Dgraph Labs has been a user of the Go language since our inception in 2015. Five years and 200K lines of Go code later, we're happy to report that we are still convinced Go was and remains the right choice. Our excitement for Go has gone beyond building systems, and has led us to even write scripts in Go that would typically be written in Bash or Python. We find that using Go has helped us build a codebase that is clean, readable, maintainable and - most importantly - efficient and concurrent.
However, there's one area of concern that we have had since the early days: memory management. We have nothing against the Go garbage collector, but while it offers a convenience to developers, it has the same issue that other memory garbage collectors do: it simply cannot compete with the efficiency of manual memory management.
When you manage memory manually, the memory usage is lower, predictable and allows bursts of memory allocation to not cause crazy spikes in memory usage. For Dgraph using Go memory, all of those have been a problem. In fact, Dgraph running out of memory is a very common complaint we hear from our users.
Languages like Rust have been gaining ground partly because it allows safe manual memory management. We can completely empathize with that.
In our experience, doing manual memory allocation and chasing potential memory leaks takes less effort than trying to optimize memory usage in a language with garbage collection. Manual memory management is well worth the trouble when building database systems that are capable of virtually unlimited scalability.
Our love of Go and our need to avoid Go GC led us to find novel ways to do manual memory management in Go. Of course, most Go users will never need to do manual memory management; and we would recommend against it unless you need it. And when you do need it, you'll know.
In this post, I'll share what we have learned at Dgraph Labs from our exploration of manual memory management, and explain how we manually manage memory in Go.
Memory creation via Cgo
The inspiration came from the Cgo wiki section about Turning C arrays into Go slices. We could use malloc to allocate memory in C and use unsafe to pass it over to Go, without any interference from Go GC.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
However, the above comes with a caveat, as noted in golang.org/cmd/cgo.
Note: the current implementation has a bug. While Go code is permitted to write nil or a C pointer (but not a Go pointer) to C memory, the current implementation may sometimes cause a runtime error if the contents of the C memory appear to be a Go pointer. Therefore, avoid passing uninitialized C memory to Go code if the Go code is going to store pointer values in it. Zero out the memory in C before passing it to Go.
So, instead of using malloc, we use its slightly more expensive sibling, calloc. calloc works the same way as malloc, except it zeroes out the memory before returning it to the caller.
We started out by just implementing basic Calloc and Free functions, which allocate and de-allocate byte slices for Go via Cgo. To test these functions, we developed and ran a continuous memory usage test. This test endlessly repeated an allocate/de-allocate cycle in which it first allocated various randomly-sized memory chunks until it had allocated 16GB of memory, and then freed these chunks until just 1GB of memory was left allocated.
The C equivalent of this program behaved as expected. We would see the RSS memory in our htop increasing to 16GB, then going down to 1GB, increasing back to 16GB, and so on. However, the Go program using Calloc and Free would use progressively more memory after each cycle (see chart below).
We attributed this behavior to memory fragmentation due to lack of thread awareness in the default C.calloc calls. After some help from the Go #dark-arts Slack channel (particular thanks to Kale Blankenship), we decided to give jemalloc a try.
jemalloc
jemalloc is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support. jemalloc first came into use as the FreeBSD libc allocator in 2005, and since then it has found its way into numerous applications that rely on its predictable behavior. — http://jemalloc.net
We switched our APIs over to use jemalloc for calloc and free calls. And it performed beautifully: jemalloc supports threads natively with little memory fragmentation. The allocation-deallocation cycles from our memory usage monitoring test were circulating between expected limits, ignoring a small overhead required to run the test.
Just to ensure that we're using jemalloc and avoid a name clash, we added a je_ prefix during installation, so our APIs are now calling je_calloc and je_free, instead of calloc and free.
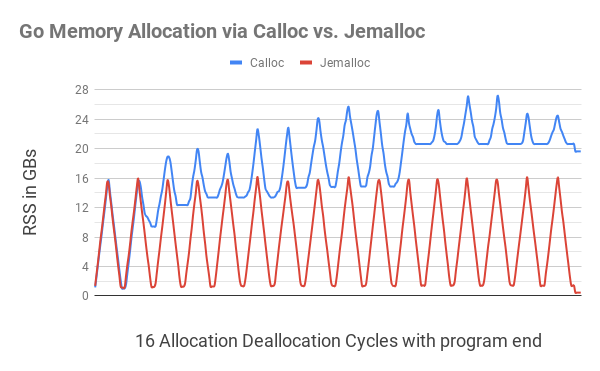
In the above chart, allocating Go memory via C.calloc resulted in major memory fragmentation, causing the program to hog on to 20GBs of memory by the 11th cycle. Equivalent code with jemalloc had no noticeable fragmentation, going down close to 1GB on every cycle.
At the end of the program (small dips on far right), after all the allocated memory was released, C.calloc program resulted in still hogging just under 20GB of memory, while jemalloc showed 400MB of memory usage.
To install jemalloc, download it from here, then run the following commands:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto'
make
sudo make install
The overall Calloc code looks something like this:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw is like panic, except it guarantees the process will be
// terminated. The call below is exactly what the Go runtime invokes when
// it cannot allocate memory.
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// Interpret the C pointer as a pointer to a Go array, then slice.
return (*[MaxArrayLen]byte)(uptr)[:n:n]
We made this code part of Ristretto‘s z package, so both Dgraph and Badger can use it. To allow our code to switch to using jemalloc to allocate the byte slices, we added a build tag jemalloc. To further simplify our deployments, we made the jemalloc library be statically linked in any resulting Go binary by setting the right LDFLAGS.
Laying out Go structs on byte slices
Now that we have a way to allocate and free a byte slice, the next step is to use it to layout a Go struct. We can start with a basic one (full code).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
In the code above, we laid out a Go struct on C allocated memory using newNode. We created a corresponding freeNode function, which can free up the memory once we were done with the struct. The Go struct has the basic data type int and a pointer to the next node struct, all of which were set and accessed in the program. We allocated 2M node objects and created a linked list out of them to demonstrate the proper functioning of jemalloc.
With default Go memory, we see 31 MiB of heap allocated for the linked list with 2M objects, but nothing allocated via jemalloc.
$ go run .
Allocated memory: 0 Objects: 2000001
node: 0
...
node: 2000000
After freeing. Allocated memory: 0
HeapAlloc: 31 MiB
Using the jemalloc build tag, we see 30 MiB of memory allocated via jemalloc, which goes down to zero after freeing the linked list. The Go heap allocation is only a tiny 399 KiB, which probably comes from the overhead of running the program.
$ go run -tags=jemalloc .
Allocated memory: 30 MiB Objects: 2000001
node: 0
...
node: 2000000
After freeing. Allocated memory: 0
HeapAlloc: 399 KiB
Amortizing the cost of Calloc with Allocator
The above code works great to avoid allocating memory via Go. But, it comes at a cost: lower performance. Running both the instances with time, we see that without jemalloc, the program ran in 1.15s. With jemalloc, it ran ~5x slower at 5.29s.
$ time go run .
go run . 1.15s user 0.25s system 162% cpu 0.861 total
$ time go run -tags=jemalloc .
go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
We attribute the slower performance to the fact that Cgo calls were made each time that memory was allocated, and each Cgo call comes with some overhead. To deal with this, we wrote an Allocator library in ristretto/z package. This library allocates bigger chunks of memory in one call, which can then be used to allocate many small objects, avoiding expensive Cgo calls.
Allocator starts with a buffer and when exhausted, creates a new buffer of twice the size. It maintains an internal list of all the allocated buffers. Finally, when the user is done with the data, they can call Release to free up all these buffers in one go. Note that Allocator does not do any memory movement. This helps ensure that any struct pointers we have stay valid.
While this might look a bit like the slab-style memory management that tcmalloc / jemalloc use, this is a lot simpler. Once allocated, you can not free up just one struct. You can only free up all of the memory used by Allocator.
What Allocator does well is to layout millions of structs for cheap and free them when done, without involving the Go heap. The same program shown above, when run with a new allocator build tag, runs even faster than the Go memory version.
$ time go run -tags="jemalloc,allocator" .
go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
Starting in Go 1.14, the -race flag turns on memory alignment checks for structs. Allocator has an AllocateAligned method which returns memory starting with the right pointer alignment to pass those checks. Depending upon the size of the struct, this could result in some memory waste but makes CPU instructions more efficient due to correct word boundaries.
We faced another memory management problem: Sometimes memory allocation happens at a very different place from deallocation. The only communication between these two places might be the structs allocated with no way to pass down the actual Allocator object. To deal with this, we assign a unique ID to each Allocator object, which the objects store in a uint64 reference. Each new Allocator object is stored on a global map against its reference. Allocator objects can then be recalled using this reference and released when the data is no longer required.
Reference Wisely
Do NOT reference Go allocated memory from manually allocated memory.
When allocating a struct manually, as shown above, it is important to ensure that there's no reference within the struct to Go-allocated memory. Consider a slight modification to the struct above:
type node struct {
val int
next *node
buf []byte
}
Let's use the root := newNode(val) func defined above to allocate a node manually. If, however, we then set root.next = &node{val: val}, which allocates all the other nodes in the linked list via Go memory, we are bound to get the following segmentation fault:
$ go run -race -tags="jemalloc" .
Allocated memory: 16 B Objects: 2000001
unexpected fault address 0x1cccb0
fatal error: fault
[signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
The memory allocated by Go gets garbage collected because no valid Go struct is pointing to it. Only C-allocated memory is referencing it, and the Go heap does not have any reference to it, resulting in the above fault. So, if you create a struct and manually allocate memory to it, it's important to ensure that all the recursively accessible fields are allocated manually as well.
For example, if the above struct was using a byte slice, we allocate that byte slice using Allocator as well to avoid mixing Go memory with C memory.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // Allocate 16 bytes
rand.Read(n.buf)
Dealing with GBs of allocations
Allocator is great for manually allocating millions of structs. However, we have use cases where we need to create billions of small objects and sort them. The way one would do that in Go, even with Allocator, looks something like this:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// nodes are now sorted in increasing order of val.
All these 1B nodes are manually allocated on the Allocator, which gets expensive. We also need to pay the cost of the slice in Go, which at 8GB of memory (8 bytes per node pointer, 1B entries) is itself quite expensive.
To deal with these kinds of use cases, we built z.Buffer, which can be memory mapped on a file to allow Linux to page memory in and out as required by the system. It implements io.Writer and replaces our reliance on bytes.Buffer.
More importantly, z.Buffer provides a new way to allocate smaller slices of data. With a call to SliceAllocate(n), z.Buffer would write the length of the slice being allocated (n) followed by allocating the slice. This allows z.Buffer to understand slice boundaries and iterate over them correctly with SliceIterate.
Sorting variable-length data
For sorting, we initially tried to get slice offsets from z.Buffer, access the slices to compare, but sort only the offsets. Given an offset, z.Buffer can read the offset, find the length of the slice and return that slice. So this system allowed us to access the slices in sorted order, without incurring any memory movements. While novel, that mechanism put a lot of pressure on memory, because we were still paying the 8GB memory penalty just to bring those offsets into Go memory.
One crucial limitation we had was that slices were not of the same size. Moreover, we could only access these slices in sequential order, not in reverse or random order, without calculating and storing the offsets in advance. Most in-place sort algorithms assume that values are of the same size , can be randomly accessed and can be readily swapped. Go's sort.Slice works the same way, and hence wasn't a good fit for z.Buffer.
With these limitations, we found the merge sort algorithm to be the most suitable for this job. With merge sort, we can operate on the buffer in sequential order, taking only an extra half the memory hit over the size of the buffer. This not only turned out to be cheaper than bringing offsets into memory, but it was a lot more predictable in terms of memory usage overhead as well (roughly half the buffer size). Even better, the overhead required to run merge sort is itself memory-mapped.
Merge sort also had one very positive effect. With offset based sorting, we had to keep the offsets in memory while iterating over and processing the buffer, which put even more pressure on memory. With merge sort, the extra memory needed is released by the time iteration starts, which means more memory is available for buffer processing.
z.Buffer also supports allocating memory via Calloc, and automatically memory mapping it once it exceeds a certain user-specified limit. This makes it work really well across all sizes of data.
buffer := z.NewBuffer(256<<20) // Start with 256MB via Calloc.
buffer.AutoMmapAfter(1<<30) // Automatically mmap it after it becomes 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// Iterate over nodes in increasing order of val.
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Catching Memory Leaks
All of this discussion would not be complete without touching on memory leaks. Now that we are using manual memory allocation, there are bound to be memory leaks where we forgot to deallocate memory. How do we catch those?
One simple thing we did early on was to have an atomic counter track the number of bytes allocated via these calls, so we can quickly know how much memory we have manually allocated in the program via z.NumAllocBytes(). If by the end of our memory test we still had any memory left, this indicated a leak.
When we did find a leak, we initially tried to use the jemalloc memory profiler. But, we soon realized that it isn't helpful. It doesn't see the entire call stack due to the Cgo boundary. All that the profiler sees are allocations and de-allocations coming from the same z.Calloc and z.Free calls.
Thanks to the Go runtime, we were able to quickly build a simple system to capture the callers into z.Calloc and match them against z.Free calls. This system requires mutex locks, so we chose not to enable it by default. Instead, we use a leak build flag to turn on leak debug messages for our dev builds. This automatically detects leaks, and prints out the places where any leaks occur.
// If leak detection is enabled.
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// Induced leak to demonstrate leak capture. The first number shows
// the size of allocation, followed by the function and the line
// number where the allocation was made.
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Conclusion
With these techniques, we get the best of both worlds: We can do manual memory allocation in critical, memory-bound code paths. At the same time, we can get the benefits of automatic garbage collection in non-critical code paths. Even if you are not comfortable using Cgo or jemalloc, you could apply these techniques on bigger chunks of Go memory, with similar impact.
All of the libraries mentioned above are available under Apache 2.0 license in the Ristretto/z package. The memtest and demo code is located in contrib folder.
Both Badger and Dgraph (particularly Badger) have already gained immensely from using these libraries. We can now process terabytes of data with limited memory usage – in line with what you'd expect from a C++ program. We are further identifying areas where we put pressure on Go memory, and relieving it by switching to manual memory management where that makes sense.
Dgraph v20.11 (T'Challa) release will be the first one to include all of these memory management features. Our goal is to ensure that Dgraph never needs more than 32 GB of physical RAM to run any kind of workload. And using z.Calloc, z.Free, z.Allocator and z.Buffer helps us achieve this goal with Go.
from Hacker News https://ift.tt/389ggtn
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.