Ruby Outperforms C: Breaking the Catch-22
Ruby is an expressive, and fun language to write. It helps us get our job done quickly by allowing us to easily get our thoughts written down as executable code. That said, sometimes the code we write doesn’t perform as well as we would like. In those circumstances, one common solution in both Ruby and Python has been to rewrite the slow code as C extensions (or more recently Rust extensions). This creates new problems, namely instead of having one code base, you now have two: a Ruby code base and a C/Rust code base. The C language comes equipped with many footguns as standard features, and as a library author now you must become familiar with them.
YJIT’s ability to improve performance by adapting to run-time behavior can increase the speed of our code in a way that dropping down to C can’t. As such, I think we should reconsider the common wisdom that “rewriting our Ruby in C” is the ideal path to performance optimization, and take a serious look at “rewriting our C in Ruby” instead.
In this post I’d like to present one data point in favor of maintaining a pure Ruby codebase, and then discuss some challenges and downsides of writing native extensions. Finally we’ll look at YJIT optimizations and why they don’t work as well with native code in the mix.
Parsing GraphQL
Shopify is a big consumer of GraphQL. As such, it’s important that our GraphQL endpoints have great performance. Some of our endpoints accept GraphQL queries that approach 80kb, so being able to parse a query of that size quickly is very important.
We use the GraphQL Ruby gem in production. The GraphQL Ruby implementation can be thought of in 3 parts:
- A lexer which breaks the GraphQL query in to tokens.
- A parser which uses the GraphQL grammar to produce an Abstract Syntax Tree (or AST)
- Finally an interpreter which walks the AST and actually executes the query
Today we’re looking at the first two points, the lexer and the parser. We’ll be benchmarking the parser, but since the parser depends on the lexer, the lexer’s performance also impacts parsing time.
GraphQL’s lexer uses Ruby’s built-in string scanner called StringScanner. The String Scanner class helps you break a string in to tokens using regular expressions.
For parsing, the GraphQL gem uses another gem that ships with Ruby called racc. Racc is a gem that generates parsers. In other words, you write a grammar then use racc to convert the grammar in to a parser. The parser that Racc generates uses a state machine with a lookup table which drives parser execution. The main parser routine is a while loop implemented in C that calls out to Ruby asking for the next token, then uses the returned token to look up a handler of “user code” which has been defined in the parser. The parser will choose an action, either to “shift” or “reduce”, and either one of these actions can potentially call from C back in to Ruby.
In other words, we have a tight loop that makes many Ruby to C to Ruby calls. YJIT (as well as other JIT compilers) have a hard time optimizing these types of calls.
Outperforming a C extension
An interesting feature of Racc is that it actually ships with a pure Ruby implementation of the parser runtime. That means we can compare the C extension and the Ruby implementation without changing the implementation of GraphQL.
Here is the benchmark I’ll be using:
require "benchmark/ips"
require "optparse"
Benchmark.ips do |x|
doc = nil
parser = OptionParser.new
parser.on('--cext', 'Use GraphQL C extension') { require "graphql/c_parser" }
parser.on('--ruby-racc', 'Use Ruby version of Racc') { $LOAD_PATH << "lib" }
parser.on('--tinygql', 'Include TinyGQL') {
x.report("tinygql") { TinyGQL.parse(doc) }
}
parser.parse!
# Make sure require goes after LOAD_PATH manipulation
require "graphql"
require "tinygql"
doc = ARGF.read
x.report("graphql") { GraphQL.parse(doc) }
end
The test GraphQL file can be found in this repository. I’m using an edge version of Ruby: ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) [arm64-darwin22].
We can’t load the pure Ruby implementation of Racc and the C implementation at the same time, so we’ll have to compare this in different runs. First lets get a baseline speed of GraphQL, with everything “default”. This means we’ll be using the Racc C extension, which was compiled with the same optimizations as Ruby (in my case -O3):
$ ruby -v graphql-bench.rb negotiate.gql
Warming up --------------------------------------
graphql 4.000 i/100ms
Calculating -------------------------------------
graphql 40.474 (± 0.0%) i/s - 204.000 in 5.040398s
With default settings, GraphQL can parse this file a little over 40 times per second. Lets compare with the pure Ruby implementation of Racc:
$ ruby -v graphql-bench.rb --ruby-racc negotiate.gql
ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) [arm64-darwin22]
Warming up --------------------------------------
graphql 2.000 i/100ms
Calculating -------------------------------------
graphql 23.520 (± 0.0%) i/s - 118.000 in 5.018555s
Indeed, the Ruby implementation of Racc is slower than the C implementation. We weren’t using YJIT though, so what happens if we try the pure Ruby version of Racc, but also enable YJIT?
$ ruby --jit -v graphql-bench.rb --ruby-racc negotiate.gql
ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) +YJIT [arm64-darwin22]
Warming up --------------------------------------
graphql 3.000 i/100ms
Calculating -------------------------------------
graphql 45.217 (± 2.2%) i/s - 228.000 in 5.044157s
If we enable YJIT and use the pure Ruby implementation of Racc, we achieve 45 iterations per second, 10% faster than the C implementation of Racc! From this we can see it is quite possible for YJIT to achieve speeds that are faster than a C extension. However, we should also test the C extension + YJIT:
$ ruby --jit -v graphql-bench.rb negotiate.gql
ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) +YJIT [arm64-darwin22]
Warming up --------------------------------------
graphql 4.000 i/100ms
Calculating -------------------------------------
graphql 56.013 (± 0.0%) i/s - 284.000 in 5.070281s
This is the fastest of them all at 56 iterations per second. We see speed improvements from YJIT as well as from the Racc C extension. One thing we should note though is the ratio of the speed up. YJIT was able to speed up our pure Ruby implementation by nearly 200%, but combining YJIT and the C extension only sped up by 40%.
Improving our Performance: Lets Rewrite!
Conventional wisdom in the Ruby community has typically been “if it’s too slow, rewrite in C”. GraphQL is no exception to this. In fact, there is a gem you can install with the GraphQL parser completely rewritten in C. But if rewriting is on the table, is it possible to write an entire parser in pure Ruby that can outpace a C extension? In order to test this, I wrote a GraphQL parser in pure Ruby called TinyGQL and you can check it out here. TinyGQL is a simple, hand written recursive descent parser. It does not use a parser generator. So, can it beat a C extension? Lets look at the benchmark results to find out:
$ ruby -v graphql-bench.rb --cext --tinygql negotiate.gql
ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) [arm64-darwin22]
Warming up --------------------------------------
tinygql 22.000 i/100ms
graphql 30.000 i/100ms
Calculating -------------------------------------
tinygql 245.313 (± 0.8%) i/s - 1.232k in 5.022452s
graphql 280.977 (± 0.4%) i/s - 1.410k in 5.018244s
Comparison:
graphql: 281.0 i/s
tinygql: 245.3 i/s - 1.15x slower
TinyGQL processes this document at 245 iterations per second (about 6 times faster than the baseline!), but from the benchmark output it looks like it cannot compete with the GraphQL C extension. YJIT was able to speed up the pure Ruby implementation of GraphQL by nearly 2x, maybe it could do the same for TinyGQL? Lets try the benchmark one more time with YJIT:
$ ruby --jit -v graphql-bench.rb --cext --tinygql negotiate.gql
ruby 3.3.0dev (2023-08-14T15:48:39Z master 52837fcec2) +YJIT [arm64-darwin22]
Warming up --------------------------------------
tinygql 43.000 i/100ms
graphql 33.000 i/100ms
Calculating -------------------------------------
tinygql 456.232 (± 0.9%) i/s - 2.322k in 5.089848s
graphql 349.743 (± 0.6%) i/s - 1.749k in 5.001045s
Comparison:
tinygql: 456.2 i/s
graphql: 349.7 i/s - 1.30x slower
Indeed, YJIT was able to speed up TinyGQL by nearly 2x where the C extension only saw a 24% speedup. The net result is that with YJIT enabled, the pure Ruby TinyGQL achieves 456 iterations per second, outperforming the GraphQL C extension by 30%!
Here is a graph summarizing the speedups with the different variations listed above:
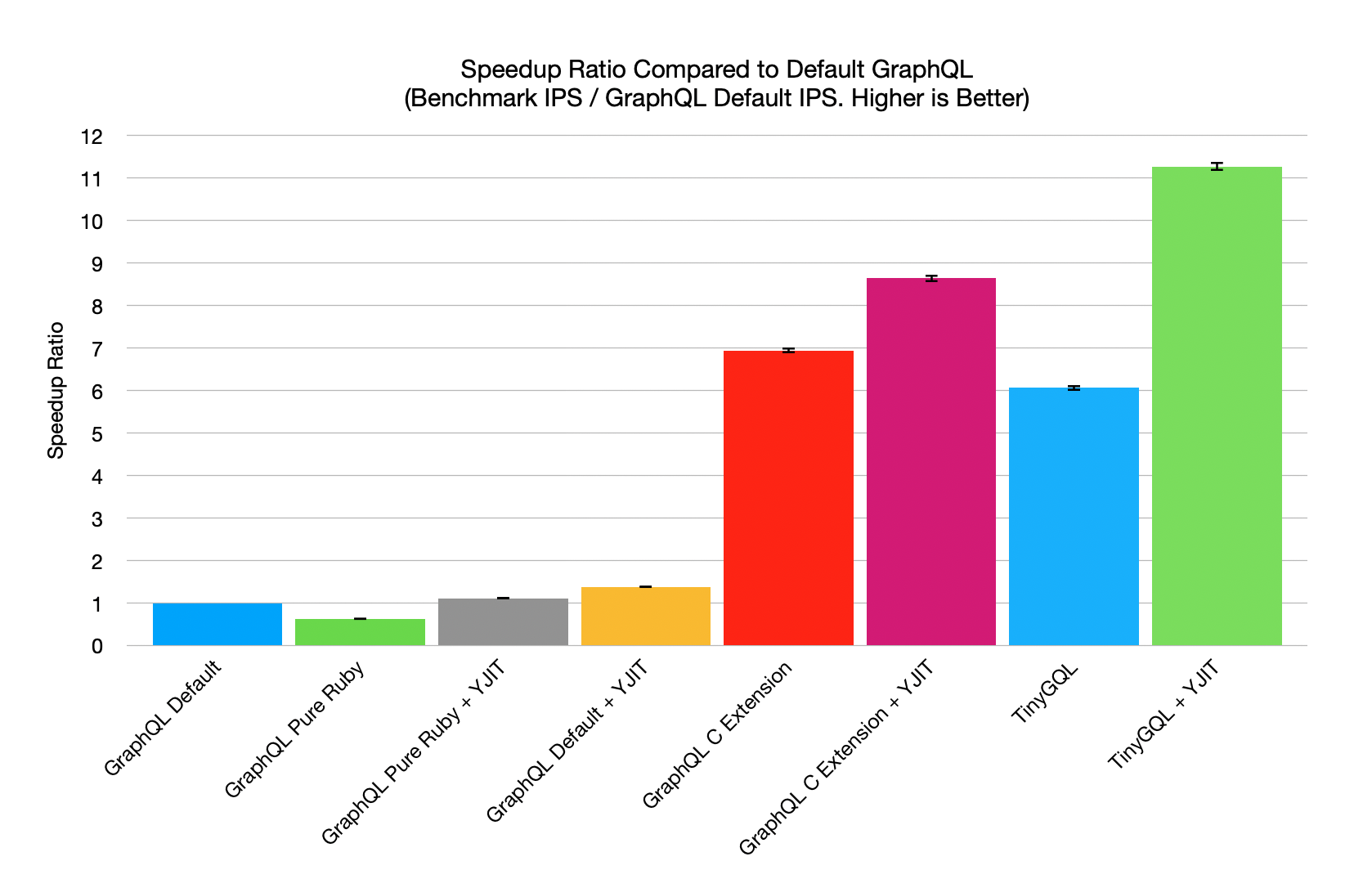
The graph shows speedups relative to the default GraphQL configuration. Each bar shows the default GraphQL iterations per second
I think that these results make a compelling case for rewriting our C in Ruby!
What’s so hard about C functions?
I wanted to end this post on the previous line because I really really want to encourage people to write more Ruby. But I also want people to know why they should write more Ruby as well. For me, it’s not enough to know I should do something, I really need to know “why” (this got me in to a lot of trouble as a kid).
In this case, we’re seeing vastly different relative speed increases and they depend on the “type” of code that we’re trying to optimize. I think there are probably 2 main contributing factors to the phenomenon.
First, when a JIT is optimizing a function, it tries to “cheat” to get ahead. Fundamentally, the JIT compiler is converting our Ruby code to native machine code. However, the native function that we’re trying to call is completely opaque to the JIT compiler. It cannot know what the native function will do, so it must take a conservative approach and “act like the bytecode interpreter” by reproducing exactly what the interpreter would have done. In other words, calling a C function won’t let us cheat.
The second problem has to do with types the JIT detects at runtime. When the JIT compiler is compiling a function, it has the opportunity to look at the type of the parameters being passed to a function and optimize any subsequent code in that function that uses those parameters. Native functions cannot take advantage of the type information that the JIT compiler was able to collect and that means they are missing out on any optimization opportunities that could be presented with this knowledge.
Lets take a look at a concrete example of how YJIT can use runtime type information to its advantage.
Reading Instance Variables, Ruby code vs C extension
When the JIT compiler generates machine code, it’s able to use that machine code as a sort of “cache”. It can cache values (based on runtime types) in the machine code itself and use them when the machine code executes.
Lets look at an example where we read two instance variables, then put them in an array in Ruby and C. In Ruby, we’d implement the method like this:
def make_array
[@a, @b]
end
In a C extension, the same method would look like this:
static VALUE
make_array(VALUE self)
{
VALUE a = rb_iv_get(self, "@a");
VALUE b = rb_iv_get(self, "@b");
return rb_ary_new_from_args(2, a, b);
}
Just so we can understand how a JIT can outperform this C extension, I want to focus only on the two instance variable reads.
As an implementation detail of Ruby itself, the place where instance variables are stored is different depending on the type of the object. For example, Ruby stores instance variables on an Array in a different location than it does an Object. However, neither the Ruby code nor the C code know the type of object they will read from when each method is compiled to bytecode or machine code. But a JIT compiler is able to examine the type at runtime and generate machine code “on the fly” (or “Just In Time”) that is customized for that particular type.
Lets look at the machine code YJIT generates for the first instance variable read on @a:
== BLOCK 1/4, ISEQ RANGE [0,3), 36 bytes ======================
# Insn: 0000 getinstancevariable (stack_size: 0)
0x5562fb831023: mov rax, qword ptr [r13 + 0x18]
# guard object is heap
0x5562fb831027: test al, 7
0x5562fb83102a: jne 0x5562fb833080
0x5562fb831030: test rax, rax
0x5562fb831033: je 0x5562fb833080
# guard shape
0x5562fb831039: cmp dword ptr [rax + 4], 0x18
0x5562fb83103d: jne 0x5562fb833062
# reg_temps: 00000000 -> 00000001
0x5562fb831043: mov rsi, qword ptr [rax + 0x10]
YJIT generates machine code contextually, and compiles the make_array method within the context of the object upon which that method was called (also known as “the receiver” or “self”). The JIT compiler peeks at the type of self before generating machine code, and sees that self is a regular “heap type” Ruby object. It then generates machine code to ensure that the “type of thing” it saw at compile time (the time it generated the machine code) is the same “type of thing” we see at runtime (the time the machine code executes). The JIT saw that self was a “heap” type object, thus we have a chunk of “guard” code that ensures the runtime object “is a heap” object. Next we have a chunk of code that ensures that the object is the same shape. At compile time, the JIT saw that the object had a shape ID of 0x18 and it embedded that ID directly in the machine code that ensures the runtime object has the same shape. If both of these guard tests pass, then the machine code will actually read the instance variable, which is the final mov instruction. The location of the instance variable is cached in the machine code itself: 0x10 away from the value stored in the rax register. You can think of the cache key as “the type of object and the shape ID”, and the guard code as “checking that the cache key is correct”.
Conceptually, this isn’t too different from the work that rb_iv_get must do. It also must check that the type is a heap object, and then do something differently depending on the type. However, every time we call rb_iv_get, the function must figure out the instance variable location because it has no cache. This is one way that the JIT compiler can generate code that is faster than a C function call, by using machine code as a cache.
Lets look at the machine code YJIT generates for the second instance variable read on @b:
== BLOCK 3/4, ISEQ RANGE [3,6), 18 bytes ======================
# regenerate_branch
# Insn: 0003 getinstancevariable (stack_size: 1)
# regenerate_branch
0x55cb5db5f047: mov rax, qword ptr [r13 + 0x18]
# guard shape
0x55cb5db5f04b: cmp dword ptr [rax + 4], 0x18
0x55cb5db5f04f: jne 0x55cb5db610ba
# reg_temps: 00000001 -> 00000011
0x55cb5db5f055: mov rdi, qword ptr [rax + 0x18]
The machine code for reading @b is actually shorter than the machine code for reading @a! Why is this? The reason is because YJIT is able to learn about types in the system. In order to read the @a instance variable, the JIT has already ensured that the type of object we’re reading from is a heap type Ruby object. Since the JIT was able to “learn” this type, it didn’t emit a second guard clause. We’ve already checked the cache key, so there’s no reason to do it again. In other words, the JIT is able to amortize the cost of checking the type across multiple instance variable reads.
The C implementation cannot do this and must check the type every time rb_iv_get is called. There is no way to amortize this “learned” information across calls, and the C implementation is forced to check the type on every call. This type of “machine learning” allows the JIT compiler to gain even more speed over the C extension.
(Astute readers will notice that the same “shape guard” is repeated. This is something that could be eliminated, it just hasn’t been done yet. A great opportunity for contribution!)
These types of optimizations don’t just apply to fetching instance variables, they apply to function calls as well. Anywhere in your program that the JIT can use this runtime information, it will use the information to generate more optimal machine code.
Unfortunately, when the JIT generates code that must cross the “Ruby to Native” boundary, much of this runtime knowledge must be thrown away. The JIT cannot know what the native code will do to parameters (possibly mutate them), it cannot know what type of Ruby object will be returned, if the native code will look at the stack, or if it will raise an exception, etc. Thus the JIT is forced to have a conservative approach when dealing with native code, essentially forgetting much of what it had learned, and falling back to the most conservative implementation possible. Since the JIT is forced to “do whatever the Ruby VM would have done”, it makes sense that calling native functions can hamper the JIT’s performance. It also explains why we see more drastic performance increases when using YJIT with TinyGQL versus using YJIT with the GraphQL C extension. Since TinyGQL is 100% Ruby, the JIT isn’t forced to “forget” anything and can generate more performant machine code.
Conclusion
I hope that this post was able to give folks a closer look into how a JIT compiler can outperform a C extension, and more importantly, encourage people to write more Ruby! It would be really great to see TinyGQL’s parser used in the GraphQL gem so that everyone can get this performance benefit without upgrading their applications.
Have a great day!
from Hacker News https://ift.tt/Pe5SX4b
No comments:
Post a Comment
Note: Only a member of this blog may post a comment.