Producing readable, idiomatic Rust code is a major goal of C2Rust, our project to accelerate migration of C code into Rust. One hurdle we faced is the mismatch between C headers and the Rust module system. C and Rust are similar in many ways: they're both performance oriented languages with explicit memory management and full control over every aspect of the system. Rust's module system is a huge improvement over C header files. Modules declare an interface of type declarations and functions for other modules to use. In contrast, C has no such modern conveniences, so declarations must be duplicated in each source file. If C2Rust is going to produce reasonable Rust code, we have to bridge that gap by de-duplicating and merging declarations across modules.
TL;DR: As of the latest C2Rust version (0.14), the transpiler now emits declarations from C headers as module imports in Rust, instead of duplicating them in each source file! Just use --emit-build-files to generate a cargo project for the transpiled code:
c2rust transpile --emit-build-files compile_commands.json Besides being easier on the eyes, merging header declarations is a critical improvement to the maintainability of C2Rust generated code. You can now modify types and declarations once and rely on the Rust compiler to enforce type safety rather than duplicating error-prone edits across an entire codebase. This blog post is the story of how we did this, with all the tricky corner cases, weird C patterns, and dragons that we came across along the way.
The Problem: Separate Compilation
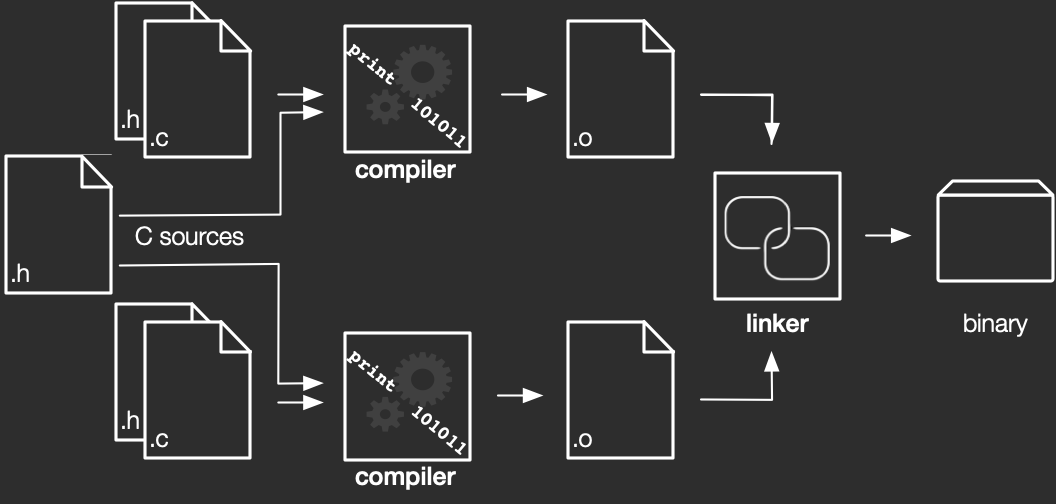
When building C code, the compiler translates each C source file separately into object files, as in the figure above. The build system then passes these objects to the linker, which takes the objects and matches up each reference to a name to the definition of the name. Because the compiler handles each C file separately, it has no way to know what definitions or types are declared in other files. Enter header files: headers allow the programmer to separate declarations out into reusable files that can then be included into each source file as needed. In C2Rust we also transpile each C source file separately, including all header declarations that are included in it. While this configuration exactly replicates how a normal C compiler works, it results in lots of duplicated type and functions declarations in the output Rust code. For example, the following declarations would get duplicated in each module that used the foo function.
struct Point { x: libc::c_int, y: libc::c_int, } extern "C" { #[no_mangle] fn foo(_: *const Point) -> libc::c_int; } Referencing functions and types via extern declarations works, but it's not at all idiomatic for Rust. If we wanted to change the type signature of the foo function, we would have to modify it in every file that contains its extern declaration, and forgetting any would silently fail. What we would really like instead is for the transpiler to produce is a single definition of function foo in the correct module, and import this declaration with use mod_foo::foo; wherever it is used. Having a single canonical definition of each function and type would then avoid error-prone duplication of declarations across the codebase.
The Solution: Merging Declarations
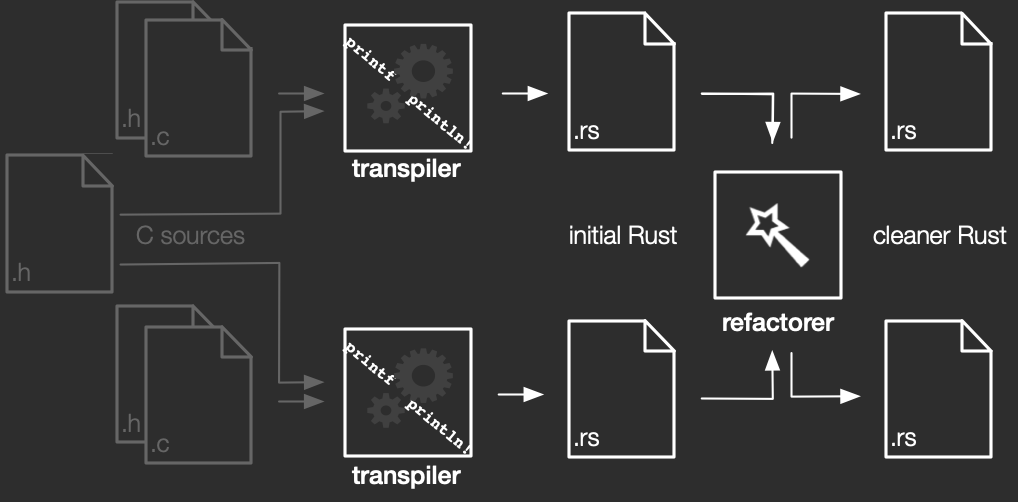
One option to remove the duplicated declarations would be to modify the C2Rust transpiler to read in all C files, merge declarations and definitions, and emit more idiomatic, de-duplicated Rust code. However, all-at-once transpiling doesn't fit well into the separate compilation model of C; it would prevent parallelizing transpilation and might require significant changes to the current infrastructure. Instead, we can parse the Rust code after transpiling, merge declarations, and rewrite the Rust files, effectively implementing a source-level version of the linker (as shown in the figure above). We already have a framework for building Rust refactorings, so this fits well into the rest of the C2Rust project infrastructure.
An Example
Before we think about how to automate this refactoring, let's manually step through the process of merging the header declarations for a simple example. Let's assume the function distance is defined in operations.c, which we'll omit here.
operations.h:
typedef struct { int x; int y; } Point; unsigned distance(Point *p1, Point *p2); main.c:
#include "operations.h" void main(int argc, char *argv[]) { Point p, q; /* ... */ unsigned d = distance(&p, &q); } After we run this through C2Rust, we get Rust code for main that looks something like:
extern "C" { #[no_mangle] fn distance(p1: *mut Point, p2: *mut Point) -> libc::c_uint; } #[derive(Copy, Clone)] #[repr(C)] pub struct Point { pub x: libc::c_int, pub y: libc::c_int, } unsafe fn main(mut argc: libc::c_int, mut argv: *mut *mut libc::c_char) { let mut p: Point = Point{x: 0, y: 0,}; let mut q: Point = Point{x: 0, y: 0,}; /* ... */ let mut d: libc::c_uint = distance(&mut p, &mut q); } Then in operations.rs we get the same struct definition for Point again, along with the definition of the function distance. When the Rust compiler compiles the main module, it doesn't care where distance is defined, and just assumes that we will supply the symbol distance to the linker with a definition that matches the extern declaration above.
The first step in cleaning this up looks pretty obvious: we should replace the extern "C" function declaration with an import of the function definition in Rust. Following our example, we should rewrite main.rs into:
use operations::distance; #[derive(Copy, Clone)] #[repr(C)] pub struct Point { pub x: libc::c_int, pub y: libc::c_int, } unsafe fn main(mut argc: libc::c_int, mut argv: *mut *mut libc::c_char) { let mut p: Point = Point{x: 0, y: 0,}; let mut q: Point = Point{x: 0, y: 0,}; /* ... */ let mut d: libc::c_uint = distance(&mut p, &mut q); } While this gets us the right function definition, the parameter types won't match. The Point struct in main is not the same Point as in operations. In C this isn't an issue, as these two type declarations are compatible, but Rust is strongly typed and treats each declaration as a different type. We need to unify the struct declarations and use the same type in both modules.
For this example, let's remove the declaration of Point in main.rs and use the one from operations, so we get the following main module:
use operations::{distance, Point}; unsafe fn main(mut argc: libc::c_int, mut argv: *mut *mut libc::c_char) { let mut p: Point = Point{x: 0, y: 0,}; let mut q: Point = Point{x: 0, y: 0,}; /* ... */ let mut d: libc::c_uint = distance(&mut p, &mut q); } Automating the Refactoring
Now that we've seen how the refactoring process should work, we need to automate it. At a high level, the refactoring collects declarations from headers, then for each unique declaration, picks a canonical declaration or matches it against a definition and updates all references to point to that canonical declaration or definition.
To make the refactoring process simpler to automate, we first make the transpiler separate out which Rust items came from shared headers and which were in the C file. This separation lets us quickly select declarations for merging. For example, the C2Rust transpiler marks declarations of Point and distance as coming from the header operations.h like this:
#[c2rust::header_src = "operations.h"] pub mod operations_h { #[derive(Copy, Clone)] #[repr(C)] pub struct Point { pub x: libc::c_int, pub y: libc::c_int, } extern "C" { #[no_mangle] pub fn distance(p1: *mut Point, p2: *mut Point) -> libc::c_uint; } } pub use self::operations_h::{Point, distance}; unsafe fn main(mut argc: libc::c_int, mut argv: *mut *mut libc::c_char) { let mut p: Point = Point{x: 0, y: 0,}; let mut q: Point = Point{x: 0, y: 0,}; /* ... */ let mut d: libc::c_uint = distance(&mut p, &mut q); } The refactoring engine then scans through the crate, de-duplicating declarations that can be merged. We de-duplicate declarations based on type equality and name. As we will see below, this comparison differs depending on the type of declaration. After de-duplicating all declarations, the refactoring needs to match declarations against defined globals and functions and replace uses of declarations with their definition if available. Finally, the refactoring relocates all remaining declarations from their header to new home modules and rewrites all uses to reference the new declaration paths.
To understand how we compare and de-duplicate declarations, we must first take a quick detour into C and Rust's name space rules (not to be confused with C++ namespaces). In C (and Rust), a name space can be thought of as the category of a particular item. For example, functions in C are in the ordinary identifier namespace, while structs and enums are classified into the tag namespace (see C99 standard 6.2.3). C and Rust allow different declarations with the same name to co-exist, as long as they are in different namespaces. In C, this means that we can declare a struct foo and a function foo in the same scope without any conflict.
Rust has three different namespaces: the type, value, and macro namespaces. For the purposes of refactoring transpiled code we can ignore the macro namespace since the transpiler never creates macros. However, the distinction between the type and value namespaces is important. All type declarations (struct, enum, type, etc.) are part of the type namespace. fn definitions, static globals and const declarations are in the value namespace. Thus we can declare both a fn foo and a struct foo in the same Rust module without conflicts.
To de-duplicate declarations while we scan header modules, we keep a list of declarations that we have seen, indexed by namespace and name. Then for each declaration, we look up a list of potential matches with the same name in the same namespace. If we don't find an equivalent declaration (we'll clarify what we mean by equivalence later on) in this list, we add the declaration to the list. When this process finishes, we are left with a collection of all unique declarations from header modules.
After the refactoring collects all unique declarations, it needs to match these declarations to definitions, when available. We want to match declarations against global variable and function definitions visible outside their translation unit (i.e. not static in the C sense). If we find a definition for a header declaration, the refactoring replaces uses of the header declaration with a Rust use import of the definition itself.
Finally, for all remaining declarations we need to emit the declaration someplace and replace all uses of equivalent declarations with the one canonical version of that declaration. We'll discuss heuristics for where to place declarations later on, but the refactoring will be correct as long as we emit each declaration in a module where its name doesn't conflict with any other item in the same namespace.
Putting everything together, here's a real example of the refactoring in action, taken from a transpiled version of libxml2:
Before
extern "C" { pub type _IO_wide_data; pub type _IO_codecvt; pub type _IO_marker; #[no_mangle] fn fclose(__stream: *mut FILE) -> libc::c_int; #[no_mangle] fn fopen(_: *const libc::c_char, _: *const libc::c_char) -> *mut FILE; #[no_mangle] fn fprintf(_: *mut FILE, _: *const libc::c_char, _: ...) -> libc::c_int; #[no_mangle] fn sscanf(_: *const libc::c_char, _: *const libc::c_char, _: ...) -> libc::c_int; #[no_mangle] fn memset(_: *mut libc::c_void, _: libc::c_int, _: libc::c_ulong) -> *mut libc::c_void; #[no_mangle] fn strcpy(_: *mut libc::c_char, _: *const libc::c_char) -> *mut libc::c_char; #[no_mangle] fn strlen(_: *const libc::c_char) -> libc::c_ulong; #[no_mangle] fn malloc(_: libc::c_ulong) -> *mut libc::c_void; #[no_mangle] fn realloc(_: *mut libc::c_void, _: libc::c_ulong) -> *mut libc::c_void; #[no_mangle] fn free(__ptr: *mut libc::c_void); #[no_mangle] fn getenv(__name: *const libc::c_char) -> *mut libc::c_char; } pub type size_t = libc::c_ulong; pub type __off_t = libc::c_long; pub type __off64_t = libc::c_long; After
pub use crate::stddef_h::size_t; pub use crate::stdlib::{ _IO_codecvt, _IO_marker, _IO_wide_data, __off64_t, __off_t, FILE, }; use crate::stdlib::{ fclose, fopen, fprintf, free, getenv, malloc, memset, realloc, sscanf, strcpy, strlen, }; Corner Cases, or wait, why is the compiler still yelling at me?
In the description above we've glossed over the corner cases we hit along the way. C programs have an unfortunate tendency to exercise all the weirdest corner cases one can imagine. Here's a few of the important ones we came across.
Corner Case #1: What even is Equality?
The C99 standard defines compatible types fairly narrowly (allowing, e.g., incomplete struct declarations to be compatible with the complete declaration, but not much else). C code with two incompatible type declarations for the same object or function has undefined behavior. In reality, however, compilers can't actually check that all declarations referring to an object or function in another translation unit have compatible types. Since the compiler processes each translation unit separately, it won't see the conflicting types in different translation units.
Since C is extremely permissive in practice when it comes to declaration type mismatches, we will see declarations that don't strictly match the type of their definition but that we still want to unify. For example, a function might be declared with a non-const pointer parameter but the definition of the function specifies a const pointer. In cases like these we still want the declaration to match the function definition, even though it isn't equivalent.
We can split C declarations into two categories: values and types. This happens to correspond (for good reasons) to the Rust namespaces we mentioned above. In this context, global variables and functions are values, and all other declarations (structs, unions, enums, typedefs) are types. The linker resolves value declarations to a single definition after compilation, while the compiler never actually resolves types across translation units. While the C99 standard says that incompatible types across translation units is undefined behavior, the compiler has no way to enforce this, so we can't always rely on the C99 definition of compatibility.
Comparing two declarations of values is easy: we simply compare their names for equality. The linker only resolves references to values by name, regardless of type, so we can do the same. We added some extra sanity checking for global arrays and found real-world examples where the size of an array declaration didn't match its definition. Aside from that case, it seems that in practice most global declaration types match their definitions. Functions are another matter entirely. We match extern function declarations against any exported function definition with the same name, regardless of parameter and return types. Since we are merging function and global declarations that may not be type-compatible in Rust, we need to be sure to fix uses of these declarations after we replace them with their definitions when necessary. We insert casts to the appropriate types at uses of functions or globals where the expected type differs from our rewritten type.
For type declarations, we found that most code does in fact comply with the C99 definition of compatible types, so we implemented a comparison based on this definition. In short, primitive types are compatible if they are the same, and structs are compatible if they have the same name and if all fields have the same name and type, in the same order. Incomplete structs are compatible with any struct having the same name. This definition of equality is conservative, but that is fine for our purposes since not unifying two types in different modules is always a safe default.
Corner Case #2: Unnamed Declarations
C allows nesting of anonymous structs and unions, for example, in the following the struct containing x and y doesn't have a name:
struct S { struct { int x; int y; } point; }; Rust doesn't allow this syntax, each struct and union must be given a name. To deal with this, C2Rust creates new, artificial names for the nested structs, like so:
pub struct S { pub point: C2RustUnnamed, } pub struct C2RustUnnamed { pub x: libc::c_int, pub y: libc::c_int, } As discussed above, we compare struct declarations for equality by their names, in addition to their field names and types. However, the artificial names created for anonymous types by the transpiler won't match across translation units. Consequently we need to loosen our definition of type equality to ignore the names of structs and unions if they are artificial. As shown above, we give these artificial names a distinctive pattern, C2RustUnnamed..., so we can ignore these names when comparing types.
Decisions: Where should it live?
So far we've hand waved away an important aspect of this refactoring: now that we've merged all copies of a declaration, where should we emit it? For declarations of values (functions and globals) found elsewhere in the codebase, there is a clear answer: we leave the value in the module it was defined in and replace all other declarations with imports of the definition. However, for types or functions in other libraries there is not an obvious home for the merged declaration, so we resort to heuristics.
The principle of least surprise is critical here; we want a programmer to easily locate type declarations where they expect to find them in the transpiled Rust code. We could imagine all sorts of ways to locate declarations, e.g., emitting each declaration in the module with the most references to it, or emitting declarations in the module containing their allocation site, but these heuristics are brittle and may not make sense to the programmer in all cases. For now we've settled on the following rules, although this may certainly evolve over time.
We emit a declaration d in the module M if all of the following hold:
- The C file corresponding to
M(M.c) included the header containingd. Mdoes not already contain an item with the same namespace and name asd.dis declared inM.h. That is, the header has the same base name (ignoring suffixes) asM.c.
For example, we would place a declaration d from block.h into the module for block.c.
If any of the conditions above do not apply, emit d in a new header module which will contain declarations from that header. For example, we would make a new module header_h containing all declarations from header.h assuming we don't have a header.c module.
Conclusion
Source code linking of declarations from C headers is a critical step towards generating idiomatic Rust code. You can now refactor types and function signatures in transpiled code with ease; the Rust compiler will catch any resulting type mismatches at declaration use sites. Much work remains, of course, to further enhance the quality of the Rust code we output but we are nevertheless one step closer to rewriting the world in Rust!
Give the new transpiler features a whirl, and let us know what you'd like to see next.
from Hacker News https://ift.tt/2PW2Vd4
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.