Today CenturyLink/Level(3), a major ISP and Internet bandwidth provider, experienced a significant outage that impacted some of Cloudflare’s customers as well as a significant number of other services and providers across the Internet. While we’re waiting for a post mortem from CenturyLink/Level(3), I wanted to write up the timeline of what we saw, how Cloudflare’s systems routed around the problem, why some of our customers were still impacted in spite of our mitigations, and what appears to be the likely root cause of the issue.
Increase In Errors
At 10:03 UTC our monitoring systems started to observe an increased number of errors reaching our customers’ origin servers. These show up as “522 Errors” and indicate that there is an issue connecting from Cloudflare’s network to wherever our customers’ applications are hosted.
Cloudflare is connected to CenturyLink/Level(3) among a large and diverse set of network providers. When we see an increase in errors from one network provider, our systems automatically attempt to reach customers’ applications across alternative providers. Given the number of providers we have access to, we are generally able to continue to route traffic even when one provider has an issue.

Automatic Mitigations
In this case, beginning within seconds of the increase in 522 errors, our systems automatically rerouted traffic from CenturyLink/Level(3) to alternate network providers we connect to including Cogent, NTT, GTT, Telia, and Tata.
Our Network Operations Center was also alerted and our team began taking additional steps to mitigate any issues our automated systems weren’t automatically able to address beginning at 10:09 UTC. We were successful in keeping traffic flowing across our network for most customers and end users even with the loss of CenturyLink/Level(3) as one of our network providers.
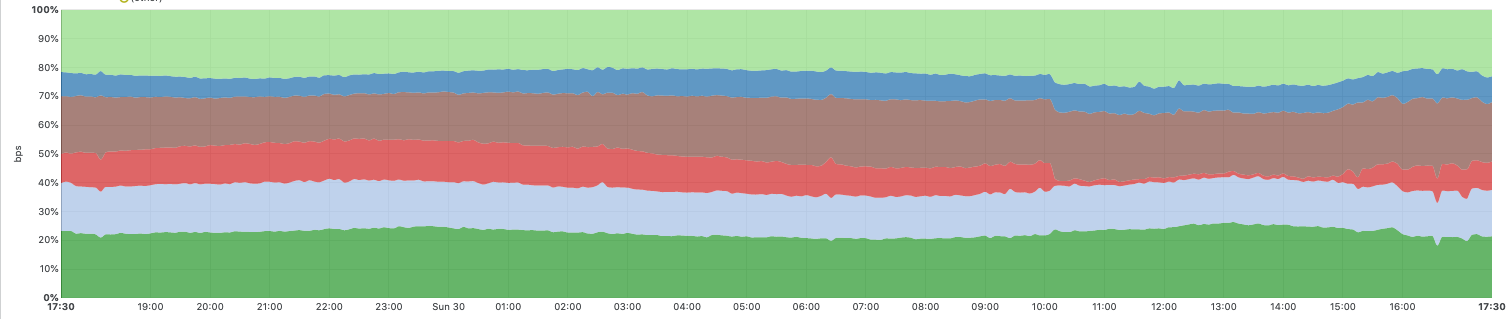
The graph below shows traffic between Cloudflare’s network and six major tier-1 networks that are among the network providers we connect to. The red portion shows CenturyLink/Level(3) traffic, which dropped to near-zero during the incident. You can also see how we automatically shifted traffic to other network providers during the incident to mitigate the impact and ensure traffic continued to flow.
The following graph shows 522 errors (indicating our inability to reach customers’ applications) across our network during the time of the incident.
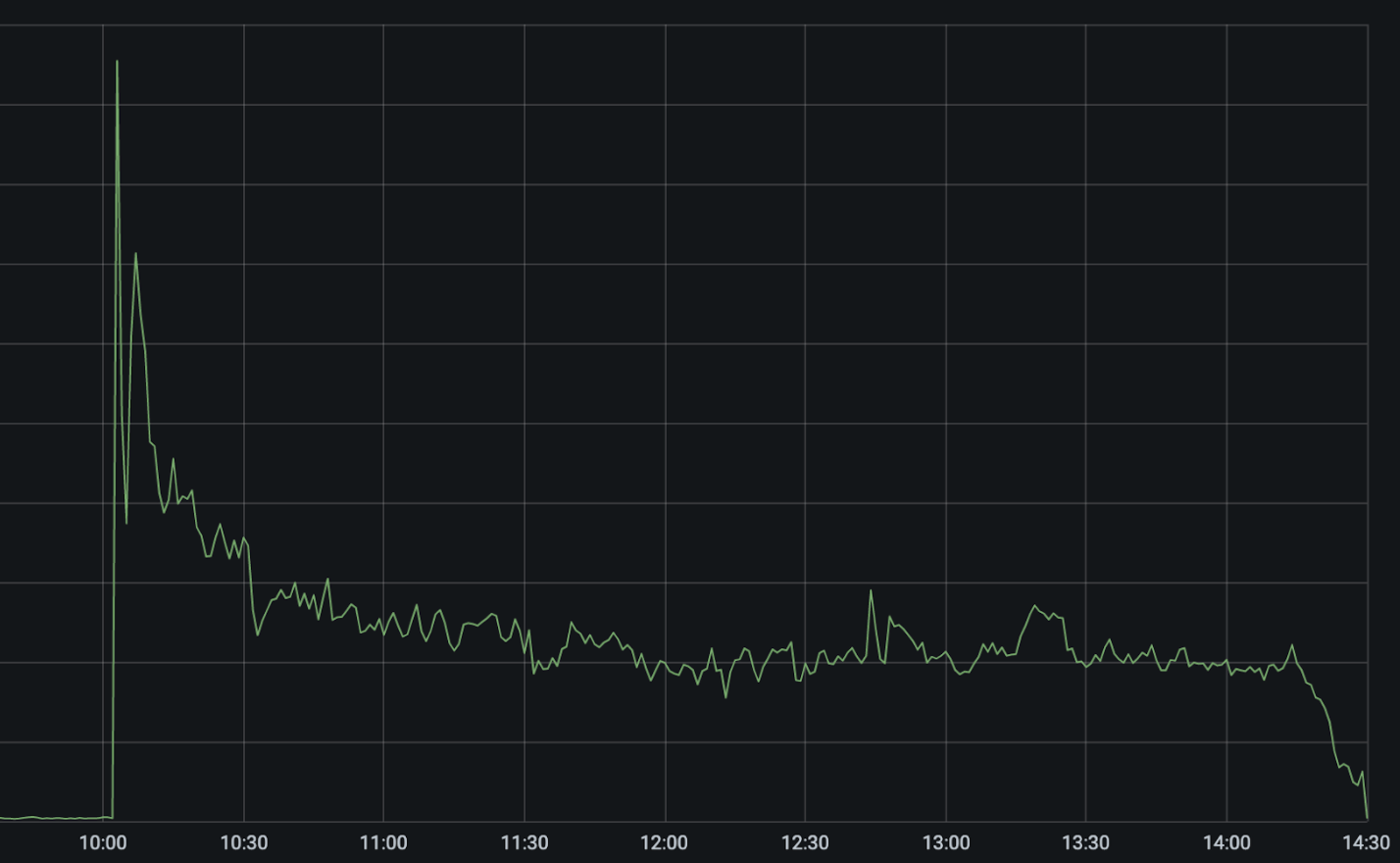
The sharp spike up at 10:03 UTC was the CenturyLink/Level(3) network failing. Our automated systems immediately kicked in to attempt to reroute and rebalance traffic across alternative network providers, causing the errors to drop in half immediately and then fall to approximately 25 percent of the peak as those paths were automatically optimized.
Between 10:03 UTC and 10:11 UTC our systems automatically disabled CenturyLink/Level(3) in the 48 cities where we’re connected to them and rerouted traffic across alternate network providers. Our systems take into account capacity on other providers before shifting out traffic in order to prevent cascading failures. This is why the failover, while automatic, isn’t instantaneous in all locations. Our team was able to apply additional manual mitigations to reduce the number of errors another 5 percent.
Why Did the Errors Not Drop to Zero?
Unfortunately, there were still an elevated number of errors indicating we were still unable to reach some customers. CenturyLink/Level(3) is among the largest network providers in the world. As a result, many hosting providers only have single-homed connectivity to the Internet through their network.
To use the old Internet as a “superhighway” analogy, that’s like only having a single offramp to a town. If the offramp is blocked, then there’s no way to reach the town. This was exacerbated in some cases because CenturyLink/Level(3)’s network was not honoring route withdrawals and continued to advertise routes to networks like Cloudflare’s even after they’d been withdrawn. In the case of customers whose only connectivity to the Internet is via CenturyLink/Level(3), or if CenturyLink/Level(3) continued to announce bad routes after they'd been withdrawn, there was no way for us to reach their applications and they continued to see 522 errors until CenturyLink/Level(3) resolved their issue around 14:30 UTC.
The same was a problem on the other (“eyeball”) side of the network. Individuals need to have an onramp onto the Internet’s superhighway. An onramp to the Internet is essentially what your ISP provides. CenturyLink is one of the largest ISPs in the United States.
Because this outage appeared to take all of the CenturyLink/Level(3) network offline, individuals who are CenturyLink customers would not have been able to reach Cloudflare or any other Internet provider until the issue was resolved. Globally, we saw a 3.5% drop in global traffic during the outage, nearly all of which was due to a nearly complete outage of CenturyLink’s ISP service across the United States.
So What Likely Happened Here?
While we will not know exactly what happened until CenturyLink/Level(3) issue a post mortem, we can see clues from BGP announcements and how they propagated across the Internet during the outage. BGP is the Border Gateway Protocol. It is how routers on the Internet announce to each other what IPs sit behind them and therefore what traffic they should receive.
Starting at 10:04 UTC, there were a significant number of BGP updates. A BGP update is the signal a router makes to say that a route has changed or is no longer available. Under normal conditions, the Internet sees about 1.5MBs – 2MBs of BGP updates every 15 minutes. At the start of the incident, the number of BGP updates spiked to more than 26MBs of BGP updates per 15 minute period and stayed elevated throughout the incident.

These updates show the instability of BGP routes inside the CenturyLink/Level(3) backbone. The question is what would have caused this instability. The CenturyLink/Level(3) status update offers some hints and points at a flowspec update as the root cause.

What’s Flowspec?
In CenturyLink/Level(3)’s update they mention that a bad Flowspec rule caused the issue. So what is Flowspec? Flowspec is an extension to BGP, which allows firewall rules to be easily distributed across a network, or even between networks, using BGP. Flowspec is a powerful tool. It allows you to efficiently push rules across an entire network almost instantly. It is great when you are trying to quickly respond to something like an attack, but it can be dangerous if you make a mistake.
At Cloudflare, early in our history, we used to use Flowspec ourselves to push out firewall rules in order to, for instance, mitigate large network-layer DDoS attacks. We suffered our own Flowspec-induced outage more than 7 years ago. We no longer use Flowspec ourselves, but it remains a common protocol for pushing out network firewall rules.
We can only speculate what happened at CenturyLink/Level(3), but one plausible scenario is that they issued a Flowspec command to try to block an attack or other abuse directed at their network. The status report indicates that the Flowspec rule prevented BGP itself from being announced. We have no way of knowing what that Flowspec rule was, but here’s one in Juniper’s format that would have blocked all BGP communications across their network.
route DISCARD-BGP {
match {
protocol tcp;
destination-port 179;
}
then discard;
}
Why So Many Updates?
A mystery remains, however, why global BGP updates stayed elevated throughout the incident. If the rule blocked BGP then you would expect to see an increase in BGP announcements initially and then they would fall back to normal.
One possible explanation is that the offending Flowspec rule came near the end of a long list of BGP updates. If that were the case, what may have happened is that every router in CenturyLink/Level(3)’s network would receive the Flowspec rule. They would then block BGP. That would cause them to stop receiving the rule. They would start back up again, working their way through all the BGP rules until they got to the offending Flowspec rule again. BGP would be dropped again. The Flowspec rule would no longer be received. And the loop would continue, over and over.
One challenge of this is that on every cycle, the queue of BGP updates would continue to increase within CenturyLink/Level(3)’s network. This may have gotten to a point where the memory and CPU of their routers was overloaded, causing an additional set of challenges to getting their network back online.
Why Did It Take So Long to Fix?
This was a significant global Internet outage and, undoubtedly, the CenturyLink/Level(3) team received immediate alerts. They are a very sophisticated network operator with a world class Network Operations Center (NOC). So why did it take more than four hours to resolve?
Again, we can only speculate. First, it may have been that the Flowspec rule and the significant load that large number of BGP updates imposed on their routers made it difficult for them to login to their own interfaces. Several of the other tier-1 providers took action, it appears at CenturyLink/Level(3)’s request, to de-peer their networks. This would have limited the number of BGP announcements being received by the CenturyLink/Level(3) network and helped give it time to catch up.
Second, it also may have been that the Flowspec rule was not issued by CenturyLink/Level(3) themselves but rather by one of their customers. Many network providers will allow Flowspec peering. This can be a powerful tool for downstream customers wishing to block attack traffic, but can make it much more difficult to track down an offending Flowspec rule when something goes wrong.
Finally, it never helps when these issues occur early on a Sunday morning. Networks the size and scale of CenturyLink/Level(3)’s are extremely complicated. Incidents happen. We appreciate their team keeping us informed with what was going on throughout the incident. #hugops
from Hacker News https://ift.tt/2QBpXGL
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.