For this post, I’m going to take artificial general intelligence (AGI) to mean an AI system that matches or exceeds humans at almost all (95%+) economically valuable work. I prefer this definition because it focuses on what causes the most societal change, rather than how we get there.
In 2015, I made the following forecasts about when AGI could happen.
- 10% chance by 2045
- 50% chance by 2050
- 90% chance by 2070
Now that it’s 2020, I’m updating my forecast to:
- 10% chance by 2035
- 50% chance by 2045
- 90% chance by 2070
I’m keeping the 90% line the same, but shifting everything else to be faster. Now, if you’re looking for an argument of why I picked these particular years, and why I shifted by 10 years instead of 5 or 15, you’re going to be disappointed. Both are driven by a gut feeling. What’s important is why parts of my thinking have changed - you can choose your own timeline adjustment based on that.
Let’s start with the easy part first.
I Should Have Been More Uncertain
It would be incredibly weird if I was never surprised by machine learning (ML) research. Historically, it’s very hard to predict the trajectory a research field will take, and if I were never surprised, I’d take that as a personal failing to not consider large enough ideas.
At the same time, when I think back on the past 5 years, I believe I was surprised more often than average. It wasn’t all in a positive direction. Unsupervised learning got better way faster than I expected. Deep reinforcement learning got better a little faster than I expected. Transfer learning has been slower than expected. Combined, I’ve decided I should widen the distribution of outcomes, so now I’m allocating 35 years to the 10%-90% interval instead of 25 years.
I also noticed that my 2015 prediction placed 10% to 50% in a 5 year range, and 50% to 90% in a 20 year range. AGI is a long-tailed event, and there’s a real possibility it’s never viable, but a 5-20 split is absurdly skewed. I’m adjusting accordingly.
Now we’re at the hard part. Why did I choose to shift the 10% and 50% lines closer to present day?
Three years ago, I was talking to someone who mentioned that there was no fire alarm for AGI. I told them I knew Eliezer Yudkowsky had written another post about AGI, and I’d seen it shared among Facebook friends, but I hadn’t gotten around to reading it. They summarized it as, “It will never be obvious when AGI is going to occur. Even a few years before it happens, it will be possible to argue AGI is far away. By the time it’s common knowledge that AI safety is the most important problem in the world, it’ll be too late.”
And my reaction was, “Okay, that matches what I’ve gotten from my Facebook timeline. I already know the story of Fermi predicting a nuclear chain reaction was very likely to be impossible, only a few years before he worked on the Manhattan Project. More recently, we had Rémi Coulom state that superhuman Go was about 10 years away, one year before the first signs it could happen, and two years before AlphaGo made it official. I also already know the common knowledge arguments for AI safety.” I decided it wasn’t worth my time to read it.
(If you haven’t heard the common knowledge arguments, here’s the quick version: it’s possible for the majority to believe AI safety is worthwhile, even if no one says so publicly, because each individual could be afraid everyone else will call them crazy if they argue for drastic action. This can happen even if literally everyone agrees, because they don’t know that everyone agrees.)
I read the post several years later out of boredom, and I now need to retroactively complain to all my Facebook friends who only shared the historical events and common knowledge arguments. Although that post summary is correct, the ideas I found useful were all outside that summary. I trusted you, filter bubble! How could you let me down like this?
Part of the fire alarm post proposes hypotheses for why people claim AGI is impossible. One of the hypotheses is that researchers pay too much attention to the difficulty of getting something working with their current tools, extrapolate that difficulty to the future, and conclude we could never create AGI because the available tools aren’t good enough. This is a bad argument, because your extrapolation needs to account for research tools also improving over time.
What “tool” means is a bit fuzzy. One clear example is our coding libraries. People used to write neural nets in Caffe, MATLAB, and Theano. Now it’s mostly TensorFlow and PyTorch. A less obvious example is feature engineering for computer vision. When was the last time anyone talked about SIFT features for computer vision? Ages ago, they’re obsolete. But feature engineering didn’t disappear, it just turned into convolutional neural net architecture tuning instead. For a computer vision researcher, SIFT features were the old tool, convolutional neural nets are the new tool, and computer vision is the application that’s been supercharged by the better tool.
Whereas for me, I’m not a computer vision person. I think ML for control is a much more interesting problem. However, you have to do computer vision to do control in image-based environments, and if you want to handle the real world, image-based inputs are the way to go. So for me, computer vision is the tool, robotics is the application, and the improvements in computer vision have driven many promising robot learning results.

(Filters automatically learned by AlexNet, which has itself been obsoleted by the better tool, ResNets.)
I’m a big advocate for research tools. I think on average, people underestimate their impact. So after reading the hypothesis that people don’t forecast tool improvement properly, I thought for a bit, and decided I hadn’t properly accounted for it either. That deserved shaving off a few years.
In the more empirical sides of ML, the obvious components of progress are your ideas and computational budget, but there are less obvious ones too, like your coding and debugging skills, and your ability to utilize your compute. It doesn’t matter how many processors you have per machine, if your code doesn’t use all the processors available. There are a surprising number of ML applications where the main value-add comes from better data management and data summarizing, because those tools free up decision making time for everything else.
In general, everyone’s research tools are deficient in some way. Research is about doing something new, which naturally leads to discovering new problems, and it’s highly unlikely someone’s already made the perfect tool for a problem that didn’t exist three months ago. So, your current research tools will always feel janky, and you shouldn’t be using that to argue anything about timelines.
The research stack has lots of parts, improvements continually happen across that entire stack, and most of these improvements have multiplicative benefits. Multiplicative factors can be very powerful. One simple example is that to get 10x better results, you can either make one thing 10x better with a paradigm shift, or you can make ten different things 1.26x better, and they’ll combine to a 10x total improvement. The latter is just as transformative, but can be much easier, especially if you get 10 experts with different skill sets to work together on a common goal. This is how corporations become a thing.
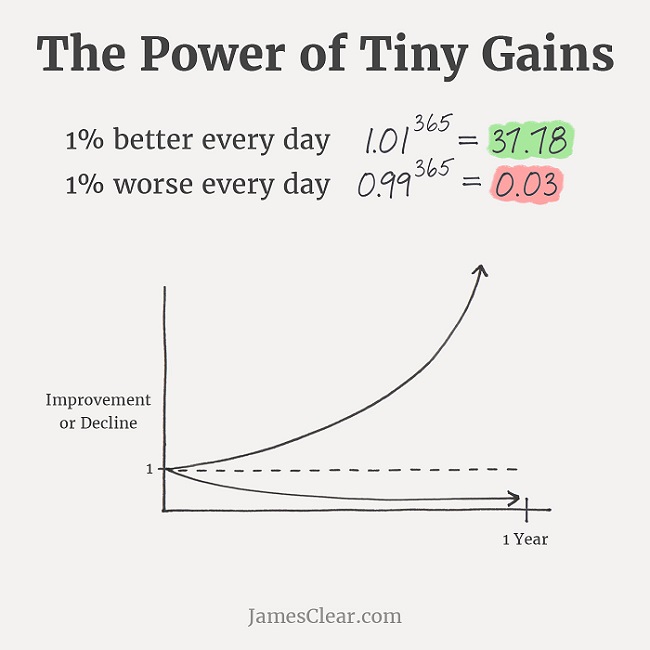
(From JamesClear.com)
Semi-Supervised and Unsupervised Learning are Getting Better
Historically, unsupervised learning has been in this weird position where it is obviously the right way to do learning, and also a complete waste of time if you want something to work ASAP.
On the one hand, humans don’t have labels for most things they learn, so ML systems shouldn’t need labels either. On the other hand, the deep learning boom of 2015 was mostly powered by supervised learning on large, labeled datasets. Richard Socher made a notable tweet at the time:
I wouldn’t say unsupervised learning has always been useless. In 2010, it was common wisdom that deep networks should go through an unsupervised pre-training step before starting supervised learning. See (Erhan et al, JMLR 2010). In 2015, self-supervised word vectors like GloVe and word2vec were automatically learning interesting relationships between words. As someone who started ML around 2015, these unsupervised successes felt like exceptions to the rule. Most other applications relied on labels. Pretrained ImageNet features were the closest thing to general behavior, and those features were learned from scratch through only supervised learning.
I’ve long agreed that unsupervised learning is the future, and the right way to do things, as soon as we figure out how to do so. But man, we have spent a long time trying to do so. That’s made me pretty impressed with the semi-supervised and unsupervised learning papers from the past few months. Momentum Contrast from (He et al, CVPR 2020) was quite nice, SimCLR from (Chen et al, ICML 2020) improved on that, and Bootstrap Your Own Latent (Grill, Strub, Altché, Tallec, Richemond et al, 2020) has improved on that. And then there’s GPT-3, but I’ll get to that later.
When I was thinking through what made ML hard, the trend lines were pointing to larger models and larger labeled datasets. They’re still pointing that way now. I concluded that future ML progress would be bottlenecked by labeling requirements. Defining a 10x bigger model is easy. Training a 10x bigger model is harder, but it doesn’t need 10x as many people to work on it. Getting 10x as many labels does. Yes, data labeling tools are getting better, Amazon Mechanical Turk is very popular, and there are even startups whose missions are to provide fast data labeling as a service. But labels are fundamentally a question about human preferences, and that makes it hard to escape human labor.
Reward functions in reinforcement learning have a similar issue. In principle, the model figures out a solution after you define what success looks like. In practice, you need a human to check the model isn’t hacking the reward, or your reward function is implicitly defined by human raters, which just turns into the same labeling problem.
Large labeled datasets don’t appear out of nowhere. They take deliberate, sustained effort to generate. There’s a reason ImageNet won the Test of Time award at CVPR 2019 - the authors of that paper went out and did the work. If ML needed ever larger labeled datasets to push performance, and models kept growing by orders of magnitude, then you’d hit a point where the amount of human supervision needed to make progress would be insane.
(This isn’t even getting into the problem of labels being imperfect. We’ve found that many labeled datasets used in popular benchmarks contain lots of bias. That isn’t surprising, but now that it’s closer to common knowledge, building a large dataset with a laissez-faire labeling system isn’t going to fly anymore.)
Okay. Well, if 10x labels is a problem, are there ways around that problem? One way is if you don’t need 10x as many labels to train a 10x larger model. The messaging on that is mixed. One scaling law paper, (Hestness et al, 2017), recommends a model size that grows sublinearly with dataset size.
We expect that number of model parameters to fit a data set should follow \(s(m) \propto \alpha m^{\beta_p}\), where \(s(m)\) is the required model size to fit a training set of size \(m\).
(From Section 2.2)
Different problem settings have different coefficients. Image classification followed a \(\beta_p=0.573\) power law, while language modeling followed a \(\beta_p \approx 0.72\) line.
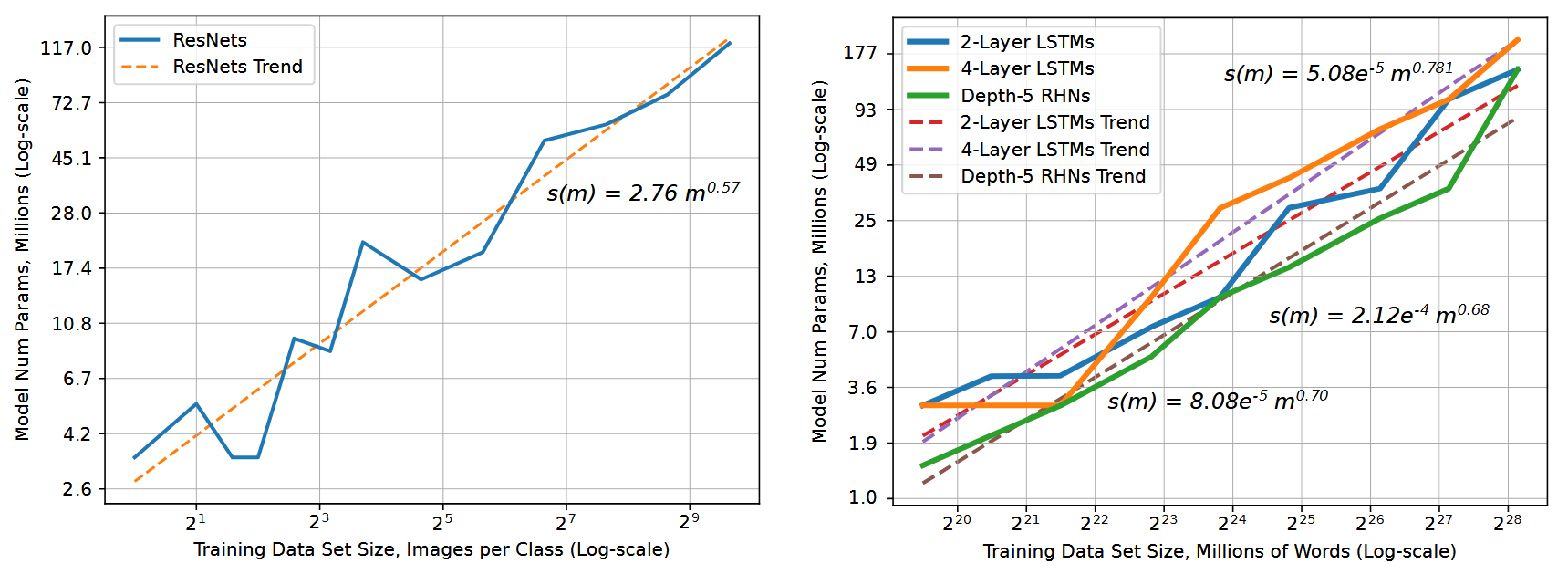
Trend lines for image classification (left) and language modeling (right) from (Hestness et al, 2017)
Inverting this suggests dataset size should grow superlinearly with model size - a 10x larger image classification model should use \(10^{1/0.573} = 55.6\)x times as much data! That’s awful news!
But, the (Kaplan and Candlish, 2020) paper suggests the inverse relationship - that dataset size should grow sublinearly with model size. They only examine language modeling, but state in Section 6.3 that
To keep overfitting under control, the results of Section 4 imply we should scale the dataset size as \(D \propto N^{0.74}\), [where \(D\) is dataset size and \(N\) is model size].
This is strange when compared to the Hestness result of \(D \propto N^{1/0.72}\) . Should the dataset grow faster or slower than the model?
The difference between the two numbers happens because the Kaplan result is derived assuming a fixed computational budget. One of the key results they found was that it was more efficient to train a very large model for a short amount of time, rather than train a smaller model to convergence. Meanwhile, as far as I could tell, the Hestness results always use models trained to convergence.
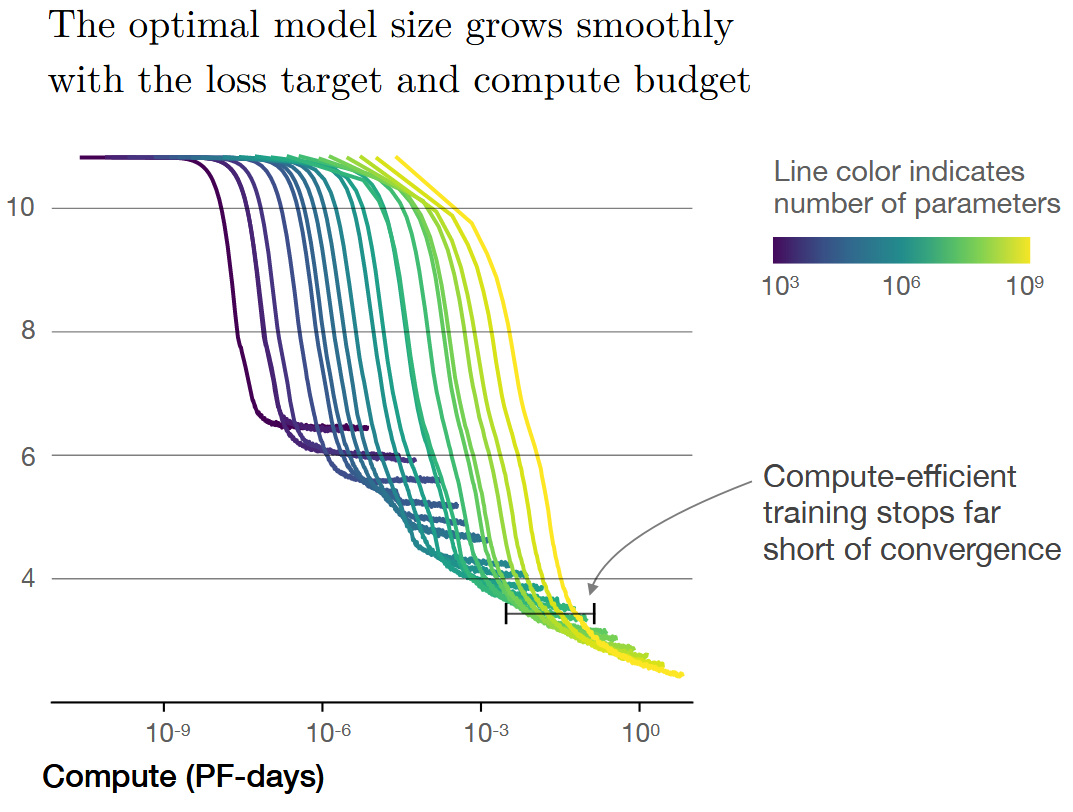
Figure 2 of (Kaplan and Candlish, 2020)
That was a bit of a digression, but after plugging the numbers in, we get that every 10x increase in model size should require between a 4x and 50x increase in dataset size. Let’s assume the 4x side to be generous. A 4x factor for label needs is definitely way better than a 10x factor, but it’s still a lot.
Enter unsupervised learning. These methods are getting better, and what “label” means is shifting towards something easier to obtain. GPT-3 is trained on a bunch of web crawling data, and although some input processing was required, it didn’t need a human to verify every sentence of text before it went into model training. At sufficient scale, it’s looking like it’s okay for your labels to be noisy and your data to be messy.
There’s a lot of potential here. If you have \(N\) unsupervised examples, then yes, \(N\) labeled examples will be better, but remember that labels take effort. The size of your labeled dataset is limited by the supervision you can afford, and you can get much more unlabeled data for the same amount of effort.
A lot of Big Data hype was driven by plots showing data was getting created faster than Moore’s Law. Much of the hype fizzled out because uninformed executives didn’t understand that having data is not the same as having useful data for machine learning. The true amount of usable data was much smaller. The research community had a big laugh, but the joke will be on us if unsupervised learning gets better and even junk data becomes marginally useful.
Is unsupervised learning already good enough? Definitely not. 100% not. It is closer than I expected it to be. I expect to see more papers use data sources that aren’t relevant to their target task, and more “ImageNet moments” where applications are built by standing on the shoulders of someone else’s GPU time.
GPT-3 Results are Qualitatively Better than I Expected
I had already updated my timeline estimates before people started toying with GPT-3, but GPT-3 was what motivated me to write this blog post explaining why.
What we’re seeing with GPT-3 is that language is an incredibly flexible input space. People have known this for a while. I know an NLP professor who said language understanding is an AI-Complete task, because a hypothetical machine that perfectly understands and replies to all questions might as well be the same as a person. People have also argued that compression is a proxy for intelligence. As argued on the Hutter Prize website, to compress data, you must recognize patterns in that data, and if you view pattern recognition as a key component of intelligence, then better compressors should be more intelligent.
To clarify: these are nowhere near universal NLP opinions! There’s lively debate over what language understanding even means. I mention them because these opinions are held by serious people, and the GPT-3 results support them.
GPT-3 is many things, but its core is a system that uses lots of training time to compress a very large corpus of text into a smaller set of Transformer weights. The end result demonstrates a surprisingly wide breadth of knowledge, that can be narrowed into many different tasks, as long as you can turn that task into a prompt of text to seed the model’s output. It has flaws, but the breadth of tech demos is kind of absurd. It’s also remarkable that most of this behavior is emergent from getting good at predicting the next token of text.
This success is a concrete example of the previous section (better unsupervised learning), and it’s a sign of the first section (better tooling). Although there’s a lot of fun stuff in story generation, I’m most interested in the code generation demonstrations. They look like early signs of a “Do What I Mean” programming interface.
If the existing tech demos could be made 5x better, I wouldn’t be surprised if they turned into critical productivity boosters for nuts-and-bolts programming. Systems design, code verification, and debugging will likely stick to humans for now, but a lot of programming is just coloring inside the lines. Even low levels of capability could be a game changer, in the same way as pre-2000 search engines. AltaVista was the 11th most visited website in 1998, and it’s certainly worse than what Google/Bing/DuckDuckGo can do now.
One specific way I could see code generation being useful is for ML for ML efforts, like neural architecture search and black-box hyperparameter optimization. One of the common arguments around AGI is intelligence explosion, and that class of black-box methods has been viewed as a potential intelligence explosion mechanism. However, they’ve long had a key limitation: even if you assume infinite compute, someone has to implement the code that provides a clean API from experiment parameters to final performance. The explorable search space is fundamentally limited by what dimensions of the search space humans think of. If you don’t envision part of the search space, machine learning can’t explore it.
Domain randomization in robot learning has the same problem. This was my main criticism of the OpenAI Rubik’s Cube result. The paper read like a year long discovery of the Rubik’s Cube domain randomization search space, rather than any generalizable robot learning lesson. The end result is based on a model learning to generalize from lots of random simulations, but that model only got there because of the human effort spent determining which randomizations were worth implementing.
Now imagine that whenever you discovered a new unknown unknown in your simulator, you could very quickly implement the code changes that add it to your domain randomization search space. Well, those methods sure look more promising!
There are certainly problems with GPT-3. It has a fixed attention window. It doesn’t have a way to learn anything it hasn’t already learned from trying to predict the next character of text. Determining what it does know requires learning how to prompt GPT-3 to give the outputs you want, and not all simple prompts work. Finally, it has no notion of intent or agency. It’s a next-word predictor. That’s all it is, and I’d guess that trying to change its training loss to add intent or agency would be much, much more difficult than it sounds. (And it already sounds quite difficult to me! Never underestimate the inertia of a working ML research project.)
But, again, this reminds me a lot of early search engines. As a kid, I was taught ways to structure my search queries to make good results appear more often. Avoid short words, place important key words first, don’t enter full sentences. We dealt with it because the gains were worth it. GPT-3 could be similar.
I don’t know where this leads, but there’s something here.
I Now Expect Compute to Play a Larger Role, and See Room for Models to Grow
For reasons I don’t want to get into in this post, I don’t like arguments where people make up a compute estimate of the human brain, take a Moore’s Law curve, extrapolate the two out, and declare that AGI will happen when the two lines intersect. I believe they oversimplify the discussion.
However, it’s undeniable that compute plays a role in ML progress. But how much are AI capabilities driven by better hardware letting us scale existing models, and how much is driven by new ML ideas? This is a complicated question, especially because the two are not independent. New ideas enable better usage of hardware, and more hardware lets you try more ideas. My 2015 guess to the horrid simplification was that 50% of AGI progress would come from compute, and 50% would come from better algorithms. There were several things missing between 2015 models, and something that put the “general” in artificial general intelligence. I was not convinced more compute would fix that.
Since then, there have been many successes powered by scaling up models, and I now think the balance is more like 65% compute, 35% algorithms. I suspect that many human-like learning behaviors could just be emergent properties of larger models. I also suspect that many things humans view as “intelligent” or “intentional” are neither. We just want to think we’re intelligent and intentional. We’re not, and the bar ML models need to cross is not as high as we think.
If compute plays a larger role, that speeds up timelines. ML ideas are bottlenecked by the size and growth of the ML community, whereas faster hardware is powered by worldwide consumer demand for hardware. The latter is a much stronger force.
Let’s go back to GPT-3 for a moment. GPT-3 is not the largest Transformer you could build, and there are reasons to build a larger one. If the performance of large Transformers scaled for 2 orders of magnitude (1.5B params for GPT-2, 175B params for GPT-3), then it wouldn’t be too weird if they scaled for another 2 orders of magnitude. Of course, it might not. The (Kaplan et al, 2020) scaling laws are supposed to start contradicting each other starting around \(10^{12}\) parameters. which is less than 1 order of magnitude away from GPT-3. That doesn’t mean the model will stop improving though. It just means it’ll improve at a different rate. I don’t see a good argument why we should be confident a 100x model would not be qualitatively different.
This is especially true if you move towards multi-modal learning. Focusing on GPT-3’s text generation is missing the main plot thread. If you believe the rumors, OpenAI has been working towards incorporating audio and visual data into their large models. So far, their research output is consistent with that. MuseNet was a generative model for audio, based on large Transformers. The recent Image GPT was a generative model for images, also based on large transformers.
Was MuseNet state-of-the-art at audio synthesis when it came out? No. Is Image GPT state-of-the-art for image generation? Also no. Model architectures designed specifically for audio and image generation do better than both MuseNet and Image GPT. Focusing on that is missing the point OpenAI is making: a large enough Transformer is not state-of-the-art, but it does well enough on these very different data formats. There’s better things than MuseNet, but it’s still good enough to power some silly yet maybe useful audio completions.
If you’ve got proof that a large Transformer can handle audio, image, and text in isolation, why not try doing so on all three simultaneously? Presumably this multi-modal learning will be easier if all the modalities go through a similar neural net architecture, and their research implies Transformers are good-enough job to be that architecture.
It helps that OpenAI can leverage any intuition they already have about very large Transformers. Once you add in other data streams, there should definitely be enough data to train much larger unsupervised models. Sure, you could use just text, but you could also use all that web text and all the videos and all the audio. There shouldn’t be a trade-off, as long as you can scale large enough.
Are large Transformers the last model architecture we’ll use? No, probably not, some of their current weaknesses seem hard to address. But I do see room for them to do more than they’ve done so far. Model architectures are only going to get better, so the capabilities of scaling up current models must be a lower bound on what could be possible 10 or 20 years from now, with scaled up versions of stronger model architectures. What’s possible right now is already interesting and slightly worrying.
The Big Picture
In “You and Your Research”, Richard Hamming has a famous piece of advice: “what are the important problems in your field, and why aren’t you working on them?” Surely AGI is one of the most important problems for machine learning.
So, for machine learning, the natural version of this question is, “what problems need to be solved to get to artificial general intelligence?” What waypoints do you expect the field to hit on the road to get there, and how much uncertainty is there about the path between those waypoints?
I feel like more of those waypoints are coming into focus. If you asked 2015-me how we’d build AGI, I’d tell you I have no earthly idea. I didn’t feel like we had meaningful in-roads on any of the challenges I’d associate with human-level intelligence. If you ask 2020-me how we’d build AGI, I still see a lot of gaps, but I have some idea how it could happen, assuming you get lucky. That’s been the biggest shift for me.
There have always been disagreements over what large-scale statisical ML means for AI. The deep learning detractors can’t deny large statisical ML models have been very useful, but deep learning advocates can’t deny they’ve been very expensive. There’s a grand tradition of pointing out how much compute goes into state-of-the-art models. See this image that made the rounds on Twitter during the Lee Se-dol match:

(By @samim)
Arguments like this are good at driving discussion to places models fall short compared to humans, and poking at ways our existing models may be fundamentally flawed, but I feel these arguments are too human-centered. Our understanding of how humans learn is still incomplete, but we still took over the planet. Similarly, we don’t need to have fine-grained agreement on what “understanding” or “knowledge” means for AI systems to have far-reaching impacts on the world. We also don’t have to build AI systems that learn like humans do. If they’re capable of doing most human-level tasks, economics is going to do the rest, whether or not those systems are made in our own image.
Trying Hard To Say No
The AGI debate is always a bit of a mess, because people have wildly divergent beliefs over what matters. One useful exercise is to assume AGI is possible in the short term, determine what could be true in that hypothetical future, then evaluate whether it sounds reasonable.
This is crucially very different from coming up with reasons why AGI can’t happen, because there are tons of arguments why it can’t happen. There are also tons of arguments why it can happen. This exercise is about putting more effort into the latter, and seeing how hard it is to say “no” to all of them. This helps you focus on the arguments that are actually important.
Let me take a shot at it. If AGI is possible soon, how might that happen? Well, it would require not needing many more new ideas. It would likely be based on scaling existing models, because I don’t think there’s much time for the field to do a full-scale paradigm shift. And, it’s going to need lots of funding, because it needs to be based on scaling, and scaling needs funding.
Perhaps someone develops an app or tool, using a model of GPT-3’s size or larger, that’s a huge productivity multiplier. Imagine the first computers, Lotus Notes, or Microsoft Excel taking over the business world. Remember, tools drive progress! If you code 2x faster, that’s probably 1.5x as much research output. Shift up or down depending on how often you’re bottlenecked by implementation.
If that productivity boost is valuable enough to make the economics work out, and you can earn net profit once you account for inference and training costs, then you’re in business - literally. Big businesses pay for your tool. Paying customers drives more funding and investment, which pays for more hardware, which enables even larger training runs. In cloud computing, you buy excess hardware to anticipate spikes in consumer demand, then sell access to the extra hardware to earn money. In this scenario, you buy excess hardware to anticipate spikes in consumer inference needs, then give excess compute capacity to research to see what they come up with.
This mechanism is already playing out. You might recognize the chip below.

It’s a picture of the first TPU, and as explained in a Google blog post,
Although Google considered building an Application-Specific Integrated Circuit (ASIC) for neural networks as early as 2006, the situation became urgent in 2013. That’s when we realized that the fast-growing computational demands of neural networks could require us to double the number of data centers we operate.
Google needed to run more neural nets in production. This drove more hardware investment. A few years later, and we’re now on TPUv3, with rumors that Facebook is hiring hardware people to build custom silicon for AR technology. So the story for hardware demand seems not just plausible, but likely to be true. If you can scale to do something impractically, that sparks research and demand into making it practical.
On top of this, let’s assume cross-modality learning turns out to be easier than expected at scale. Similar emergent properties as GPT-3 show up. Object tracking and intuitive physics turn out to be naturally occurring phenomena that are learnable just from images, without direct environment interaction or embodiment. With more tweaks, even larger models, and even more data, you end up with a rich feature space for images, text, and audio. It quickly becomes unthinkable to train anything from scratch. Why would you?
Much of the prior work in several fields gets obsoleted, going the way of SIFT features for vision, parse trees for machine translation, and phoneme decoding steps for speech recognition. Deep learning has already killed these methods. People who don’t know any of those techniques are working on neural nets that achieve state-of-the-art results in all three domains. That’s faintly sad, because some of the obsolete ideas are really cool decompositions of how we understand language and speech, but it is what it is.
As models grow larger, and continue to demonstrate improved performance, research coalesces around a small pool of methods that have been shown to scale with compute. Again, that happened and is still happening with deep learning. When lots of fields use the same set of techniques, you get more knowledge sharing, and that drives better research. CNNs have heavy priors towards considering nearby values. They were first useful for image recognition, but now have implications for genomics (Nature Genetics, 2019), as well as music generation (van den Oord et al, 2016). Transformers are a sequence model that were first used for language modeling. They were later applied to video understanding (Sun et al, 2019). This trend is likely to continue. Machine learning has hit a point where describing something as “deep learning” is practically meaningless, since multilayer perceptions have integrated with enough of the field that you’re no longer specifying anything. Maybe five years from now, we’ll have a new buzzword that takes deep learning’s place.
If this model is good at language, speech, and visual data, what sensor inputs do humans have that this doesn’t? It’s just the sensors tied to physical embodiment, like taste and touch. Can we claim intelligence is bottlenecked on those stimuli? Sure, but I don’t think it is. You arguably only need text to pretend to be human.
A lot has to go right in this scenario above. Multi-modal learning has to work. Behaviors need to continue to emerge out of scaling, because your researcher timer is mostly going into ideas that help you scale, rather than inductive priors. Hardware efficiency has to match pace, which includes clean energy generation and fixing your ever-increasing hardware fleet. Overall, the number of things that have to go right makes me think it’s unlikely, but still a possibility worth taking seriously.
The most likely problem I see with my story is that unsupervised learning could be way harder for anything outside of language. Remember, in 2015, unsupervised learning gave us word vectors for language, and nothing great for images. One reasonable hypothesis is that the compositional properties of language make it well suited to unsupervised learning, in a way that isn’t true for other input modalities. If that’s true, I could be overestimating research by paying too much attention to the successes.
It’s for those reasons that I’m only adjusting my estimates by a few years. I don’t think GPT-3, by itself, is a reason to radically adjust what I believe to be possible. I think transfer learning being harder than anticipated is also a damper on things. But on net, I’ve mostly seen reasons to speed up my estimates, rather than slow them down.
Thanks to all the people who gave feedback on earlier drafts, including: Michael Andregg, James Bradbury, Ethan Caballero, Ajeya Cotra, William Fedus, Nolan Kent, David Krueger, Simon Ramstedt, and Alex Ray.
from Hacker News https://ift.tt/3gyD5r2
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.