Amazon has released support for up to 10 GB memory and 6 vCPUs for your Lambda functions. In this article we will explore how these new memory configuration options can drive down costs and execution times for compatible workloads.
Let’s quickly review the Lambda pricing scheme. We’ll ignore the free tier. Lambda is billed at $0.0000166667 for every GB-second. A GB-second is the unit of measurement for 1 GB of memory running for 1 second. Lambdas are often very short lived, so let’s say a particular function has an average execution time of 100ms, and is executed 100 times every minute. That’s 10 seconds of execution time per minute, 14.400 seconds per day, and 432.000 seconds per 30 days. This function is configured to use 128 MB or RAM (1/8th of a GB), so you’re billed for 432.000 / 8 = 54.000 GB-seconds per month. At $0.0000166667 per GB-second, this function will cost a whopping $0.90 per month.
The only tunable performance configuration for Lambda is the amount of memory available to the function. The CPU performance scales with the memory configuration. Lambda functions used to always have 2 vCPU cores, regardless of memory. These cores would be throttled at certain memory configurations. The documentation states that at 1,769 MB, a function has the equivalent of one vCPU.
With the increased maximum memory of 10GB, up from 3008 MB (AWS News - AWS Blog), the number of CPUs has become more flexible. We ran some tests and found out that Lambda now has the following CPU tiers:
| Memory | vCPUs |
|---|---|
| 128 - 3008 MB | 2 |
| 3009 - 5307 MB | 3 |
| 5308 - 7076 MB | 4 |
| 7077 - 8845 MB | 5 |
| 8846+ MB | 6 |
This opens up a number of new price tuning options. If a workload supports multi-threading, for example, we can try to optimize the number of vCPUs to reduce execution time. A multi-threading function configured at 3009 MB might execute 1.5x as fast as a 3008 MB function, a 33.3% cost reduction! Let’s see if we can produce these results in real life benchmarks.
Running tests with ffmpeg
To test Lambda’s performance we compiled ffmpeg from source and packaged it together with a 100 MB sample video and a simple Python app. Because this package exceeds the maximum size for Lambda deployment packages, we used the new Lambda Container Image Support (AWS News - AWS Blog) to put ffmpeg and the video together in a container and create a Lambda function from that container. Our performance benchmark will consist of 100 iterations of a video format conversion. The exact command for our initial run of benchmarks is ffmpeg -i source.mkv -c:v libx264 -b:a 128k -threads 1 -y /tmp/target.mp4
As you can see, this command is hardcoded to use only one thread. This allows us to set a single-threaded baseline on various memory configurations. We ran 100 iterations on the key memory sizes in the table below. The values chosen are the top and bottom values for every CPU tier. 832 MB was the minimum required to successfully convert the video within 15 minutes.
Single thread results
| Memory | vCPUs | Threads | Average Execution Time | Cost for 100 Executions |
|---|---|---|---|---|
| 832 MB | 2 | 1 | 832308 ms (832.31 s) | $1.1271 |
| 1769 MB | 2 | 1 | 396342 ms (396.34 s) | $1.1412 |
| 3008 MB | 2 | 1 | 361768 ms (361.77 s) | $1.7712 |
| 3009 MB | 3 | 1 | 361907 ms (361.91 s) | $1.7724 |
| 5307 MB | 3 | 1 | 362551 ms (362.55 s) | $3.1316 |
| 5308 MB | 4 | 1 | 359439 ms (359.44 s) | $3.1053 |
| 7076 MB | 4 | 1 | 360534 ms (360.53 s) | $4.1523 |
| 7077 MB | 5 | 1 | 359426 ms (359.43 s) | $4.1401 |
| 8845 MB | 5 | 1 | 359287 ms (359.29 s) | $5.1724 |
| 8846 MB | 6 | 1 | 360957 ms (360.96 s) | $5.1970 |
| 10240 MB | 6 | 1 | 361495 ms (361.49 s) | $6.0249 |
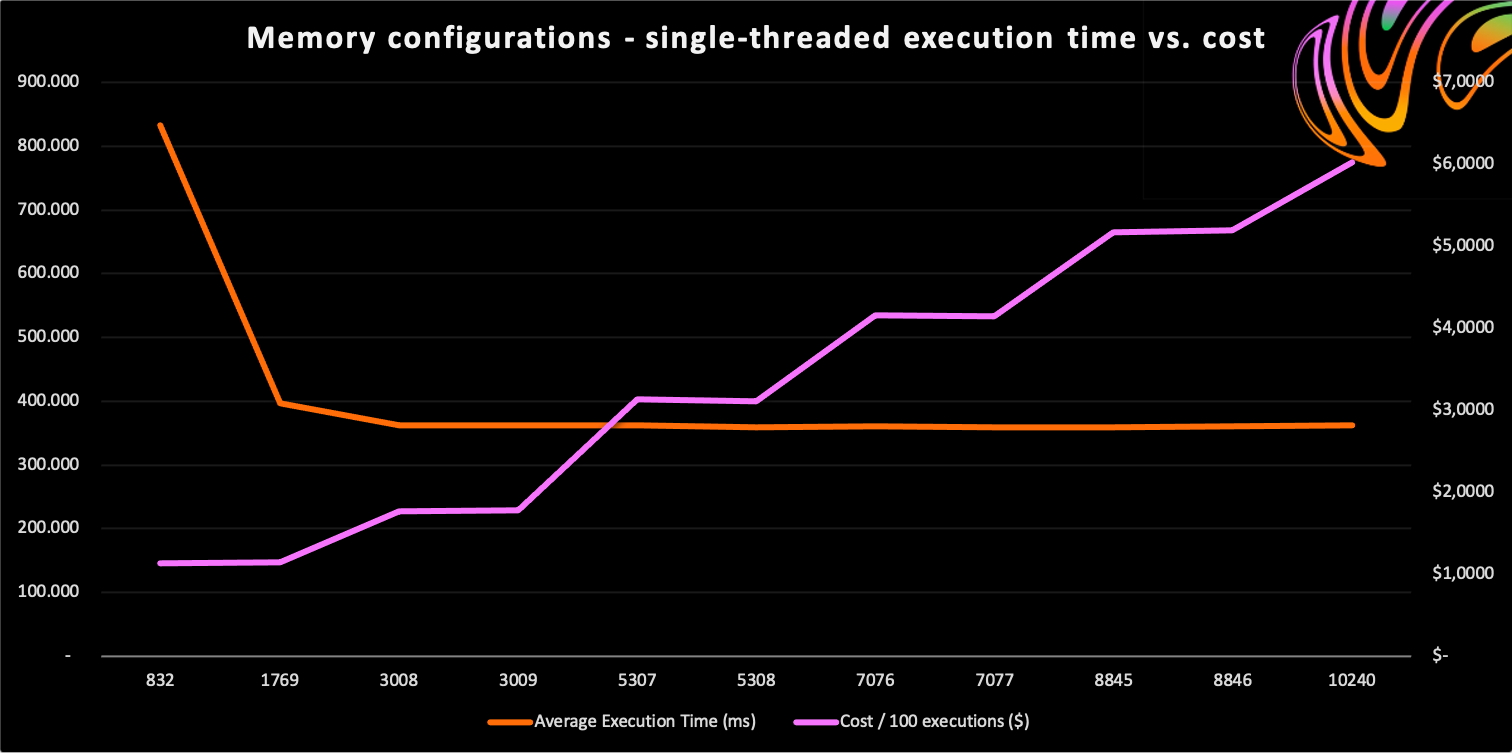
This data clearly shows that any memory configuration above 3008 MB does not improve single thread performance. Memory configurations up to 1769 MB are throttled, from 1769 MB to 3008 MB there are some minor performance increases, and from 3008 MB and up you’re using the full capacity of a single core, which means the average execution time plateaus. At the same time the costs for higher memory configurations are skyrocketing. Clearly, if you’re running single-threaded processes in Lambda you would do well to fit your Lambda’s memory closely to your function’s actual requirements.
Multi-threaded results
For our multi-threaded tests, we obtain the number of CPUs from /proc/cpuinfo and configure ffmpeg to use as many threads as there are cores. Let’s take a look at the results.
| Memory | vCPUs | Threads | Average Execution Time | Diff vs. Single-threaded | Cost for 100 Executions |
|---|---|---|---|---|---|
| 832 MB | 2 | 2 | 880404 ms (880.40 s) | +5.78% | $1.1922 |
| 1769 MB | 2 | 2 | 402968 ms (402.97 s) | +1.67% | $1.1602 |
| 3008 MB | 2 | 2 | 241733 ms (241.73 s) | -33.18% | $1.1835 |
| 3009 MB | 3 | 3 | 237562 ms (237.56 s) | -34.36% | $1.1635 |
| 5307 MB | 3 | 3 | 168755 ms (168.76 s) | -53.45% | $1.4577 |
| 5308 MB | 4 | 4 | 150779 ms (150.78 s) | -58.05% | $1.3026 |
| 7076 MB | 4 | 4 | 142042 ms (142.04 s) | -60.60% | $1.6359 |
| 7077 MB | 5 | 5 | 104318 ms (104.32 s) | -70.98% | $1.2016 |
| 8845 MB | 5 | 5 | 95304 ms (95.30 s) | -73.47% | $1.3720 |
| 8846 MB | 6 | 6 | 90039 ms (90.04 s) | -75.06% | $1.2964 |
| 10240 MB | 6 | 6 | 87455 ms (87.46 s) | -75.81% | $1.4576 |
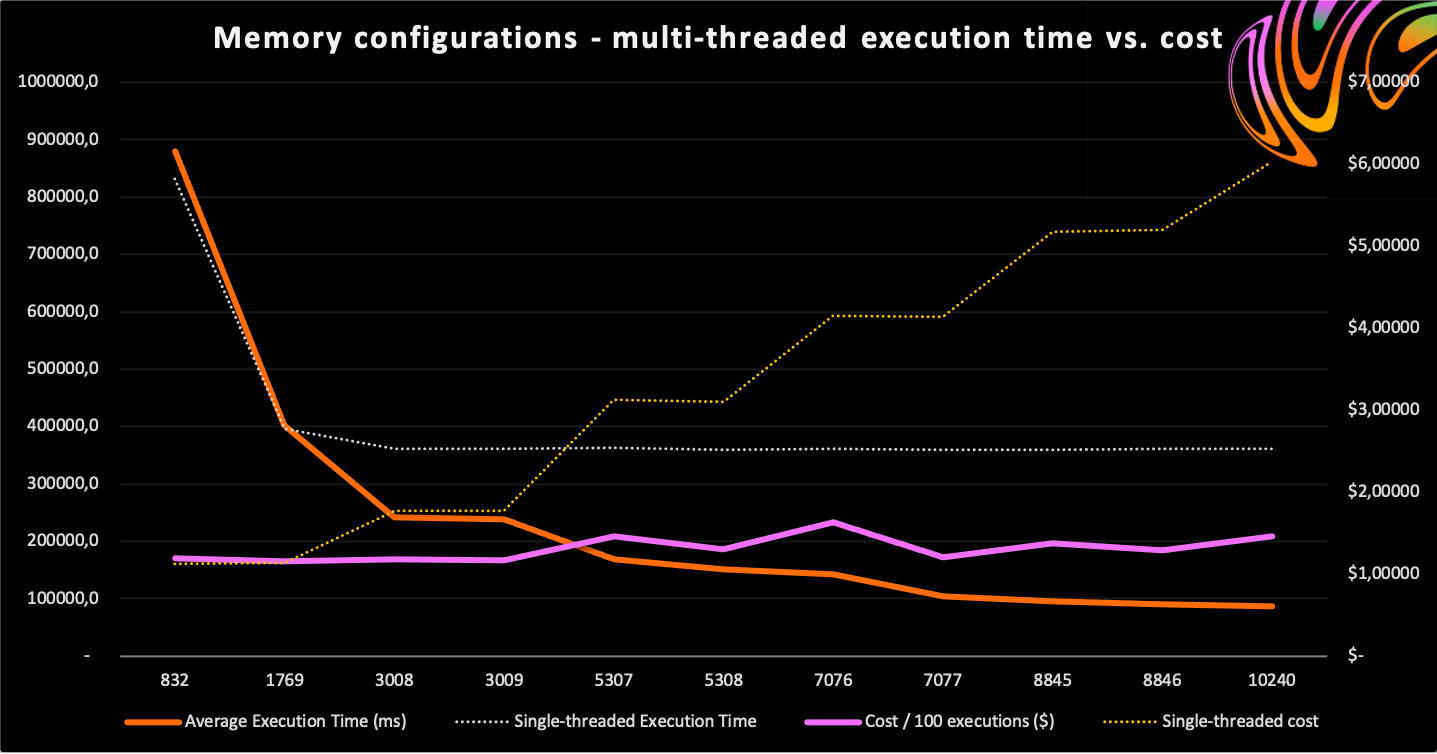
What jumps out immediately is that at 832 MB using two threads is actually slower than the single-threaded benchmark. This likely relates to the CPU throttling applied to Lambda functions below 1769 MB: two threads competing for the same limited resources are slower than a single thread having those resources to itself.
At 1769 MB the multi-threaded measurement is almost exactly equal to the single-threaded result. This makes sense, since the documentation states that at 1769 MB, a function has the equivalent of one vCPU. At this level contestation is apparently no longer an issue.
At 3008 MB, the old maximum memory configuration, we start to benefit from using multiple cores. But it starts to get interesting at exactly 1 MB higher, at 3009 MB. This is the first time we get to use more than two cores, and we would expect an immediate performance bump. However, the results at three cores and 3009 MB are only 1.73% better than at two cores and 3008 MB. Apparently, the three cores at 3009 MB do not offer 1.5x the performance of the two cores at 3008 MB, and some throttling is taking place. This is corroborated by the benchmark at 5307 MB: even though this configuration has the same amount of cores, its performance is 28.96% higher than at 3009 MB. This means that AWS is dynamically limiting the amount of processing power available to the function, based on its memory configuration.
Next, at 5308 MB, we have our first four-core benchmark. Here we see that the fourth core adds a significant improvement. Although we added only 0.0188% of memory, performance jumped by 10.65%. The other four-core measurement at 7076 MB yields further improvements, but not enough to offset the additional cost.
Then at 7077 MB, the first five-core benchmark, we see another BIG jump. Again, we only added a single MB of memory, but the fifth core increased performance by an incredible 26.56%. Increasing memory to 8845 MB adds another improvement of 8.64%, but like in the four-core block, this doesn’t offset the additional cost.
At 8846 MB the additional MB and 6th core yields a 5.52% performance boost, and the maximum configuration of 10240 MB is 2.87% faster than the 8846 MB setting.
Understanding these results
The single-threaded benchmarks showed that a single core maxes out at relatively low memory configurations. The same logic doesn’t apply to multi-threaded solutions: every tier increased multi-threaded performance. Adding an additional core sometimes adds a big performance gain, and sometimes it hardly adds value.
This leads me to conclude that AWS applies a sort of dynamic capacity ceiling to Lambda functions. For example, this ceiling might be set at 0.5 at 832 MB, which means you can at max use half a core. It’s set to 1.0 at 1769 MB, which means we can use one full core. At 3008 it seems to be set to 1.6667. A full list of ceiling values can be found in the table below:
| Memory | vCPUs | CPU Ceiling |
|---|---|---|
| 832 MB | 2 | 0.50 |
| 1769 MB | 2 | 1.00 |
| 3008 MB | 2 | 1.67 |
| 3009 MB | 3 | 1.70 |
| 5307 MB | 3 | 2.39 |
| 5308 MB | 4 | 2.67 |
| 7076 MB | 4 | 2.84 |
| 7077 MB | 5 | 3.86 |
| 8845 MB | 5 | 4.23 |
| 8846 MB | 6 | 4.48 |
| 10240 MB | 6 | 4.72 |
This explains how single-threaded functions can completely utilize a single core, but multi-threaded applications can’t do the same on multiple cores.
Please note that these values are for my specific video conversion benchmark. This benchmark might not be able to max out all the cores available to it. Other benchmarks might be able to use multiple cores more efficiently and produce different results.
The core take-away is that this benchmark has run exactly the same process under different memory configurations, and consistently produces better results for higher memory configurations in the same CPU tier.
The second finding is that adding an additional core always yields a performance benefit for multi-threaded processes. Some cores (the third and sixth) provide smaller benefits than others (the fourth and fifth). If your function is configured just below one of these thresholds, slightly increasing the value might result in big gains.
Determining the ideal price point
Multi-threaded Lambda functions complete faster at higher memory settings, leading to lower costs. In general, the lower execution time offsets a big chunk of the higher memory costs. This is especially visible at 1769, 3009 and 7077 MB: the first configuration costs $1.1602 for 100 executions. The second configuration completes its operation 41.05% faster, at a 0.28% price increase ($1.1635). The 7077 MB setting completes 74.11% faster than the 1769 MB variant, at a 3.57% price increase ($1.2016).
Deciding which price point is best for your workload depends on your requirements: if it’s purely cost-driven, 1769 MB or 3009 MB might be a good starting point. If it’s performance driven, do run some tests at 5308, 7077 and 8846 MB. These memory configurations might perform significantly better at a marginally higher cost.
Conclusion
You might have hoped that the new high-memory Lambda functions would also improve single-threaded performance, but alas - the functions seem to run on exactly the same hardware as their lowly 3008 MB siblings. However, the higher Lambda tiers do include three, four, five and six CPU cores. In multi-threaded processes, a single MB difference in your memory configuration might have a big impact on your function’s execution time. This complicates finding the ideal price point - it’s no longer simply a case of matching the memory configuration to your function’s memory needs. However, investing some time in trying out different values might lead to big savings.
Additionally you might be able to achieve big gains in performance and cost if you’re able to rewrite your single-threaded Lambdas to use multiple threads.
This article is part of a series published around re:Invent 2020. If you would like to read more about re:Invent 2020, check out my other posts:
I share posts like these and smaller news articles on Twitter, follow me there for regular updates! If you have questions or remarks, or would just like to get in touch, you can also find me on LinkedIn.
from Hacker News https://ift.tt/2JVzV68
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.