, English, French, German, Hindi, Indonesian, Irish, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish, Turkish, and Vietnamese.
I’m trying to get even more. I want support for African languages. I want support for more than one Indian language. I know I’m not gonna catch up to the 109 languages Google supports, but I would love to have more than 17.
Another Note: I actually do want to put some time and resources into either creating or encouraging the creation of more Argos Translate models. The tech giants can’t be the only ones with support for languages from more marginalized people in the world.
Completing the Translate service
Right before I found LibreTranslate, I started to implement support for a third party translation API called DeepL. Because this translation plan started with multiple “providers” for translation – my own non-public LibreTranslate instance and DeepL – I designed my translation service (I’ll just call it Translate) to take text input for translation and decide on which provider to use. This way I can add other providers or remove DeepL if I need to. Ideally though I’ll just find more Argos Translate models and mostly use my own instance.
Right now, I designed Translate to only use DeepL when its enabled and certain conditions are met. Under any other circumstances, and as a fallback, it will use my LibreTranslate instance. So why even use DeepL at all?
- I heard DeepL was really good with certain (European) languages so I would like the bot to also be really good with those languages.
- It is nice to offset some of the resources on my server since I don’t know the full impact on it under load yet.
- I already started writing the integration before I installed LibreTranslate so… I just kept it there instead of deleting the code.
DwayneBot then uses this Translate service (which again, is making its own decisions about which provider to use) for:
- Auto-translate, which will (when enabled) translate a statement/question directed to the bot to English so it can be parsed.
- When directly asked to translate something (example: hey bot, translate English is a bad language to Japanese)
- When one of my favorite bot actions,
ExecTranslate, is used to have the bot parse a statement, execute any actions from it, and then translate all the output to the given language.
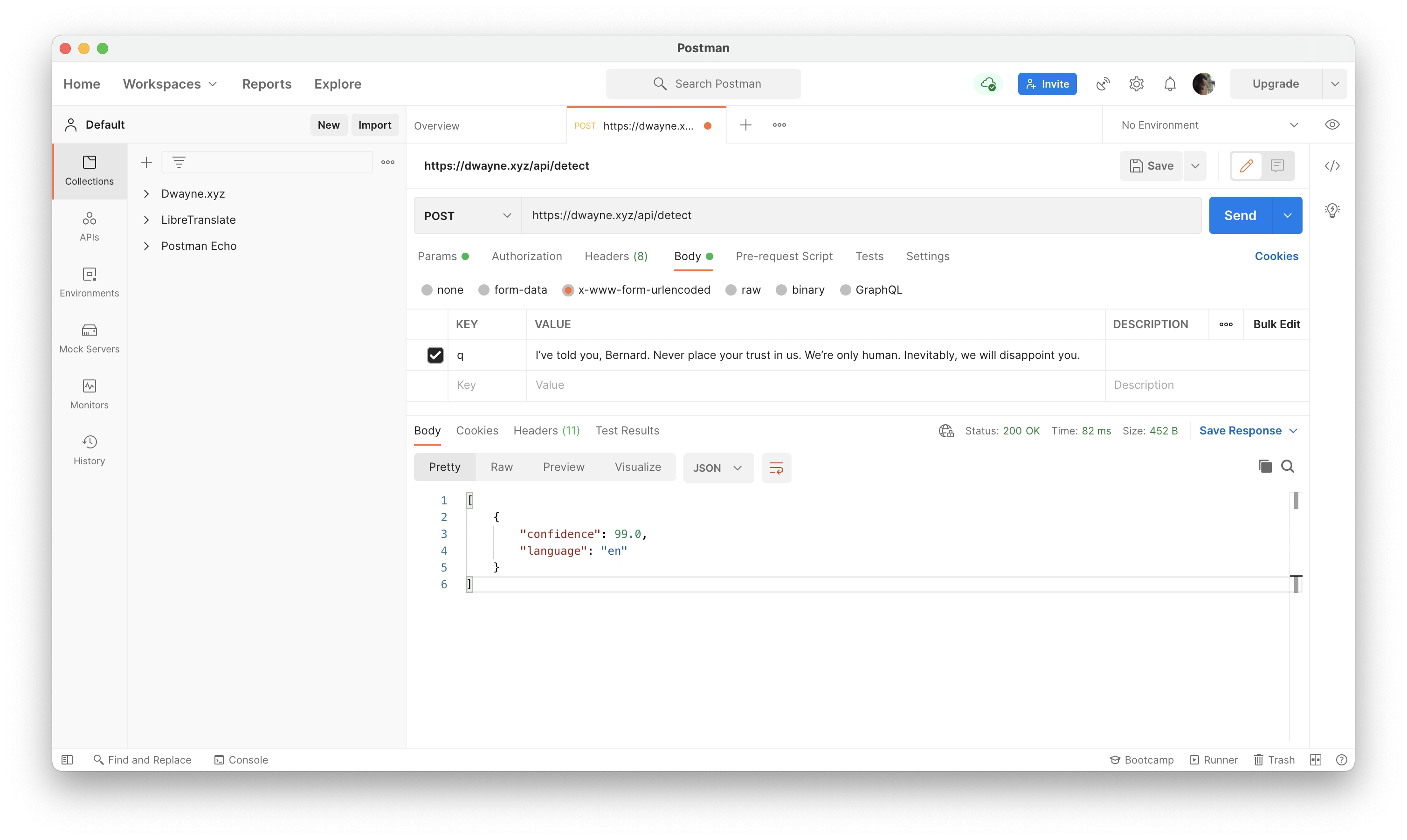
In order to test Translate, including how often it’s picking one provider over the other, and to keep an eye on the results over time, I added a page in the /utils section of the site where you can translate text just like with any of the other web services. I also ended up adding an admin page to view DeepL usage and either enable or disable it.
Server Resources
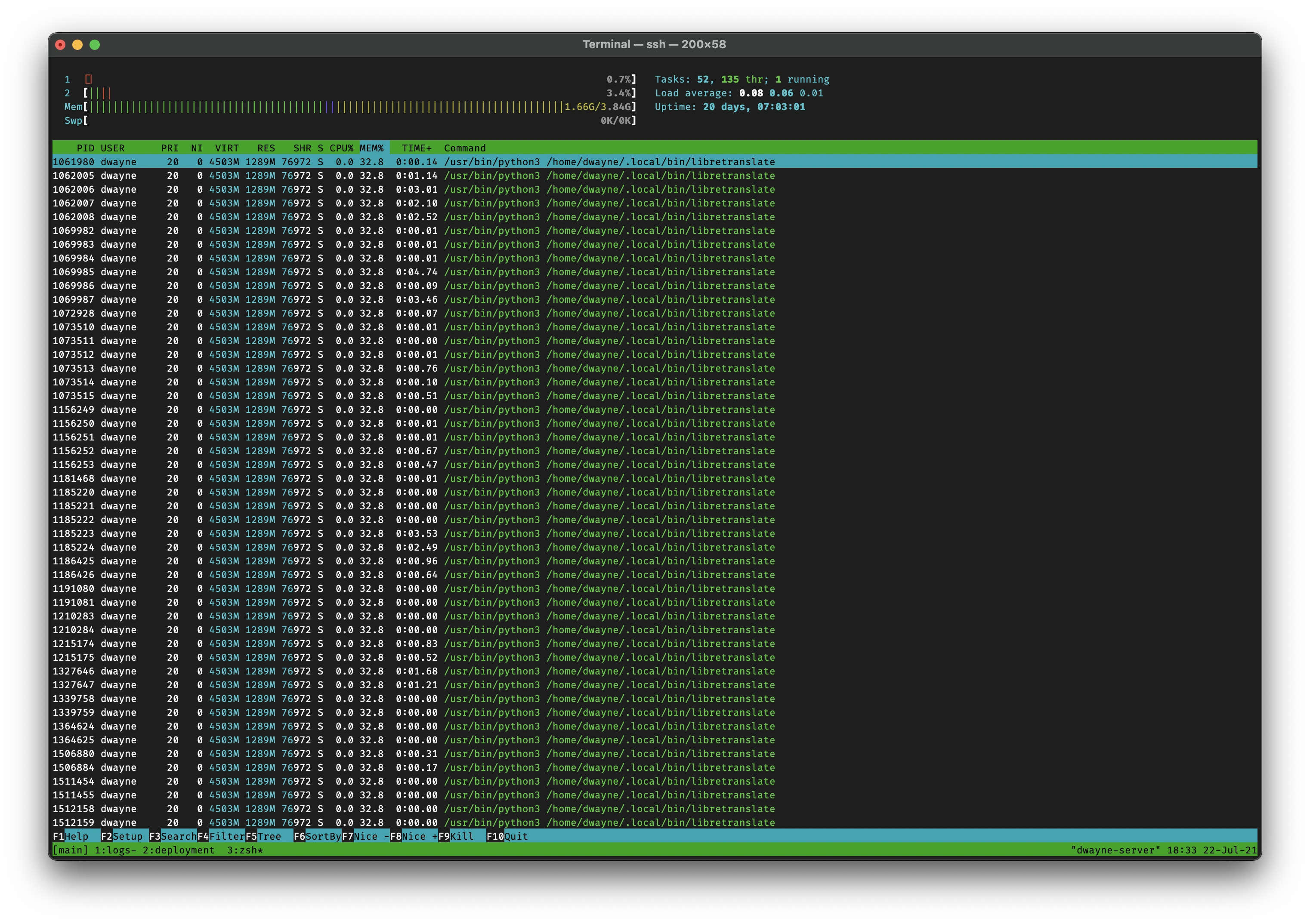
I was actually pretty nervous about how hard LibreTranslate might stress the server. I’ve only been using a single Digital Ocean droplet (and separate Postgres and Spaces instances) for everything I’ve been doing here. If this ends up really beating up the server and it starts affecting the website itself I’ll have to stop it and maybe consider renting a second server.
Luckily things seem reasonable so far!
Disk Usage - Downloading the default set of models took a while. I was worried the total size for the set would be huge, but it’s about 3.1 GBs total.
CPU - I haven’t measured it, but it doesn’t seem like it uses much CPU at all. I haven’t stress tested it yet though.
RAM - It does use a decent amount of RAM. 32.8% of my 4 GBs so far. Note: It’s taking a lot less RAM now after a server restart. I’m waiting to see how long it takes to climb back up again.
Future Plans
That’s everything I had planned for Translation so far. The three bot features I described earlier (auto-translate, direct translation with !translate, and full response translation) are already working well. DwayneBot will continue to evolve and do more advanced shit, some of which might really benefit from having native translation support.
The Translate service is also available to the rest of the website of course, so eventually I’ll add support for translating certain sections of the site and all the articles. For now though, I’m still working on testing and stabilizing (and writing about) other bot features. More to come.
from Hacker News https://ift.tt/3yj3rHf
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.