There’s a proposal to add Software Transactional Memory, or STM, to the Ruby programming language. This is part of a wider effort to add better support for concurrency and parallelism in Ruby, and in particular the idea of ractors. A concept has been proposed and implemented by Koichi Sasada.
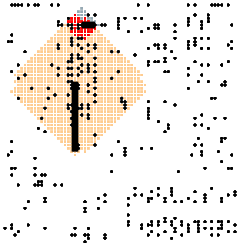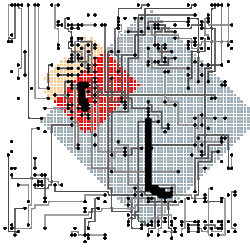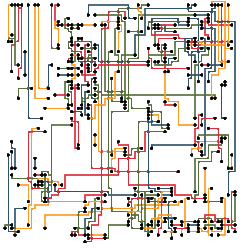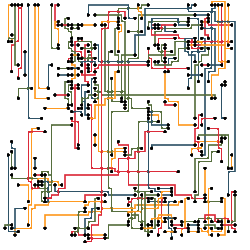
This article gives some context on what STM is, how you use it, and why you might want to use it. We’ll show an application which is well-suited to STM and we’ll use this to talk about the benefits, issues, and some open questions.
We’ll finish by setting a challenge for STM in Ruby.
I wrote the first half of my PhD on STM, and the second half on Ruby, so I’ve got quite a bit of experience with both and the idea of their combination is very interesting to me.
Why might we want an STM?
Let’s say we’re a bank managing many bank accounts. Each account has a total. We get a never-ending stream of requests to move a sum of money m from an account a to account b.
loop do
a, b, m = get_next_transfer
accounts[a] -= m
accounts[b] += m
end
Something not everyone may know about Ruby is that x += y is equivalent to writing t = x; x = t + y. We’ll write that out in full to make that clear to ourselves.
loop do
a, b, m = get_next_transfer
a_balance = accounts[a]
accounts[a] = a_balance - m
b_balance = accounts[b]
accounts[b] = b_balance + m
end
We’ve got a lot of transfers to run through, so we’ll have multiple threads processing these transfers.
n.times do
Thread.new
loop do
a, b, m = get_next_transfer
a_balance = accounts[a]
accounts[a] = a_balance - m
b_balance = accounts[b]
accounts[b] = b_balance + m
end
end
end
We’ve got a few problems here now. With all these threads running at the same time, what happens if two threads are putting money into your account concurrently?
accounts[a] = 100
# thread 1 # thread 2
balance = accounts[a]
# balance = 100
balance = accounts[a]
# balance = 100
accounts[a] = balance + 10
# accounts[a] = 110
accounts[a] = balance + 10
# accounts[a] = 110
The two transfers have run, but your balance is 110. The other 10 has been lost - this is called a lost update, meaning it’s as if the update was never made.
Also consider what happens if the thread crashes after taking money from a but before putting it into b? The transfer would be applied partially and again we’d lose money.
We need to use some kind of synchronization on our accounts. Ruby has mutual exclusion locks or mutexes, so we can try using those.
n.times do
Thread.new
loop do
a, b, m = get_next_transfer
locks[a].synchronize do
locks[b].synchronize do
accounts[a] -= m
accounts[b] += m
end
end
end
end
end
Does this work? What if we process a transfer from account 1001 to account 1002 on one thread at the same time as processing a transfer from account 1002 to 1001, so the other way around, at the same time?
The first thread will try to lock 1001 and then 1002. The second thread will try to lock 1002 and then 1001. If the first thread gets as far as locking 1001, and the second as far as locking 1002, then both will be waiting for the opposite lock and will never release the lock they already have. We will be in deadlock.
If we always acquired locks in the same order, by collecting them up first and sorting them, we could fix this.
n.times do
Thread.new
loop do
a, b, m = get_next_transfer
x, y = [a, b].sort
locks[x].synchronize do
locks[y].synchronize do
accounts[a] -= m
accounts[b] += m
end
end
end
end
end
Now in both transfers account 1001 is locked first and 1002 is locked second. That will work.
We have to make up a somewhat artificial requirement to explain the next issue, but consider if for some good reason we wanted to transfer to one account if we had a lot of money, and a different account if we only had a little money. Maybe if we’re rich this month we donate to charity, otherwise we unfortunately need to save for ourselves.
if account balance > 1000
transfer 10 to charity
else
transfer 10 to savings
end
We’ll talk about accounts a, b, and c, now, and a threshold of money t.
n.times do
Thread.new
loop do
a, b, c, t, m = get_next_transfer
x, y, z = [a, b, c].sort
locks[x].synchronize do
locks[y].synchronize do
locks[z].synchronize do
if accounts[a] > t
accounts[a] -= m
accounts[b] += m
else
accounts[a] -= m
accounts[c] += m
end
end
end
end
end
end
end
It’s starting to get very complicated. And this locks more than it needs to - it locks both b and c but then only uses one of them. If you use b in the end, ideally another thread could be serving a transfer to c at the same time, but you’ve locked it and it can’t. Imagine if instead of two potential accounts it was thousands and you had to lock them all. Imagine if you couldn’t work out at all which account you’d be transferring to until you started the transfer - then you’d never be able to process two transfers at the same time.
At this point as well we’re likely to start to make errors trying to do all this locking and ordering of locks and things.
Stepping back and taking it all in, we can draw up some requirements for what we need.
- atomicity - that all writes in the transfer are applied or none are applied
- consistency - meaning that our data structures are always valid - the total sum of money never changes
- isolation - meaning one transfer does not interfere with another
- durability - meaning that when applied the transfer is available to all subsequent transactions
Ideally a library or the language could do this all for us. We’d like to be able to write almost what we originally wrote, but with just an annotation to make the code inside a block atomic, consistent, isolated, and the result durable.
n.times do
Thread.new
loop do
a, b, m = get_next_transfer
atomically do
accounts[a] -= m
accounts[b] += m
end
end
end
end
This is what a transactional memory can let us do. It will automatically monitor what you read and write inside the atomically block, which is a transaction, and will make sure it is either applied fully or not, that the balance of the whole system is always consistent, that transactions do not see the result of each other partially applied, and that writes appear and stay.
It may be implemented using the code we eventually arrived at ourselves, or it could do something else instead. In practice how it is often implemented is that reads and writes are stored in a log, then at the end the transaction works out if anyone else has written locations that you’ve read. If they have then the values you read are no longer valid, so your transaction conflicts with another, is aborted and retries, reading the locations again. When it eventually does not conflict with any other transactions it is committed and succeeds. This means you don’t need to lock everything up-front, which means you avoid the problem of what happens if you may potentially need every account. Locking everything up-front is called pessimistic locking. We’re moving to optimistic locking
The proposed STM
Koichi’s proposed STM for Ruby, in combination with his proposed ractors (similar to actors) would look like this.
accounts = 9999.times.map { Thread::TVar.new(100) }
n.times do
Ractor.new *accounts do |*accounts|
loop do
a, b, m = get_next_transfer
Thread.atomically do
accounts[a].value -= m
accounts[b].value += m
end
end
end
end
He’s using a Ractor but you can think of it as a thread for the purposes of this article. Instead of an array of account balances, we now have an array of TVar objects that contain values. A TVar is a transactional variable. Only these variables are transactional - not any other Ruby value you read or write. His design requires that the TVar objects you’re going to use are passed into the Ractor, due to rules about sharing that aren’t relevant for this article.
This looks good, doesn’t it!
A more complex application
Let’s consider a larger application, in order to illustrate further and to talk about some issues and open questions. The code is available on GitHub.
Let’s say it’s our job to lay out the wires on a circuit board. We get a board with pads (connections to components mounted on the board) and a list of routes that we need to draw between these pads. There are a great many pads and routes, there isn’t much space on the tiny board, and another catch is that it’s very expensive to have wires crossing each other. Let’s say it’s exponentially more expensive for more deeply stacked wires.

In this minimal example we we can see two routes, and how they have to cross each other.

This example is a processor module and shows what kind of scale we might want to be working at. This board has many longer routes which are more likely to conflict.

This example is a memory module. It has many shorter routes which we may expect to conflict less.

We’ll use this test board, which is somewhere between all these extremes.
There’s an algorithm to lay each routes, and it actually produces an optimal solution for an individual route, but not for all routes. It’s called Lee’s algorithm and was published back in 1960. We’ll show the code for the algorithm here, but it’s a little simplified and even then you don’t need to follow it all.
The state of the board is a grid, with the value of each square being the number of wires stacked in that location. We go through our list of routes in turn.
Solving a route has three phases - expansion, solving, laying.
In the expansion we start from the route start and move out in a wavefront, storing at each location on the board how much it could cost to lay the route that way. This way we flood out, considering every possible route. We keep going until no new location on the board has a lower cost than the cost currently at the route end.
def expand(board, obstructed, depth, route)
start_point = route.a
end_point = route.b
cost = Lee::Matrix.new(board.height, board.width)
cost[start_point.y, start_point.x] = 1
wavefront = [start_point]
loop do
new_wavefront = []
wavefront.each do |point|
point_cost = cost[point.y, point.x]
Lee.adjacent(board, point).each do |adjacent|
next if obstructed[adjacent.y, adjacent.x] == 1 && adjacent != route.b
current_cost = cost[adjacent.y, adjacent.x]
new_cost = point_cost + Lee.cost(depth[adjacent.y, adjacent.x])
if current_cost == 0 || new_cost < current_cost
cost[adjacent.y, adjacent.x] = new_cost
new_wavefront.push adjacent
end
end
end
cost_at_route_end = cost[end_point.y, end_point.x]
minimum_new_cost = new_wavefront.map { |marked| cost[marked.y, marked.x] }.min
break if cost_at_route_end > 0 && cost_at_route_end < minimum_new_cost
wavefront = new_wavefront
end
cost
end
In the solve phase we track back from the route end, following the lowest cost path through our expansion.
def solve(board, route, cost)
start_point = route.b
end_point = route.a
solution = [start_point]
loop do
adjacent = Lee.adjacent(board, solution.last)
lowest_cost = adjacent
.reject { |a| cost[a.y, a.x].zero? }
.min_by { |a| cost[a.y, a.x] }
solution.push lowest_cost
break if lowest_cost == end_point
end
end
In laying we take the list of points in the solution and increment the depth at each point to say that there is now another wire over that point.
def lay(depth, solution)
solution.each do |point|
depth[point.y, point.x] += 1
end
end
The overall algorithm is expanding, solving, laying, and then we record the solution against the route.
board.routes.each do |route|
cost = expand(board, obstructed, depth, route)
solution = solve(board, route, cost)
lay depth, solution
solutions[route] = solution
end
We can run this on a test board, and if we print some stats we’ll see for example that we laid 203 routes, costing 3304, and using a maximum depth of 3, which isn’t too bad.
routes: 203
cost: 3304
depth: 3
A problem with Lee is that it’s a lot of work for each route, and we have many routes to solve, so we’d definitely like to parallelise it, perhaps by solving more than one route at the same time.
Transactional memory could work well here. What we could do is run multiple threads, each solving routes within transactions using an STM. The board’s state would contain TVar objects containing the depth for each location.
depth = Lee::Matrix.new(board.height, board.width) { Thread::TVar.new(0) }
The code doesn’t change much. Instead of depth[adjacent.y, adjacent.x] we now write depth[adjacent.y, adjacent.x].value as these are transactional values.
wavefront.each do |point|
point_cost = cost[point.y, point.x]
Lee.adjacent(board, point).each do |adjacent|
next if obstructed[adjacent.y, adjacent.x] == 1 && adjacent != route.b
current_cost = cost[adjacent.y, adjacent.x]
new_cost = point_cost + Lee.cost(depth[adjacent.y, adjacent.x].value)
if current_cost == 0 || new_cost < current_cost
cost[adjacent.y, adjacent.x] = new_cost
new_wavefront.push adjacent
end
end
end
And we put all the phases for a single route into a transaction. These are very minimal changes for the parallelisation of an algorithm!
Thread.atomically do
cost = expand(board, obstructed, depth, route)
solution = solve(board, route, cost)
lay depth, solution
end
I implemented a version of this code using instrumentation so we can see what’s going on. It solves two routes at a time and manually checks for conflicts and can visualise the result for us.
We can use this to understand how Lee works transactionally.
This shows two routes solved concurrently. The area they needed to read from (their expansions) are shaded and the final route shown in the very thick lines. Routes already successfully laid down are shown in grey. These two routes are clearly independent - the expansions and the routes don’t overlap at all. Nothing that you needed to read to solve one route has been modified by the other. This is the perfect case - both routes get committed, we wasted no time, and we’ve successfully solved them concurrently.

This next example shows two routes with expansion areas that overlap. This means to solve the two routes there were some locations on the board that they both had to read, but neither route wrote a location read by the other. Think about if we had used the approach where we locked before reading any location - these routes would not have been able to be solved concurrently, but because we use an STM that considers both the read and write sets of both routes, they could be solved concurrently!

Next we can see two routes that clearly conflict. They both write locations that were read by the other, and the routes are also on top of each other. This will cause one route to abort, but the other can be committed, so we can still make progress.

This board shows a very important point. Note how large the lower expansion area is for the short route. This route is being solved later in the process, so the area it’s operating in is very congested, and the expansion has to move further out to keep looking for the lowest cost solution. Note that we could not have worked out how large this area was going to grow until we started to do the time-consuming work of the actual expansion. We cannot work out the read set before we start, which is what we were doing in our bank account example when we collected up all the locks and sorted them.
Through those examples we can see how the problems we had are being solved and how additional concurrency is being created.
In our instrumented implementation, 79 pairs of routes are independent, 9 pairs overlap, 27 pairs conflict and had to be retried. Note that the cost is just a little different now - this is because retrying means routes are being solved in a different order.
routes: 203
independent: 79
overlaps: 9
conflicts: 27
spare: 0
cost: 3307
depth: 3
Remember where we guessed that the main board likely would have more conflicts than the memory board? We can see that in the results here.
main memory
routes: 1506 3101
independent: 630 1459
overlaps: 34 41
conflicts: 177 100
spare: 1 1
cost: 174128 162917
depth: 3 3
We can also generate some extremes - this first board will conflict on every single pair of routes you try to solve concurrently, and the second board will never conflict.


We can also run Koichi’s implementation on our test board actually concurrently. I’ve used Thread rather than Ractor to do this though, for simplicity. I use a Queue for the list of routes to solve. We get a surprisingly low number of aborts here - I’m not sure why that is yet.
routes: 203
committed: 203
aborted: 7
cost: 3308
depth: 3
Discussion
You have to follow some rules to use an STM like the proposed design. The transactional properties only apply to the TVar objects. If you modify other objects, they won’t be part of the transaction, and if your transaction is retried they’ll be run multiple times. This also applies to side effects - if you write to a file in your transaction that may happen many times. Exceptions are also a case to consider.
Why have these TVar objects? Why not make all Ruby variable locations transactional? Maybe that’d be better, and it’d mean you could make existing code transactional. But realistically the implementation of MRI is not set up to make this kind of change easy to experiment with. Maybe it could be possible to experiment in TruffleRuby, which is designed to allow data structures to have multiple implementations because it’s part of how TruffleRuby optimizes Ruby code.
One overhead we have in our code at the moment is that we have a Matrix containing TVar objects. Instead we could have a TArray, THash, TMatrix, and other transactional variants of data structures. This could reduce some book-keeping overhead.
Other concepts we could explore are privatisation which means taking a snapshot of the board state at the start of each route, and early release which means then surrendering your claim to have read a location if you know it’s not important for your final result - so we could possibly early release the expansion area not along the final route.
There are questions about what we do when we find a conflict. Which of the two transactions do we commit and which do we abort? In Lee it might make sense to commit the longest route, or the route with the biggest expansion, or the route that took longest to solve. And can we do anything to reduce contention so that we have less conflicts in the first place?
Then there are questions about what we do when people nest transactions, and a huge number of more design questions.
There are many ways we could implement STM in Ruby - there’s a huge number of possible algorithms to use with different tradeoffs. Koichi is using an algorithm called TL2. We could also try McRT, Bartok, Swiss, Judo, NOrec, Ring, and many more.
We could also use special hardware to implement a transactional memory - a HTM. Intel added support for HTM in their Haswell cores but it had to be disabled due to bugs. Newer Intel architectures have it and working I believe, but I’m not sure how many people are using it. AMD have abandoned a similar idea. A problem with HTM is that it often has low limits for the size of transactions. Most realistic is probably a kind of hybrid transactional memory, that has a core in the hardware but implements a more extensive interface in software on top of that core.
In general, STM and HTM research seems to have slowed down now. Around 2010 it was a hugely popular idea, but now it’s not so fashionable, although new ideas around persistent memory are referring back to it. Maybe that means it’s time to sift through and figure out what really made sense and apply it in languages like Ruby?
A challenge for STM in Ruby
You’ve probably already guessed that STM has some overhead. We’re using TVar objects instead of just normal values, and you know internally it has to be tracking reads and writes. A transactional memory may also mean wasted work - if a transaction aborts and has to retry you can end up doing the same work multiple times. This can add up to a very large overhead.
By making the algorithm parallel it should hopefully run faster. But due to the overhead we may have to run a on a machine with a very large number of cores.
I’ve got a challenge for STM in Ruby from this: how many cores do you need running my Lee benchmark transactionally, with all that overhead, to beat Lee just running sequentially, without the overhead? In other words - how many cores do you need to actually solve the board in less time? A typical datacentre processor for a compute instance might have around 16 cores. Can you get the overhead low enough to beat sequential Lee with transactional Lee running on 16 cores?
More transactional benchmarks are available beyond Lee - such as Stanford’s STAMP suite, written in C, which includes a variant of Lee called Labyrinth. We could possibly port all of these to Ruby.
Appendix: Sequential performance
It’s too early to measure the performance of the Ruby STM implementation itself yet, as it’s only a proof-of-concept implementation and I’m sure it will be refined further. But the sequential version of Lee does make an interesting Ruby benchmark on its own as well - it’s producing a real result using an industrial algorithm and it takes a long time to run. I compared the performance of it on several Ruby implementations.
i/s means iterations per second (board solves per second) so higher is better. Relative speed is relative to MRI 2.7.2 without a JIT.
| Ruby | Result | Relative speed |
|---|---|---|
ruby 2.7.2p137 |
0.918 (± 0.0%) i/s | 1.00x |
ruby 2.7.2p137 +JIT |
1.101 (± 0.0%) i/s | 1.20x |
ruby 3.0.0dev 66e45dc50c |
0.836 (± 0.0%) i/s | 0.91x |
jruby 9.2.13.0 1.8.0_252-b14 +jit |
2.002 (± 0.0%) i/s | 2.18x |
jruby 9.2.13.0 25.252-b14 +indy +jit |
2.549 (± 0.0%) i/s | 2.78x |
truffleruby 20.2.0 GraalVM CE Native |
11.238 (±26.7%) i/s | 12.24x |
truffleruby 20.2.0 GraalVM CE JVM |
9.475 (±10.6%) i/s | 10.32x |
We can see that the JIT in MRI makes Ruby run 1.2x as fast as without the JIT. There also seems to be an unfortunate slowdown in 3.0 at the moment, but this is pre-release.
We can see JRuby runs around 2-3x as fast, with the invokedynamic option which is off by default adding a little extra.
TruffleRuby completely runs away here, running the same code up to 12x times as fast. TruffleRuby’s delivering that promised order-of-magnitude increase in performance here.
Notes
Lee’s algorithm was published by Lee in 1961. It was studied for parallelisation by Spiers and Edwards in 1987, and created as a transactional memory benchmark by Watson, Kirkham, and Luján in 2007.
There are several minor variations of Lee’s algorithm with different models for the cost. I’ve implemented a simple one - it’s not quite the same as the one in the papers and the details aren’t important for this article.
There are other ways we could parallelise Lee - transactional memory isn’t the only one and may not be the best. You can combine transactional memory with other techniques, such as pre-sorting routes by size or location to reduce conflicts. You could also parallelise the solution of single routes, rather than trying to solve more than one route at a time.
There was an attempt in 2004 to use HTM to parallelise Ruby, but making it invisible to the user, so that each GIL quantum was implicitly a transaction. There have been similar efforts in Python - in both PyPy and in Larry Hasting’s Gilectomy project.
References
-
C Y Lee, An Algorithm for Path Connections and Its Applications, IRE Transactions on Electronic Computers, 1961.
-
T D Spiers and D A Edwards. A high performance routing engine. In Proceedings of the 24th ACM/IEEE conference on Design Automation, 1987.
-
R Odaira, J G Castanos, H Tomari. Eliminating Global Interpreter Locks in Ruby Through Hardware Transactional Memory. In Proceedings of the 19th Symposium on Principles and Practice of Parallel Programming (PPoPP), 2014.
-
I Watson, C Kirkham, and M Luján. A study of a transactional parallel routing algorithm. In the Proceedings of the 16th International Conference on Parallel Architectures and Compilation Techniques, 2007.
-
M Ansari, C Kotselidis, I Watson, C Kirkham, M Luján, and K Jarvis. Lee-TM: A Non-Trivial Benchmark Suite for Transactional Memory. In Proceedings of Algorithms and Architectures for Parallel Processing, 2008.
-
C Cao Minh, J Woong Chung, C Kozyrakis, and K Olukotun. STAMP: Stanford transactional applications for multi-processing. In Proceedings of The IEEE International Symposium on Workload Characterization, 2008.
-
T Harris, J Larus, and R Rajwar, Transactional Memory, 2nd Edition, Morgan & Claypool, 2010.
from Hacker News https://ift.tt/3oKT62m
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.