I wrote this post over a month ago and then I kept digging, so I never posted this. At the end of the post I talk about the absurdity of persistence APIs on the web. I'll be releasing a new project soon which solves this.
I'm on vacation, so naturally I'm thinking of some important things to change in Actual. This is a super technical post about how I'm approaching this decision.
For some context, let me explain how part of Actual works. There's a lot of "computed data" in the budget, which means data that depends on other data. To get an "amount to budget" for the current month, it needs the balance for each category from last month, which depends on the budgeted and spent amount in each category, etc. In fact, to compute the current month's budget numbers, it needs to compute numbers for all months before it.
While most budget numbers are computed by simple adding or subtracting numbers, the spent amount for a single category runs a SQL query to compute it. If you have a moderate amount of categories (like 30) and ~5 years worth of data, computing the entire budget would require thousands of SQL queries. That isn't so bad; sqlite could probably handle that around one second. But it doesn't scale well: if a user had 100 categories and even more data, suddenly we're running tens of thousands of queries and taking many more seconds.
Obviously, we don't want to always recompute the entire budget. The problem is app startup; once the app is running, dependencies are tracked so updating data only recomputes the necessary dependencies. But on startup, a naive implementation would need to recompute the entire budget.
We obviously need a persistent cache. By writing all the computed values to disk, we can read them on startup and skip computing everything which is way faster. That should strike fear into the hearts of all developers though: how do we know if the cache is up-to-date? This could lead to bugs where we show stale data.
We could take a different approach and model the computed data as relational data inside the database. For example, having a
category_spentrow withcategoryId,month, andvaluecolumns. That just makes the problem worse though: this is computed data and should be handled in a way where it's easy to recompute everything in case of a stale data bug. Thinking of it as computations + a persistent cache that can be thrown away is a better way to approach it.
In fact, Actual already has a cache for all these computed values. It doesn't recompute everything on startup. However, due to legacy reasons we store it in the sqlite database with everything else. There are a few problems with this:
-
With lots of categories and budget months, it ends up being a lot of data and bloats the database size.
-
It's not clear when the cached values are up-to-date. We can't take a snapshot of the database and use it later because it's unclear if the cache was atomically updated with the data or not.
Let's dig into these problems and design a proper solution for this.
Bloated database size
If you have 30 categories, each budget month requires about 195 calculated values. That means 5 years worth of data would create about 11,700 values. Some users have ~100 categories so that number could be much higher.
The value is usually an integer which is small in size, but the name is something like a uuid (cd84ebbe-899a-4bee-baee-47633d2239cb) which is 36 chars long. At a minimum it would be 36 bytes in size, so with 11,700 values it produces ~411KB worth of data.
That might not seem huge, but this scales with the number of categories and how many budget months you have.
Let's take a look at some real data. I'll use my file that has about 6 years of data in it. The table name we are interested in is spreadsheet_cells, and we can query the size of it:
% sqlite3 ~/Documents/Actual/user1/db.sqlite
sqlite> SELECT SUM(pgsize), name FROM dbstat WHERE name LIKE '%spreadsheet_cells%' GROUP BY name;
SUM(pgsize) name
----------- ----
1699840 spreadsheet_cells
1503232 sqlite_autoindex_spreadsheet_cells_1The second entry is the index automatically created based on the primary. The values are bytes, so if we sum them together that's a total of ~3.1MB!
Why is database size so important? Since all of your data is local, when you login to a new device it must download all of your data. By keeping the size small it will make it much faster to download your data (in other cases we also upload it).
It's ridiculous to create such bloat only to shave off 1-2 seconds of startup time. The solution here is to move the cache out of the database.
I did realize that we could cut the bloat in half by removing the
PRIMARY KEYconstraint so that sqlite doesn't index on aTEXTcolumn (which takes a lot more space than an integer). There's still a lot of bloat, and it seems dangerous to remove that constraint. A bug in code could accidentally create duplicate rows.
Stale cached values
A more critical problem is that sometimes the cached values in a database get out-of-date. That means when you load the file, your budget will be wrong because it hasn't been recomputed.
On most platforms, it's extremely rare for this to happen. What data changes, it recomputes any dependencies and updates the cache. However, "data changing" and "cache updating" happens in two different transactions, so it's possible for the app the crash in between them.
It's very different for the web. We still use sqlite on the web, but because it lacks any filesystem APIs it isn't automatically persisted. What we do is we persist the entire database binary into IndexedDB, and then use a kind of write-ahead log to efficiently store updates in IndexedDB. Every now and then, we compress the WAL into the stored database binary.
This has worked very well except for one problem: there are major race conditions with cache updating and writing the database binary to IndexedDB. Without going into the boring details, it's possible for Actual to write a version of the db to disk where data has changed but the cache hasn't updated. That means when that file is later loaded, the budget will be using stale values.
The solution here is a flag that indicates if the cache is dirty or not, and if it is dirty to discard it on startup and recompute everything. We will set that flag before doing any db updates, and once we are done updating the db and the cache we turn it off. In the worst case (something fails in the process) the app will just recompute everything on the next startup regardless. We should always favor correctness over speed.
The solution
We could try to improve the current cache, but there's no avoiding the bloat and there is other technical debt leftover from historical decisions. It's time for something new.
I've been thinking about the needs of Actual, and I'm really excited about the potential for a new caching layer. Previously the cache is only available if using the awkward internal spreadsheet APIs (only around for legacy reasons, I'll go through history of them in another post!). Currently there's no way to simply run a query and cache the result.
I'm thinking about it in 3 layers:
* in-memory cache
* persistent cache <-------
* queries/computationsThe persistent cache is what we'll be building today. The in-memory cache would have the same API but wouldn't write the result to disk, which is useful if you want to keep around large amounts of data while using the app and avoid bloating the on-disk size. The queries/computations layer is what actually runs SQL queries and recomputes dependencies.
Properties the persistent cache:
- Key/value storage
- Persists to disk
- Stored separately from the user's database
- Fast
It seems like leveldb would be a good fit for this. It feels like the sqlite3 of key/value databases: it's embeddable, simple (single-process), and fast. What really got me interested is the level project which makes leveldb work across node and the web.
It uses the real leveldb in node as a native dependency, and uses IndexedDB on the web. I'm curious what kind of perf differences the web backend has, or if there any sacrifices in semantics, but for my needs it seems good enough.
Another option is to just use sqlite3 again. To evaluate these options, let's think about the most important metric. It comes down to this: it must be able to read the whole db very fast. We do this on app startup to load the cache. This is most important metric since it impacts app startup time.
Additionally, the size of the database on disk is a factor. Ideally it'd be as compressed as possible. Also, it should not dramatically increase the size of the deployed artifact (bundle, app, etc), or introduce complexity with build/deployment tooling.
Benchmarks
I created some benchmarks to understand the performance of various setups. All code is available in this repo if you want to run them. If there are any improvements, I'd love to hear them.
There are important caveats with these results, so please read the explanations. Do not take the graphs at face value for sqlite3 and leveldb. The most important thing to understand is that these are using the node bindings for each project, so this is not reflective of each project itself. The overhead of the bindings has a large effect on these numbers.
The sqlite3 version uses this table as the key/value store:
CREATE TABLE kv (key TEXT PRIMARY KEY, value TEXT)These code for these benchmarks creates a database and fills it with items with a uuid key and an integer value, and then iterates over all items in the database. The benchmarks measure various aspects of this.
Here are the both implementations that benchmarks run:
Loading all items
The metric we care most about is the speed of reading the whole database. This benchmark creates and load the database, and then measures the time for iterating over all the items.
This is the benchmark for running leveldb, and this is the benchmark for running sqlite.
I was going to run this across various platforms, but while doing this I discovered some serious problems and I've already made my decision. I'll go into that more soon.
Here is the result on macOS 11.1 on a 2015 macbook pro:
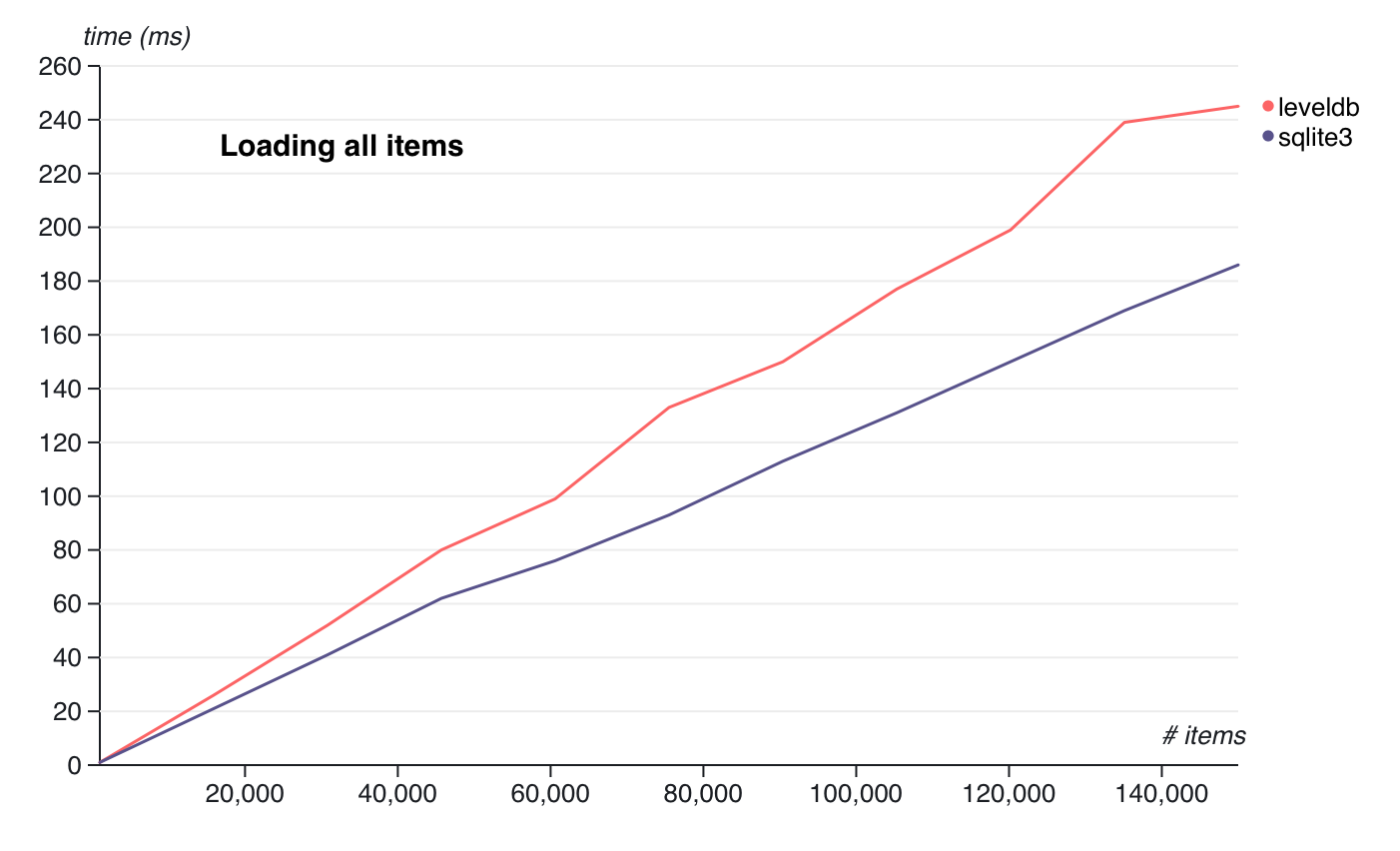
Hm, that's interesting? I would have expected them to be more even, or leveldb to possibly beat sqlite3. Why does sqlite3 have such a clear lead?
Remember, this is not indicative of the projects themselves, this is measuring the node bindings for each project.
Before I explain, let's look at the next benchmark.
Populating the database
Since I have the code, I decided to also measure how long it takes to insert N items into the database.
This is the benchmark for running leveldb, and this is the benchmark for running sqlite.
Results:
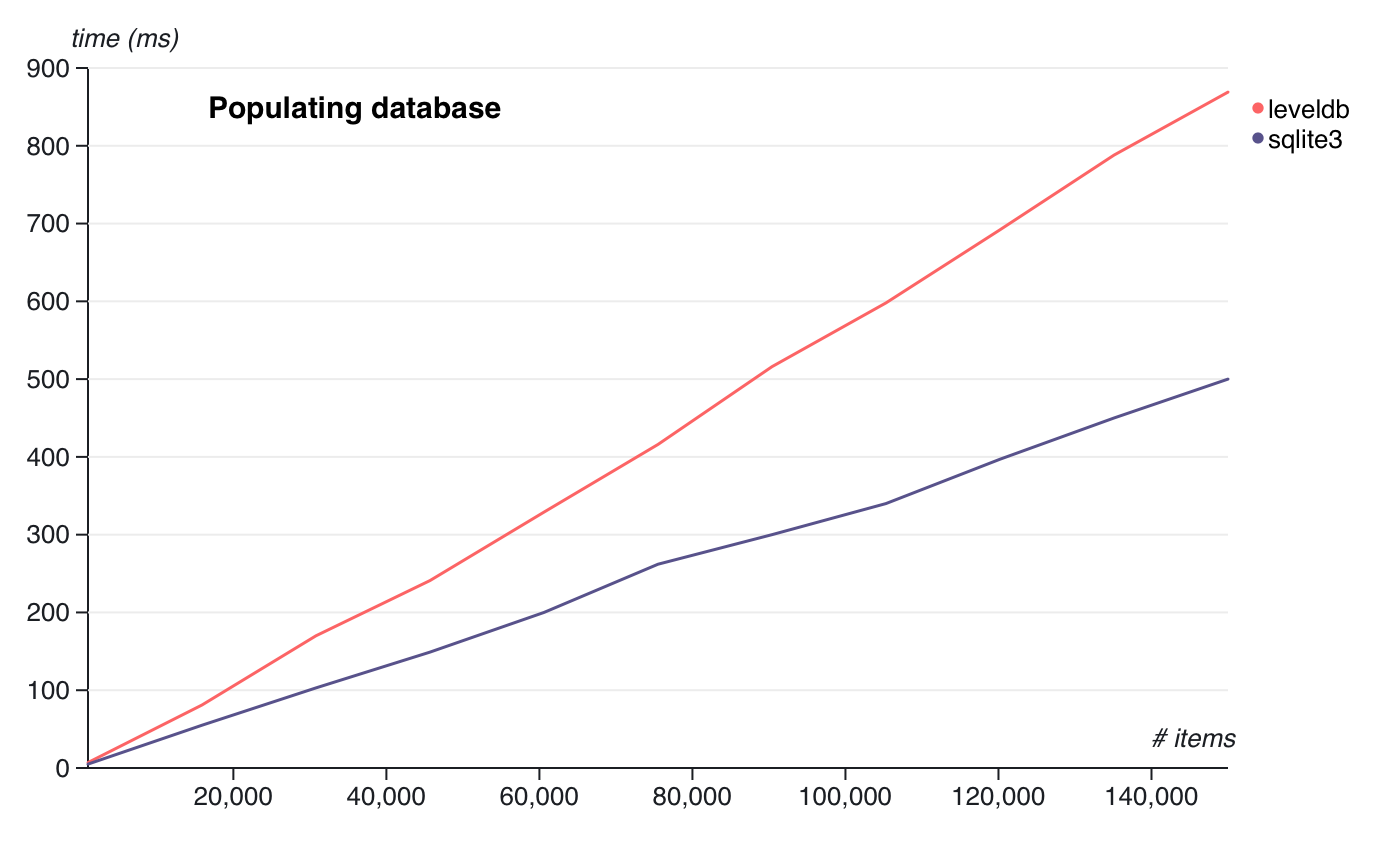
Whoa, our sqlite setup is way faster.
The over-asyncification of node code
How can that be? The reason became clear to me while writing these tests: the leveldb bindings are asynchronous while the sqlite bindings are synchronous. The benchmarks for leveldb were much more annoying to write because of this.
What happens when you call db.del() in level? It queues up a worker which eventually calls database->Del.
That means we've taken leveldb, a super performant database meant to be embedded directly in the process, and added a ton of overhead to it. And for no real gain! And now all the code has to be asynchronous!
We used to have this problem with sqlite, but thank heavens better-sqlite3 came along and provided sane bindings. sqlite is meant to be an in-process database, which means everything can be synchronous. It's actually faster to call it synchronously!
To me, it's a huge problem that the node community always makes everything async by default. Microtasks aren't expensive, except when they add up. And they add up quickly!
I fully expect that leveldb could match or beat sqlite3 in these benchmarks if I wrote them in native code and accessed it synchronously.
However because I can only access it async, this makes leveldb dead on arrival for my use case. Sqlite is plenty fast enough here that I'm going to go with it.
One last benchmark
The level project supports browsers by using an IndexedDB backend instead of leveldb. I had to run my benchmark in browsers just to see the difference in performance.
As expected, IndexedDB is way slower. Here are the results (these are all up-to-date browsers as of June 25, 2021):
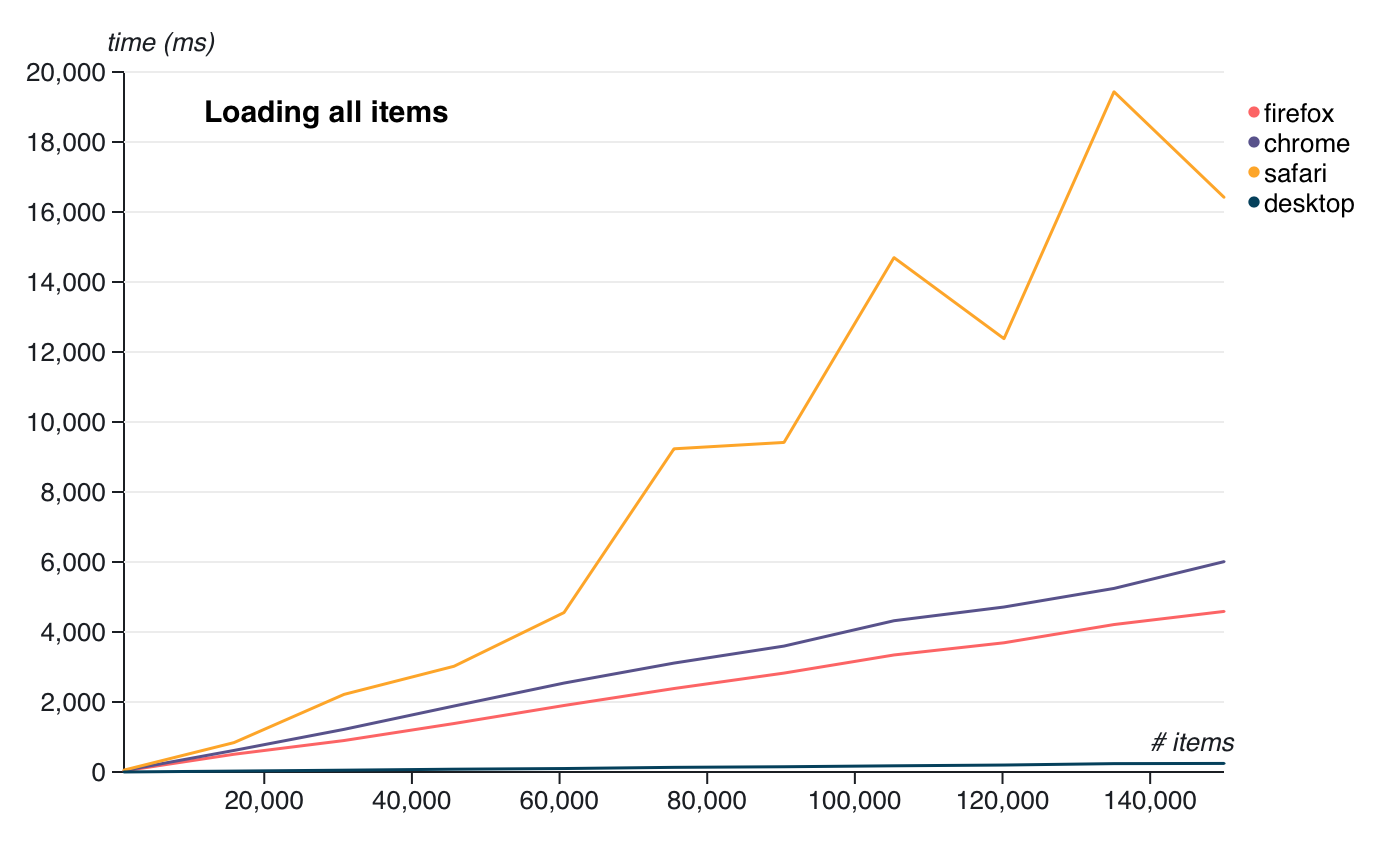
See that little line at the very bottom? That's the native leveldb bindings for comparison. At the max number of items, leveldb took ~245ms while IndexedDB took ~5 seconds in Chrome and Firefox. Safari is wild and takes ~17 seconds.
The really absurd thing about IndexedDB? In Safari and Firefox, it's backed by sqlite, and in Chrome it's backed by leveldb! :clownface: There's no hope for good persistance APIs on the web.
(FWIW, this is measuring level's IndexedDB backend. There may be better ways to batch load data that isn't using, so it might not be 100% IndexedDB fault. But in my experience this isn't surprising)
Conclusion
better-sqlite3 is really a gem and provides raw access to sqlite3's great performance. Even though it feels weird to only store key/value items in it, it will provide plenty of performance for my needs.
Unfortunately, I can't use better-sqlite3 on the web. I will need to write a custom backend there, but because I only need simple key/value storage it shouldn't be too hard. I will likely optimize how items are written into the db to reduce the amount of reads on startup (see how slow reads are in Safari above).
(After writing the above paragraph, I launched into an investigation of getting sqlite3 working on the web. The results are quite astonishing and I'll be releasing my solution soon.)
In the coming weeks I will replace the entire caching strategy in Actual to use a separate sqlite database that only stays local to your computer. Whenever you login on a fresh device, it will compute everything fresh and cache it locally.
from Hacker News https://ift.tt/3BGEEil
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.